项目周期与分工#
- 2人团队,6周
- 需求分析&设计:1周
- 文档导入(导入节点):2周
- 检索服务(查询节点):1周
- 问答服务(SSE&前端):1周
- 测试&优化&上线:1周
Q第一阶段:需求分析与架构设计(Week 1)#
Q第二阶段:数据采集模块开发(Week 2-3)#
Q第三阶段:知识库检索模块开发(Week 4)#
Q第四阶段:RAG问答与前端开发(Week 5)#
Q第五阶段:测试与上线(Week 6)#
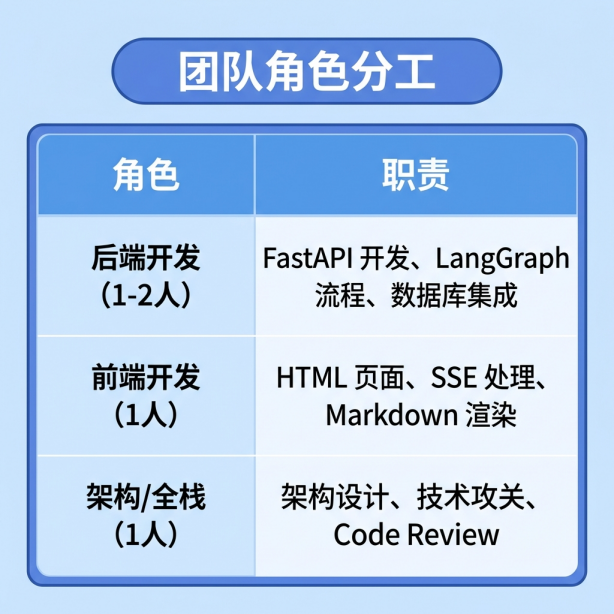
Q团队分工建议#
项目概述#
Q项目背景#
业务场景#
为企业客户提供一站式智能知识管理解决方案,涵盖文档自动化解析、多模态内容提取、语义检索、MCP检索等功能。
核心价值:#
- 文档智能导入:支持 PDF/Markdown 文档自动解析、图片描述提取、文档分割、向量化存储
- 语义检索:基于 BGE-M3 混合向量的语义检索,兼顾语义理解和精确匹配
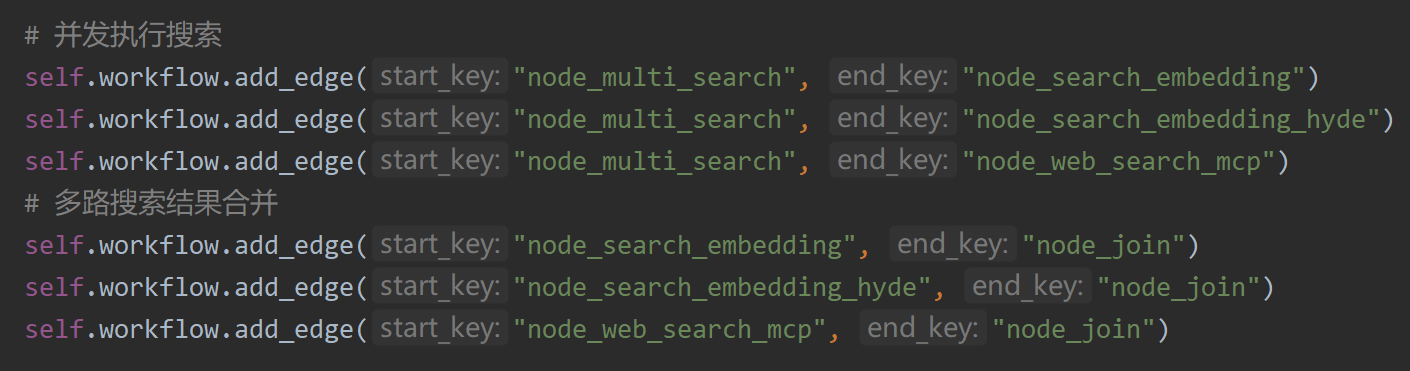
- 多路检索融合:向量检索、HyDE 假设文档检索、MCP网络搜索三路并行
- 流式响应:SSE 实时推送查询进度和答案生成过程
Q技术选型#
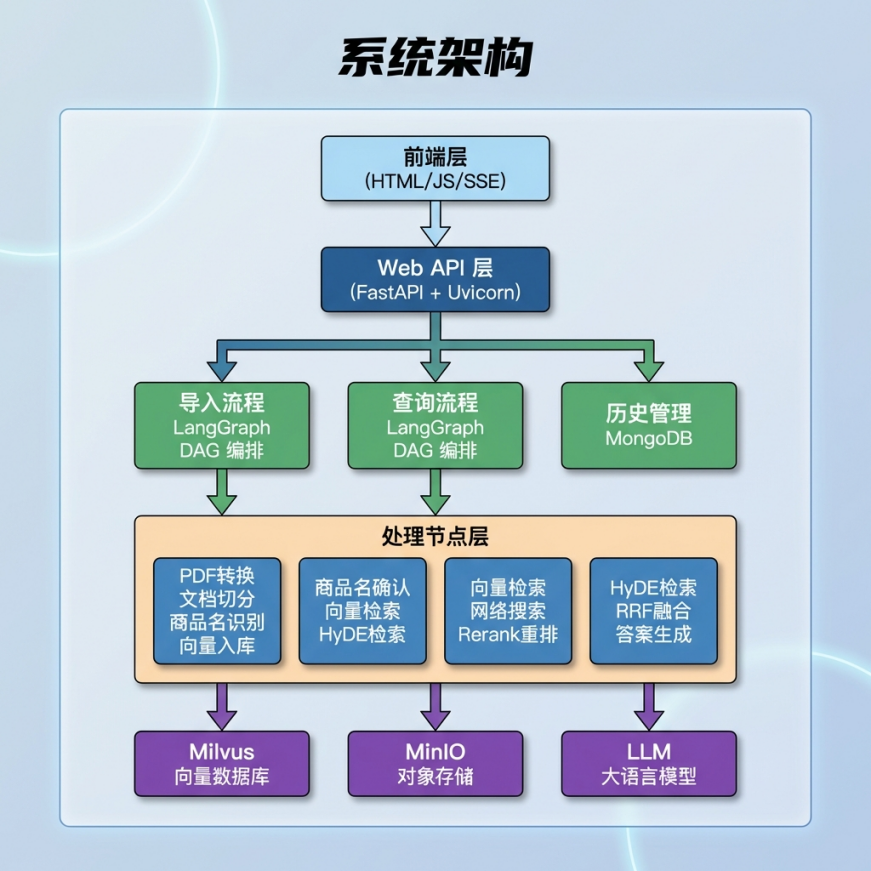
整体架构设计#
Q系统架构图#
QRAG工作机制#
核心模块详解#
Q文档导入(import)#
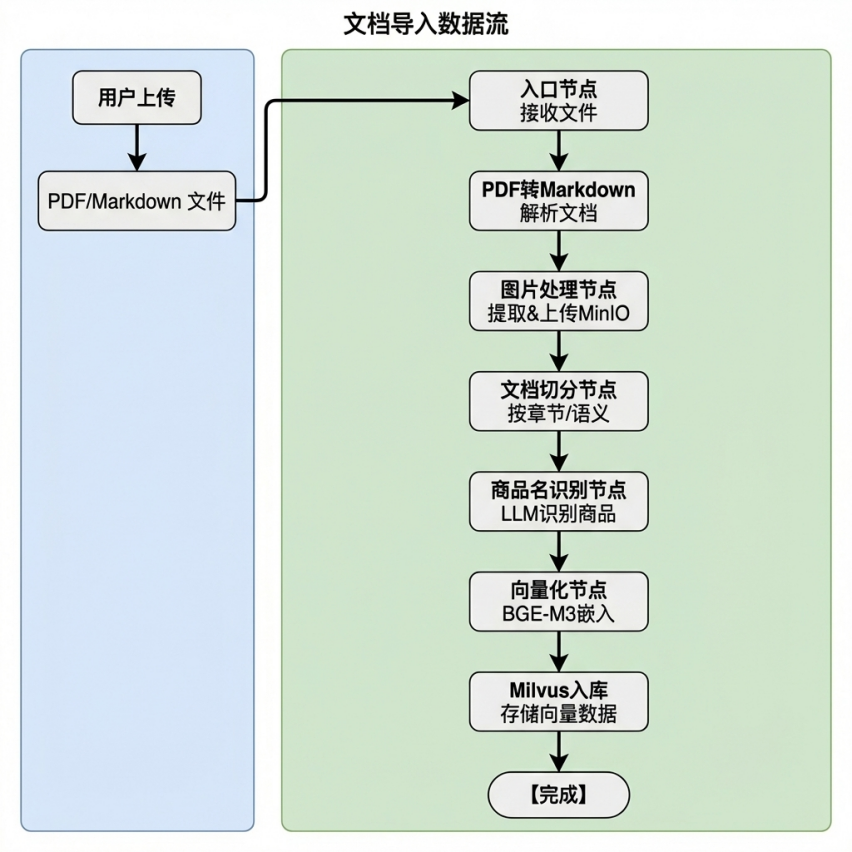
文档摄入是将原始文档转化为可检索向量的核心环节,整个流程分为七个阶段。
第一阶段(文档类型判断):#
通过文件扩展名判断文档类型,从而进入不同的条件边,执行分支流程
第二阶段(PDF转Markdown):#
接收用户上传的PDF文件路径#
使用MinerU工具将PDF解析为Markdown格式#
