基础概念与任务#
Q抽取式摘要和生成式摘要存在哪些问题#
抽取式摘要在语法、信息保真度上有一定的保证,在抽取速度、复杂度上面也有一定的优势。但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。
生成式摘要优点是相比于抽取式而言用词更加灵活,因为所产生的词可能从未在原文中出现过。但存在以下问题:
事实一致性问题:可能产生于原文不符的事实错误#
可控性挑战:难以精确控制摘要的风格,长度和重点#
长文本摘要生成难度大。对于机器翻译来说,NLG的输入和输出的语素长度大致都在一个量级上,因此NLG在其之上的效果较好。但是对摘要来说,源文本的长度与目标文本的长度通常相差很大,此时就需要encoder很好的将文档的信息总结归纳并传递给decoder,decoder需要完全理解并生成句子。#
抽取式摘要更适合于新闻报道、法律文件等需要高度忠实原文的场合。而生成式摘要适合于博客文章、社交媒体帖子等需要流畅表达的场合。
文本表示方法#
QWord2Vec 的核心思想?两种模型是什么?#
核心思想:#
基于“分布假设”(一个词的含义由其周围词决定),通过神经网络学习稠密词向量,使语义相近的词在向量空间中距离更近。
两种模型:#
- CBOW:输入上下文词,预测中间目标词。
Skip-gram:输入中心词,预测其上下文词。
Q什么是上下文相关词表示?与静态词向量有何区别?#
上下文相关词表示:#
词向量随其所在句子的上下文动态变化(如 “苹果” 在 “吃苹果” 和 “苹果公司” 中表示不同),能捕捉多义性和语境差异。
区别:#
静态词向量(如 Word2Vec)为每个词分配固定向量,无法区分多义词;
上下文相关词表示能动态捕捉词义变化。
传统序列模型#
Q什么是词嵌入(Word Embedding)?#
词向量是用于表示单词意义的向量,也可以看作词的特征向量。将词映射到向量的技术就称为词嵌入(Word Embedding)。
Q什么是RNN?#
循环神经网络(Recurrent Neural Network,RNN)是一种具有环路结构的神经网络,通过环路数据可以在层内循环。将时序数据输入层中,相应的会输出。
各个时刻的RNN层接收传给该层的输入和前一个时刻RNN层的输出,据此计算当前时刻RNN层的输出:
QRNN 与前馈神经网络的主要区别是什么?适用于什么场景?#
区别:RNN 通过隐藏状态保存历史信息,能处理时序数据;前馈网络无记忆,仅能处理静态数据。
场景:自然语言处理(文本生成、翻译)、时间序列预测(股价、天气)。
QRNN中为什么会出现梯度消失?#
基于链式法则,在反向传播计算梯度时,会导致激活函数导数的累乘,如果取tanh或sigmoid函数作为激活函数的话,由于导数值恒小于1,结果就会越来越小。随着时间序列的不断深入,累乘效应就会导致梯度越来越小直到接近于0,从而出现“梯度消失”。
实际使用中,RNN会优先选择tanh函数,原因是tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
Q如何解决RNN中的梯度消失问题?#
- 选取更好的激活函数,如Relu激活函数。ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。但恒为1的导数又容易导致“梯度爆炸”,通过设定合适的阈值,可以解决这个问题。
- 加入BN层:其优点是加速收敛,控制过拟合,可以少用或不用Dropout;降低对权重初始值的敏感度,且能允许使用较大的学习率。
- 改变网络结构:如LSTM结构可以有效解决这个问题。
QLSTM 如何解决 RNN 的长期依赖问题?#
LSTM 引入记忆单元(Memory Cell)和三个门控机制(遗忘门、输入门、输出门):
- 遗忘门:控制忘记多少历史信息。
- 输入门:控制存入多少新信息到记忆单元。