返回解析后的MD文件供下游使用#
第三阶段(Markdown图片处理):#
扫描MD文件中的所有图片引用#
提取每张图片的上下文(标题、上文、下文)#
使用VLM生成图片描述摘要#
上传图片到MinIO对象存储#
替换MD中的本地图片路径为远程URL和描述#
第四阶段(文档切分):#
根据Markdown标题层级切分文档(1-6级标题)#
对过长章节进行递归切分#
对过短章节进行合并#
添加元数据(title, parent_title, file_title, part)#
第五阶段(商品名识别):#
从文档前K个chunk中提取上下文#
使用LLM识别商品名称#
将商品名向量化(BGE-M3)#
存储到Milvus商品名集合#
回填item_name到所有chunks#
第六阶段(批量嵌入节点):#
对所有chunks进行批量向量化#
拼接 item_name + content 作为嵌入内容#
生成混合向量(dense + sparse)#
将向量注入到每个chunk中#
第七阶段(Milvus导入节点):#
确保Milvus集合存在(schema + index)#
批量插入chunks到Milvus#
回填chunk_id到chunks#
Q检索服务模块(query)#
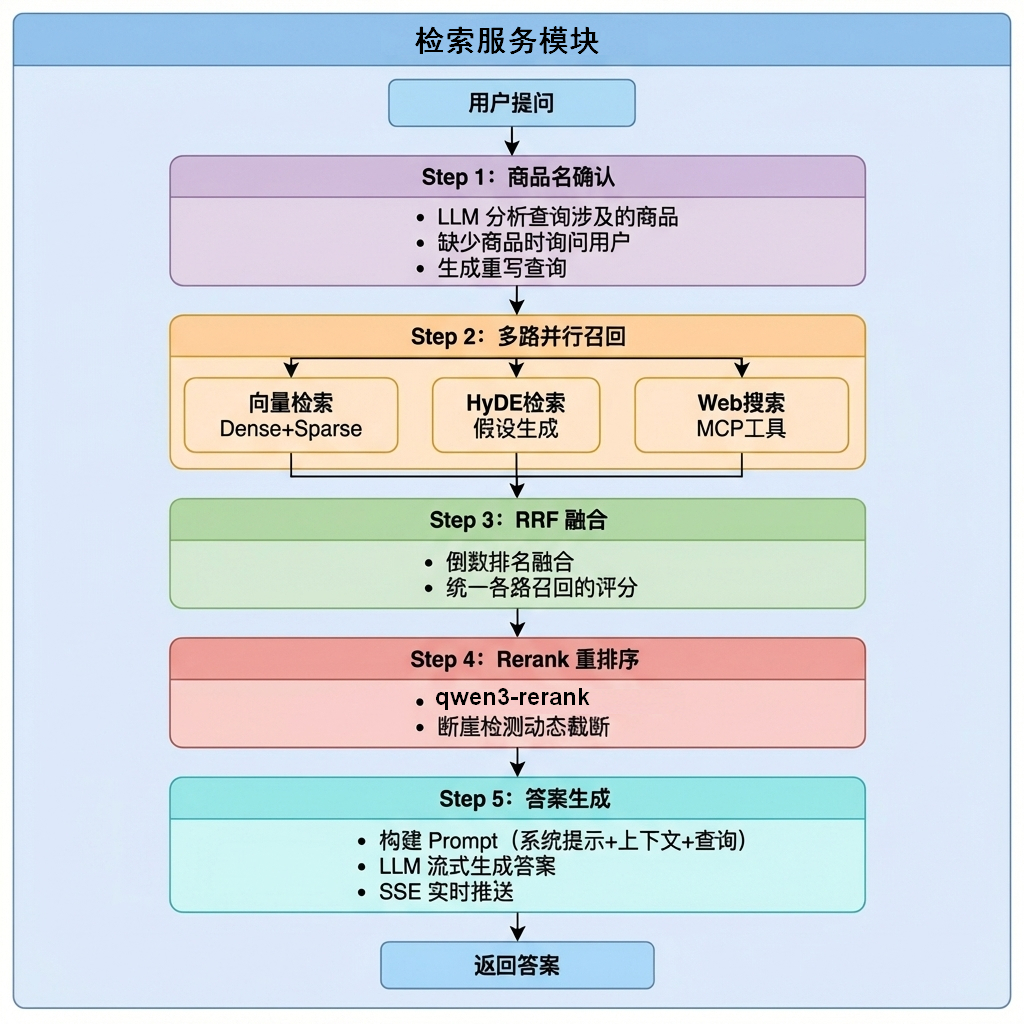
检索服务模块是RAG系统的核心,采用多路召回策略提高检索质量,整个流程分为5个阶段。
第一阶段(商品名确认)#
核心任务:搞清楚用户到底在问什么产品#
具体功能:#
LLM提取商品名:用大模型从用户问题中识别产品名称(如"Brother HAK180 烫金机")#
问题改写:把模糊问题变成完整问题(如"这个怎么用?" → "Brother HAK180 烫金机怎么用?")#
向量对齐:把提取的商品名到数据库里比对,确认是不是标准名称#
评分对齐(置信度判断、下游流程决策):#
- 分数 > 0.85 → 直接确认
- 分数 0.6-0.85 → 让用户选择候选商品
- 分数 < 0.6 → 提示用户重新提供型号
保存对话历史:把用户问题和关联的商品名存入 MongoDB#
第二阶段(向量检索)#
核心任务:用用户问题去知识库里找相关文档#
具体功能:#
- 文本向量化:把用户问题转换成稠密 + 稀疏向量
- 混合检索:同时用两种向量到 Milvus 数据库搜索
- 商品名过滤:只检索指定产品的资料(如只查 HAK180 的文档)
- 返回 Top K:选出最相关的 K 条知识切片
第三阶段(HyDE检索)#
核心任务:用"假设答案"来辅助检索,提高召回率#
具体功能:#
- 生成假设文档:让大模型根据问题编一个"理想答案"
- 组合检索:把"用户问题 + 假设答案"一起向量化
- 混合搜索:用组合向量到知识库检索
- 双重保障:和第一个检索节点配合,增加召回率
第四阶段(MCP网络检索)#
核心任务:本地知识库不够时,去网上搜最新信息#
具体功能:#
- MCP 协议调用:通过标准化协议连接外部搜索工具
- 联网搜索:调用百炼平台的 WebSearch 工具
- 结果解析:把搜索结果整理成统一格式(标题、URL、摘要)
- 补充信息:和本地检索结果一起进入下一步
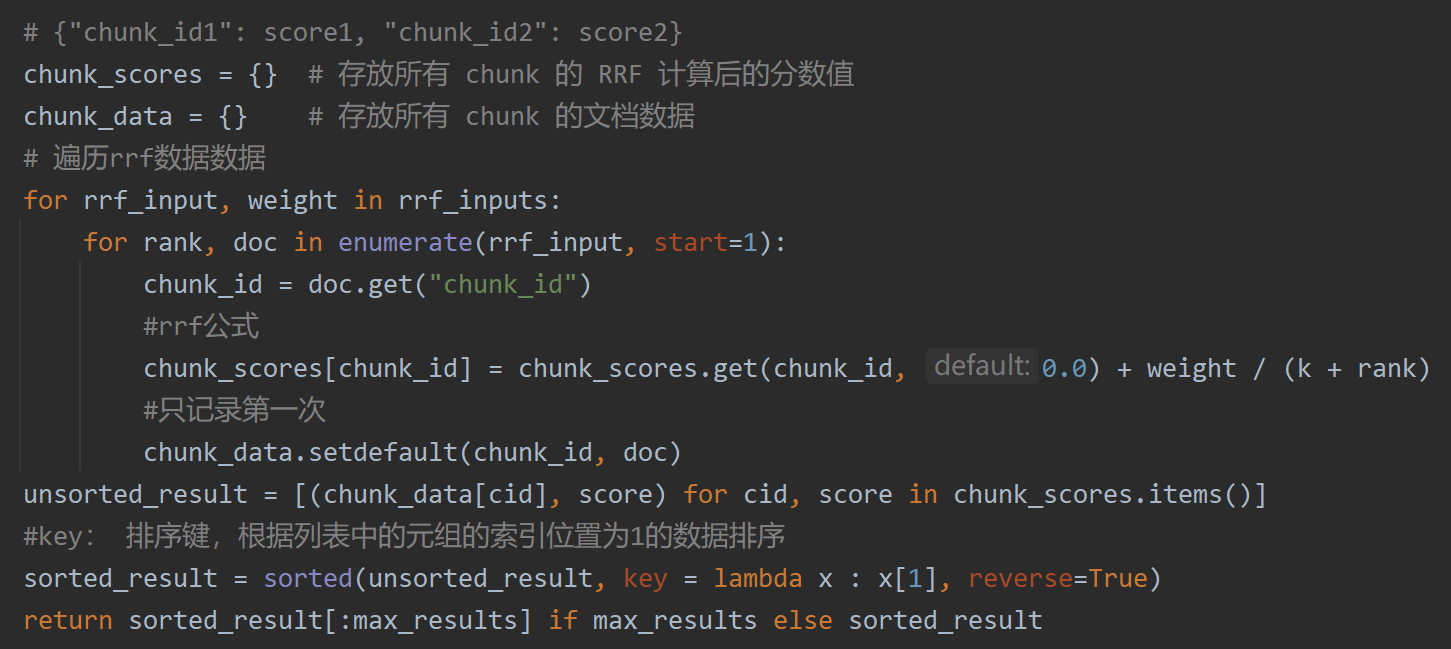
第五阶段(RRF融合)#
核心任务:把不同来源的搜索结果合并成一份榜单#
具体功能:#
- 收集多路结果:汇集向量检索、HyDE 检索的结果
- RRF 公式打分:用"倒数排名融合"算法给每个文档算综合分
- 去重排序:同一个文档在多个路都命中时,分数更高
- 输出融合列表:按综合得分从高到低排列
第六阶段(重排序)#
核心任务:对融合后的结果进行精细打分,选出最相关的#
具体功能:#