- 输出门:控制从记忆单元读取多少信息作为当前隐藏状态。
记忆单元为梯度提供稳定传播路径,缓解梯度消失,从而捕捉长期依赖。
QGRU 与 LSTM 的区别是什么?#
GRU 简化了 LSTM 的结构,取消独立记忆单元,仅保留两个门(重置门,更新门):
- 重置门:控制上一时刻的隐藏状态,对当前候选隐藏状态的影响程度。
- 更新门:控制当前隐藏状态中,上一时刻隐藏状态和候选隐藏状态间的比重。
优势:参数更少,训练效率更高;在多数任务中性能接近 LSTM。
Seq2Seq 与 Attention 机制#
QSeq2Seq 模型结构?有什么缺陷?#
结构:#
由编码器(Encoder)和解码器(Decoder)组成。
编码器一般使用双向RNN等模型,将输入序列压缩为固定长度的上下文向量。
解码器可基于单向RNN等模型,并结合编码器所输出的上下文向量,生成目标序列。
核心问题:#
固定长度的上下文向量难以承载长序列信息,容易导致信息丢失;
训练过程无法并行,效率低。
QAttention 机制的工作原理是什么?#
Atttention本质是在解码器在生成序列时,不再仅依靠编码器输出的固定长度的上下文向量,而是动态计算与编码器各时间步隐藏状态的相关性(注意力权重),并加权求和得到上下文向量,实现 “有选择地关注” 输入序列的关键信息。步骤包括:
- 计算相关性(评分函数:点积、通用点积、拼接)。
- 归一化得到注意力权重(Softmax)。
- 加权求和得到上下文向量。
Transformer 模型#
QTransformer 的核心创新是什么?与 RNN 相比有何优势?#
核心创新:#
- 完全基于自注意力机制建模序列依赖,摒弃 RNN 的循环结构;
- 使用位置编码注入位置信息;
- 多头注意力从不同子空间捕捉多种语义关系。
优势:#
- 支持并行计算,训练效率更高;
- 通过多头注意力捕捉多种语义关系,建模能力更强;
- 直接建模任意位置的依赖,增强长依赖建模能力;
- 易于堆叠深层网络。
QTransformer 的编码器和解码器结构分别是什么?#
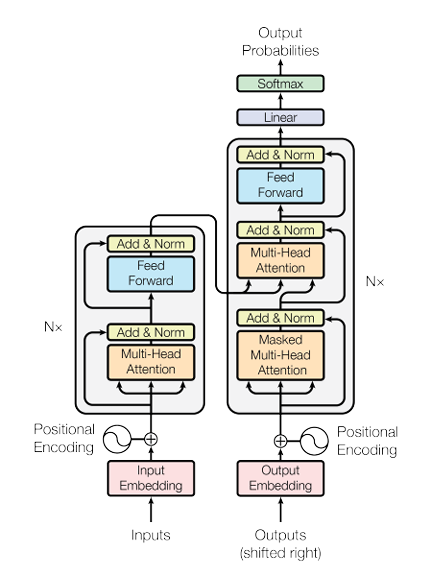
编码器:#
由 N 个编码器层堆叠而成,每个层包含:
- 多头自注意力子层(捕捉输入序列内部依赖)。
- 前馈网络子层(对每个位置独立映射,增加非线性能力)。
- 残差连接和层归一化(稳定训练)。
解码器:#
由 N 个解码器层堆叠而成,每个层包含:
- 掩码多头自注意力子层(防止关注未来信息)。
- 编码器-解码器注意力子层(解码器在生成每个目标词时,动态访问编码器对原始输入序列的全局表示,选择最相关的信息)。
- 前馈网络子层。
- 残差连接和层归一化。
QTransformer 中位置编码的作用和实现方式是什么?#
作用:#
Transformer 无循环结构。自注意力机制中序列中每个token并行计算,获取到与序列中其他token之间的相关性,无法捕捉到序列相对位置关系,因此需通过位置编码注入词的位置信息,使模型感知序列顺序。
实现方式:#
使用正弦和余弦函数生成位置向量,偶数维用正弦,奇数维用余弦。
QTransformer中自注意层计算公式(新增问题)#
计算公式如下:
- Query: 表示当前词的用于发起注意力匹配的向量
- Key: 表示序列中每个位置的内容标识,用于与 Query 进行匹配
- Value: 表示该位置携带的信息,用于加权汇总得到新的表示
- d_k: key向量的维度。高维空间中,点积的数值可能过大,会影响 softmax 的稳定性,因此在实际计算中对结果进行了缩放
预训练模型#
QGPT的结构和预训练目标是什么?#
结构:#
基于 Transformer 解码器做了精简调整,移除了编码器和解码器注意力子层(因为模型中不存在编码器)仅保留自注意力和前馈网络子层,堆叠多层。
预训练目标:#