- 多源合并:把本地知识和网络搜索结果统一格式
- 精排打分:用 Cross-Encoder 模型给每个文档打精确分
- 断崖检测:智能判断取多少条记录
第七阶段(答案输出)#
核心任务:用检索到的资料 + 大模型生成最终回答#
具体功能:#
- Prompt 构建:把历史对话、检索资料、商品信息组装成提示词
- 字符预算控制:上下文最多 12000 字符,避免超出大模型限制
- 大模型生成:调用 LLM 根据资料生成回答
- 流式输出:支持像 ChatGPT 一样一个字一个字地输出
- 图片提取:从文档中自动提取相关图片 URL 给前端展示
- 保存历史:把最终答案存入 MongoDB
Q前后端交互与 SSE 功能总结#
整体架构概述#
项目采用 FastAPI + SSE 流式推送 架构,支持实时问答和文件导入两大核心功能。
关键设计思想:
- 异步非阻塞:长时间任务在后台运行,接口立即返回
- SSE 实时推送:前端建立长连接,后端逐步推送处理进度和结果
- CORS 跨域配置:允许前端跨域访问
SSE机制详解#
SSE 事件类型#
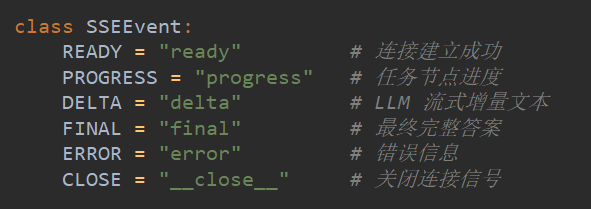
SSE 消息格式#

核心工作流程#
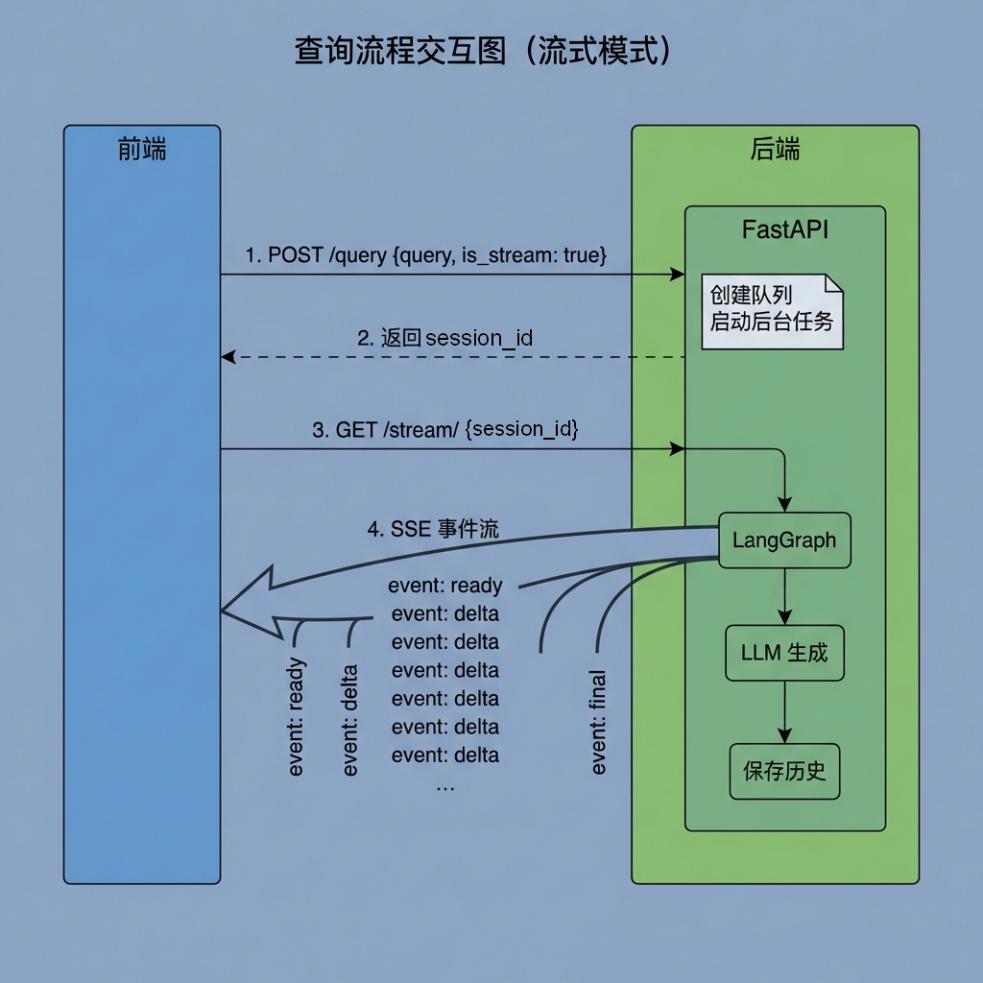
前端请求→后端创建Queue→后台任务执行→push到Queue→SSE Generator读取→推送给前端
前后端交互模式对比#
模式 A:流式查询(SSE)#
前端: POST /query (is_stream=true)
后端: 立即返回 {"message":"结果正在处理中...", "session_id":"xxx"}
前端: GET /stream/{session_id} (建立SSE连接)
后端:
→ 推送 "ready" 事件
→ 执行工作流...
→ 节点执行时 push_to_session("delta", {...})
→ SSE Generator 实时推送给前端
→ 推送 "final" 事件(含答案+图片URL)
→ 清理队列,关闭连接
模式 B:同步查询#
前端: POST /query (is_stream=false)
后端: 同步执行整个工作流,等待完成
后端: 返回 {"answer":"完整答案", "session_id":"xxx"}
模式 C:文件导入(轮询)#
前端: POST /upload (上传文件)
后端: 保存到本地 + MinIO,启动后台任务,返回 task_ids
前端: 定时轮询 GET /status/{task_id}
后端: 返回
{"status":"processing", "done_list":["node1","node2"], "running_list":["node3"]}
非阻塞架构#

技术细节与痛点分析#
Q核心技术细节#
文档切分长度阈值控制#
文档切分时,chunk过大会导致检索精度下降,chunk过小会丢失上下文信息。
多路检索并发执行#
Prompt字符预算控制#
上下文最大字符数计算,遍历累加超限时 break


品名对齐 - 置信度阈值分级#

RRF 融合排序#
断崖检测截断#

Q痛点问题与解决方案#
文档切分导致语义丢失问题#
向量数据库批量插入性能问题#
商品名误判问题#
历史记录商品名缺失问题#
LLM调用稳定性问题#
面试高频问题回答#
Q项目介绍类#
简单介绍一下这个项目#
这是一个基于 RAG 技术的智能知识库系统。系统采用 LangGraph 工作流编排,支持文档自动化导入和智能知识问答两大核心功能。
文档导入流程包括 PDF 解析、图片描述提取、文档分割、商品名识别、向量化、Milvus 存储。 知识查询流程采用多路检索架构——向量检索、HyDE 假设文档检索、网络搜索三路并行,通过 RRF 算法融合,再用 qwen-rerank 重排序,最后基于检索结果生成答案。
技术上,后端使用 FastAPI + LangGraph,向量模型使用 BGE-M3,大模型使用通义千问,向量数据库用 Milvus。我主要负责 LangGraph 工作流设计和后端核心开发。
工作流为什么选择LangGraph?#
状态管理:LangGraph 提供 TypedDict 状态管理,节点间状态传递更清晰#
条件路由:支持复杂的条件分支,如商品名确认后的路由判断#
并发执行:多路检索节点可以自动并发执行#
可视化:可以打印工作流的 ASCII 图,便于调试#
循环支持:支持循环结构,便于实现迭代优化#
Q技术深度类#
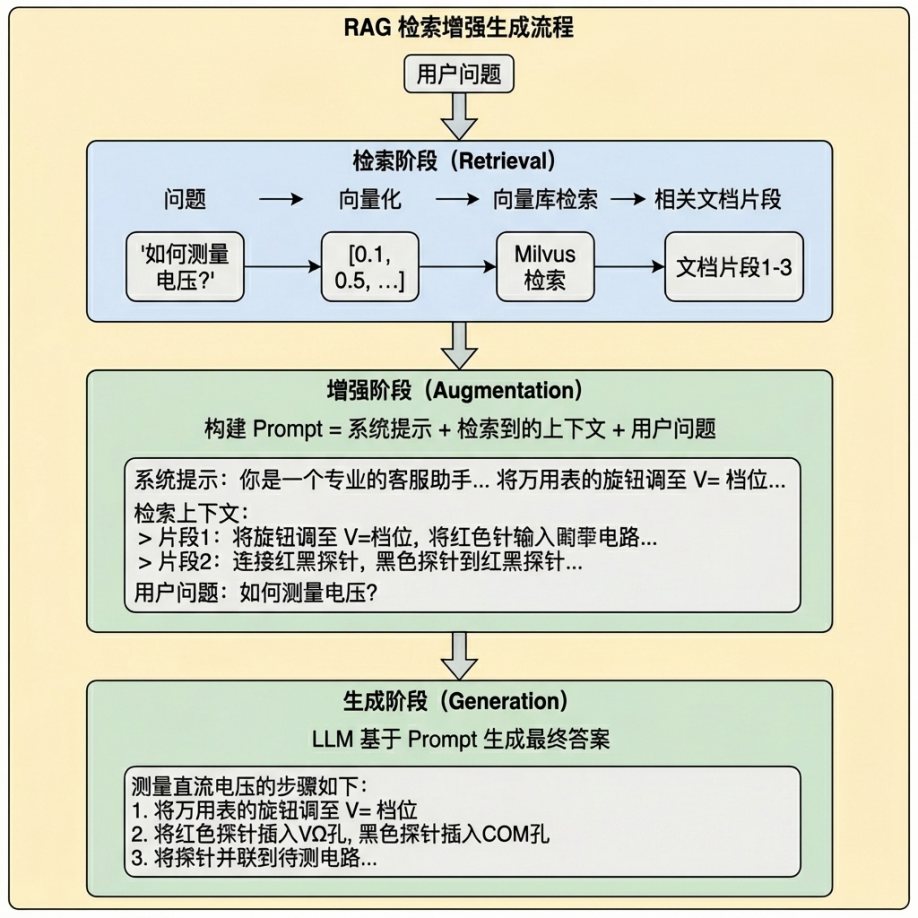
解释一下RAG的工作原理?#
RAG(Retrieval-Augmented Generation)检索增强⽣成,核心思想是:#
Retrieval(检索):将用户问题转换为向量,在向量数据库中检索相似⽂档#
Augmented(增强):将检索到的文档作为上下⽂,与用户问题⼀起构建Prompt#
Generation(⽣成):LLM基于增强后的Prompt生成答案优势:解决LLM知识过时、幻觉等问题,让回答基于实际⽂档内容。#
为什么要采用多路召回而不是单纯的向量检索?#
单路向量检索局限#
- 依赖文本语义相似度,对关键词、专业术语、模糊意图召回不足
- 对知识时效性、外部实时信息完全无法覆盖
- 容易出现语义相似但答案不相关、不精准的问题
三路召回优势#
- 向量检索:保证语义匹配,覆盖常规相似问题
- HyDE 假设性问题生成检索:优化模糊 / 简短 query,提升语义召回质量
- MCP 网络搜索:补充实时、外部、知识库外信息,解决时效性与事实性问题
- 三者互补,召回更全、更准、更稳,显著提升最终回答质量。
BGE-M3 混合向量是什么?为什么要用混合向量?#
BGE-M3 是一个能同时生成稠密向量和稀疏向量的模型。
- 稠密向量是 1024 维的浮点向量,通过深度神经网络编码文本的语义信息,擅长语义理解,能匹配同义词和近义词。
- 稀疏向量是词袋模型,类似于 BM25,每个 token 有一个权重值,擅长精确关键词匹配,如型号、专有名词。
- 混合检索结合了两者的优势:查询"RS-12万用表"时,稀疏向量确保匹配到"RS-12"这个精确型号,稠密向量理解"万用表"的语义。Milvus 的 WeightedRanker 会融合两路结果,我们配置的权重是各占 50%。
解释一下 RRF 融合算法?#
RRF (Reciprocal Rank Fusion) 是倒数排名融合算法,用于合并多个排序结果。
公式:`score(d) = Σ weight_i / (k + rank_i(d))`#
- - d 是待评分的文档
- - i 是第 i 路检索