自回归语言建模(给定前文预测下一个词),学习语言统计规律、上下文依赖和语义信息。
QBERT的结构和预训练目标是什么?#
结构:#
基于 Transformer 编码器,实现双向语言建模,能同时融合左右上下文信息。
预训练目标:#
掩码语言模型(MLM):随机遮盖 15% 的词,预测被遮盖的词。
下一句预测(NSP):判断两个句子是否为连续的上下文,捕捉句间关系,以学习句间的语义和逻辑关系。
QT5的结构和预训练目标是什么?#
结构:#
基于完整 Encoder-Decoder Transformer,编码器将输入文本序列编码成上下文表示,解码器根据编码器输出生成目标文本序列。
输入任务描述 + 原始文本,输出目标文本(如翻译、摘要、问答)。统一任务为文本到文本(text-to-text)形式,方便多任务训练。
预训练目标:#
填空式文本生成:随机掩盖输入文本的连续片段,用特殊标记替换,模型学习生成被遮挡的文本片段。
Q预训练模型的 “预训练 + 微调” 范式是什么?#
预训练:#
在海量通用语料上训练通用语言模型,学习通用表示能力(词汇、语法、语义、上下文关系)。
微调:#
在下游特定任务上(如分类、问答),用少量标注数据进一步训练模型。调整模型参数,适配特定任务。
评估指标#
QNLP 任务中常用的评估指标有哪些?#
分类任务:准确率、精确率(查准率,找出来的正样本对了多少)、召回率(查全率、正样本有多少被找出来)、F1分数(精确率和召回率调和平均)。#
机器翻译:BLEU(n-gram 精确匹配评分)。#
文本摘要:ROUGE(召回为主,衡量生成摘要与参考摘要重叠程度)。#
Q介绍一下 BLEU 指标#
BLEU(Bilingual Evaluation Understudy)是一种衡量机器翻译质量的常用指标,通过比较机器译文和参考译文中的 n-gram(通常是1到4个词)来评估翻译的准确性。BLEU 的得分介于 0 到 1 之间,得分越高,表示机器翻译质量越好。
BLEU 有两个关键组成部分:
n-gram :统计机器翻译结果中出现在参考翻译中的n-gram的比例。#
简洁性惩罚(Brevity Penalty):防止模型通过生成极短的句子来获得高n-gram精度(例如只翻译几个高频词)。#
Q介绍一下ROUGE指标#
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)将待审摘要和参考摘要的 n-gram 共现统计量作为评价依据。
ROUGE-N:#
ROUGE-1:基于单词 unigram 重叠。反映基础词汇覆盖率。
ROUGE-2:基于 bigram 重叠。衡量局部短语覆盖率。
生成文本与参考文本 n-gram 的重叠数量 / 参考文本 n-gram 总数。
ROUGE-L:#
计算最长公共子序列的匹配率,L是LCS(Longest Common Subsequence)的首字母,LCS(R,C) 表示参考文本R与生成文本C的最长公共子序列长度。如果两个句子包含的最长公共子序列越长,说明两个句子越相似。能捕捉长距离语义/结构匹配,兼顾短句和长文本连贯性。
QBLEU和ROUGE有什么不同?#
BLEU 主要用于机器翻译任务,关注生成文本与参考文本的精确 n-gram 匹配,精确率为主。BLEU 无法评估翻译的语义、流畅性、语法正确性或句法结构。
ROUGE 主要用于摘要、文本重述等生成任务,关注生成文本是否包含参考文本中的关键信息,召回率为主。
Q分类任务怎么处理类别不平衡?#
处理类别不平衡需要系统化方案。评估指标是前提,必须选用F1、PR-AUC等。算法层面,代价敏感学习是当下首选算法,它比简单重采样更稳健。重采样技术(如SMOTE)可以作为补充,但需警惕过拟合,常与Tomek Links等清洗方法联用。集成学习则应选择内置代价敏感或动态加权机制的先进框架。最终,所有技术选择都应与业务损失函数对齐。