- - weight_i 是第 i 路的权重
- - rank_i(d) 是文档 d 在第 i 路中的排名
- - k 是平滑参数,通常设为 60
优势:#
- 不需要考虑不同检索结果的分数分布差异
- 算法简单,计算高效
- 对异常值不敏感
在我们的项目中,向量检索和 HyDE 检索权重都是 1.0
什么是 HyDE 检索?#
HyDE (Hypothetical Document Embeddings) 是假设文档嵌入技术。
流程:#
用户提问:"RS-12万用表如何测电压?"#
LLM 生成假设性答案文档:"要测量直流电压,首先将万用表拨到..."#
对假设文档进行向量检索#
返回与假设文档语义相似的文档片段#
原理:#
假设文档包含了用户问题想要的信息,因此与假设文档相似的文档很可能也包含相关信息。
效果:#
在模糊问题或概念性问题上效果显著,能提升召回率
什么是断崖检测截断?#
断崖检测是我们实现的一个动态确定文档数量的算法。
原理:#
重排序后的文档按分数降序排列,从第n个文档开始,逐对检查相邻文档的分数差距。如果绝对差距 >= 0.5 或相对差距 >= 25%,则认为出现"断崖",在此位置截断。
示例:#
- 文档1-5 分数:0.95, 0.93, 0.89, 0.87, 0.82
- 文档6 分数:0.30
- 差距:0.82 - 0.35 = 0.52 > 0.5 → 截断
优势:#
避免低分文档混入,同时避免固定 Top-K 的机械性,根据分数分布动态确定保留数量。
Q问题解决类#
项目中遇到过什么技术难点?是怎么解决的?#
回答示例一:商品名误判问题#
问题:LLM 提取商品名时可能误判,如将"万用表测量电阻"误认为商品名。
解决方案:设计了两级过滤机制
向量对齐:对每个提取名称进行 Milvus 检索,获取真实商品名和相似分数#
评分对齐:score > 0.85 放入 confirmed,0.6-0.85 放入 options,< 0.6 丢弃#
这样既保证了召回率,又控制了精确度。
回答示例二:历史记录商品名缺失#
问题:用户可能在多轮对话后才明确商品名,导致前几轮对话的 item_names 字段为空。
解决方案:延迟回填机制
当商品名确认后,查询该会话的历史记录#
找出 item_names 为空的记录#
批量更新这些记录的 item_names 字段#
这样确保了历史记录的完整性,便于后续的数据分析。
如何保证系统的高可用?#
模型单例:BGE-M3、qwen-flash等使用单例模式,避免重复加载#
批量操作:Milvus 批量插入,减少网络往返#
容错处理:LLM JSON 解析失败时进行清洗和容错#
降级策略:商品名确认失败时返回澄清选项,而非直接报错#
资源清理:SSE 队列在 finally 块中清理,防止内存泄漏#
如何保证LLM回答的准确性?#
多层保障机制:
- 检索质量:多路召回+重排,确保检索到最相关的⽂档
- Prompt设计:明确要求"基于事实回答,不编造信息"
- temperature=0:使⽤确定性输出,避免随机性导致的错误
- 引⽤来源:要求LLM引⽤参考资料编号,便于溯源验证
- 通过RAGAS进行评估模型,观察分数,分析bad case 进行不断打磨。(会被追问)。
Q评估优化类#
你们ragas 评估主要观察哪些指标?这些指标都高低都代表着什么含义?#
我们主要观察 5 个指标:faithfulness、answer_relevancy、context_precision、context_recall、answer_correctness。
faithfulness 是忠实度,主要看答案是否能被检索到的上下文支撑。分数高说明答案基本基于资料,没有明显编造;分数低说明模型可能在脑补,或者上下文没有提供足够证据,或者资料给的过于多过于啰嗦模型没有准确找到答案。
answer_relevancy 是答案相关性,主要看回答是否真正回应了用户问题。分数高说明回答切题;分数低说明可能跑题、答非所问,或者回答里有较多无关内容。一般是大模型能力问题不能正确理解问题。
context_precision 是上下文精确率,主要看召回的 contexts 里有多少内容是真正有用的。分数高说明检索结果比较干净;分数低说明检索噪声大,可能召回了很多无关切片。
context_recall 是上下文召回率,主要看 contexts 是否覆盖了回答问题所需的关键信息。分数高说明关键证据基本拿全了;分数低说明相关资料没有被完整召回,可能需要优化 top-k、query 改写、chunk 粒度或召回策略。
answer_correctness 是答案正确性,主要看生成答案和参考答案 ground truth 的匹配程度。分数高说明答案和标准答案比较一致;分数低,如果其他分数都高,说明提示词或模型能力问题,如果其他分数都低,说明是筛选切片的问题。主要用来筛选bad case .
你们的测试问题集是如何来的?#
未上线前自检测试:开发人员自己用AI生成。
正式测试:
假设之前有人工客服:收集整理历史样板问答。
假设之前没有人工客服: 由业务人员编写。
bad case 主要分析什么?步骤如何?#
查询评估结果:从 正确性的指标(answer_correctness) 找到bad case 。#
观察其他指标: 比如:上下文召回率、忠实度都低,说明流程没有个给到准确的资料 。#
去原始文档里核查原始的资料。#
初步可能性定位 : 比如:文档切片都丢失 1 embedding 2 rrf 3 rerank 。#
重跑问题并排查日志 : 定位切片丢失位置。#
分析原因: 比如rerank 对处于长文本后面的资料不敏感 会忽略 从而给低分。#
解决方案: 比如:让切片更小,保留个数更多 。#
验证测试:通过 了rerank,合适评分,最终ragas评分提高。#
有哪些优化的案例?#
第一个是切片和重排问题。某些问题明明原文里有答案,但相关切片没有进入最终提示词。分析后发现可能是 chunk 太大,关键信息靠后,reranker 没有很好识别。优化方式是调小切片大小,比如把最大切片长度从 1000 调到 500,同时适当提高 rerank 和 RRF 保留的结果数量。优化后 faithfulness、context_precision、context_recall 都有明显提升。
第二个是提示词问题。整体检索指标不低,但 answer_correctness 不高,原因是模型回答太散、太啰嗦,和参考答案匹配度不高。优化方式是调整回答生成提示词,要求只基于参考内容回答,不扩写、不脑补,普通问题尽量控制在 2 到 5 句话,多对象问题按对象分组回答。这样可以让答案更聚焦,也更接近标准答案。
第三个是图谱信息缺失问题。有些问题文本切片里信息比较多,噪声会干扰模型回答,而图谱本来可以提炼关键点。但之前查询图谱时没有把实体的 description 带出来,导致模型只看到关系名称,缺少完整警告内容,容易脑补原因。优化方式是在图谱查询时把节点 description 一起查出,并拼接到最终图谱关系描述里,同时优化 Warning 命名,避免不同警告重名覆盖。这样可以让模型拿到更完整、更准确的结构化知识。
Q资源部署类#
知识库服务是如何部署的?资源如何分配 ?#
我们当时把知识库作为电商系统旁边的一个独立 AI 服务来部署,主业务系统通过 HTTP 调用知识库接口,不和订单、商品、支付这些核心业务强耦合。
基本假设:
注册用户 20-80万
日活DAU 2万-3万
资源估算:
按 AI 客服触达 25%-40%、日咨询 4000-7000 次、每次平均 8 轮来估算,每天大概 3.2 万到 5.6 万次问答。如果集中在 8 小时内,平均 QPS 大约是 1.1 到 1.9。生产上不能只看平均值,所以一般按 3-5 倍峰值预留,也就是按 5-10 QPS 来准备。
服务资源规划:
CPU 业务服务器:8C32G, 部署 kb-query、kb-import、
MongoDB、Neo4j 服务器: 8C32G SSD 1TB
Milvus 相关服务:8C32G ,主要跑 Milvus + etcd + MinIO SSD 1TB
GPU 服务器 :8C-16C,32-64G 内存,24GB-32GB 显存,4090D-5090 部署 BGE-M3 和 reranker。
部署方式:
通过docker + docker compose 部署,编写dockerfile 和 docker-compose.yaml来实现部署配置。
为什么要拆分成gpu服务器和cpu服务器两种 ?#
因为BGE-M3、reranker 这两种模型的计算能力gpu是cpu的数倍,效果更好。
为什么vl模型和文本模型没有独立部署?#
因为当前项目刚刚起步访问量还不大,用现成的较大参数的模型服务比独立部署部署的中小开源服务更加稳定可控。
为什么没有使用k8s部署 ?#
公司业务系统目前使用k8s部署,但是ai部分刚刚起步,现在独立环境下部署,以后稳定会慢慢过度到k8s整体部署。
Q扩展思考类#
如果让你重新设计这个系统,你会做哪些改进?#
缓存层:添加 Redis 缓存热门问题和答案#
对话摘要:长对话使用 LLM 生成摘要,而非简单裁剪#
分布式部署:使用 Kubernetes 实现水平扩展#
可观测性:集成 OpenTelemetry 实现分布式追踪#
A/B 测试:对比不同检索策略的效果#
向量数据库分区:按商品名分区,加速检索#
多路检索之间是如何协同的?#
多路检索通过 LangGraph 的并发执行机制协同工作:
并发分发:multi_search 虚节点同时触发三个检索节点#
并行执行:三个节点并行执行,互不影响#
结果汇合:join 虚节点等待所有检索完成#
RRF 融合:rrf节点按 RRF 算法融合结果#
重排序:rerank 节点用 qwen-rerank对rff的结果进行 精排#
这种设计的优势是:
- 并行执行,提升性能
- 结果互补,提升召回率
- 权重可配置,便于调优
面试口述版项目总结#
Q30s版#
我参与开发了一个基于 RAG 技术的智能知识库系统。系统采用 LangGraph 工作流编排,支持文档自动化导入和智能知识问答。后端使用 FastAPI + LangGraph,向量模型使用 BGE-M3 混合向量,大模型使用通义千问。查询流程采用多路检索架构——向量、HyDE、网络三路并行,RRF 融合后用 BGE-Reranker 重排序。我主要负责 LangGraph 工作流设计和后端核心开发。
Q2分钟版#
项⽬背景#
这是一个企业级智能知识库系统,目标是为企业的产品文档提供智能化管理和问答服务。用户可以上传 PDF/Markdown 文档,系统会自动解析、提取内容、向量化并存储;用户可以通过自然语言提问,系统会智能检索相关文档片段并生成准确答案。
技术架构#
系统采用前后端分离架构,分为四层:
- 展示层:原生 HTML + JavaScript,实现文档上传和智能问答界面
- API 层:FastAPI 应用,提供 RESTful API 和 SSE 流式接口
- 工作流层:LangGraph 编排的导入和查询流程
- 存储层:Milvus 向量库、MongoDB 文档库、MinIO 对象存储
核心是多路检索架构:向量检索使用 BGE-M3 混合向量(稠密+稀疏),HyDE 检索生成假设文档后再检索,网络搜索补充时效信息。三路结果通过 RRF 算法融合,再用qwen3-rerank 重排序,最后基于检索结果生成答案。
我的职责#
我主要负责 LangGraph 工作流设计、商品名确认节点、多路检索融合、SSE 流式推送等核心模块。
技术亮点#
项目有几个技术亮点:一是商品名智能确认机制,LLM 提取 + 两级过滤(向量对齐、评分对齐);二是断崖检测截断算法,动态确定最佳文档数量;三是历史记录回填机制,延迟确认商品名后补全历史。
Q5分钟版#
项目背景与目标#
这是一个企业级智能知识库系统,服务于企业的产品文档管理需求。传统文档检索方式依赖关键词匹配,语义理解能力弱,检索效果差。我们的目标是通过 RAG 技术实现精准的语义检索和智能问答,覆盖两个核心场景:文档自动化导入和智能知识问答。
整体架构设计#
系统采用前后端分离架构,分为四层:
- 展示层:原生 HTML + JavaScript,实现文档上传界面和智能问答界面
- API 层:FastAPI 应用,提供文档上传、知识查询、SSE 流式推送等接口
- 工作流层:LangGraph 编排的导入流程和查询流程
- 存储层:Milvus 向量库、MongoDB 文档库、MinIO 对象存储
导入流程包含七个节点:文件上传 → PDF 转 Markdown(MinerU)→ 图片描述提取(Qwen3-VL)→ 文档分割 → 商品名识别 → 向量化(BGE-M3)→ 导入 Milvus。
查询流程采用多路检索架构:商品名确认 → 向量检索、HyDE 检索、网络搜索三路并行 → RRF 融合 → qwen3-rerank重排序 → 答案生成。
核心技术实现#
- BGE-M3 混合向量:BGE-M3 同时生成稠密向量和稀疏向量。稠密向量 1024 维,擅长语义理解;稀疏向量是词袋模型,擅长精确匹配。Milvus 的 WeightedRanker 融合两路结果,权重各占 50%。这样既能匹配"万用表"的语义,又能精确匹配"RS-12"的型号。
- 商品名确认机制:用户提问时可能商品名模糊,我们设计了两级过滤机制:LLM 提取商品名 → 向量对齐(Milvus 检索真实商品名)→ 评分对齐(按分数分配到 confirmed 或 options)。如果商品名模糊,返回澄清选项让用户选择。
- RRF 融合算法:公式是 `score(d) = Σ weight_i / (k + rank_i(d))`。不依赖具体分数值,只依赖排名,对异常值不敏感。我们配置向量检索和 HyDE 权重为 1.0。
- 断崖检测截断:重排序后按分数降序排列,从第 3 个文档开始检查相邻分数差距。如果绝对差距 >= 0.5 或相对差距 >= 25%,则截断,最多保留10个文档。这样动态确定保留文档数量,避免低分文档混入。
- SSE 流式推送:使用 Python 的 queue.Queue 存储 SSE 事件,后台任务推送进度,前端通过 EventSource 接收。事件类型包括 ready、progress、final、close 等。
遇到的挑战与解决方案#
最大的挑战是商品名误判。LLM 可能将"万用表测量电阻"误认为商品名。我们设计了两级过滤:向量对齐、评分对齐。向量对齐通过 Milvus 检索真实商品名,评分对齐按相似度阈值分类,分数差异过滤去除与最高分差距过大的误判商品。
另一个挑战是历史记录商品名缺失。用户可能在多轮对话后才明确商品名。我们实现了延迟回填机制,确认商品名后批量更新历史记录的 item_names 字段。
项目成果与收获#
项目最终实现了完整的智能知识库功能,支持文档自动导入和智能问答。技术上,我深入理解了 LangGraph 工作流编排、BGE-M3 混合向量、RRF 融合算法、SSE 流式通信。工程上,锻炼了从需求分析到架构设计再到编码实现的全流程能力。
如果有机会重构,我会考虑引入 Redis 缓存热门查询、实现对话摘要、以及添加 A/B 测试框架对比不同检索策略的效果。
QSTAR法则回答模板#
问题:请介绍一个你解决过的技术难题#
S (Situation) - 情境:#
"在开发智能知识库系统时,LLM 提取商品名经常出现误判,
如将'万用表测量电阻'误认为商品名"
T (Task) - 任务:#
"我需要设计一个可靠的商品名确认方案,
在各种模糊输入下都能准确识别真实商品名"
A (Action) - 行动:#
"我设计了两级过滤机制:
- 向量对齐:对 LLM 提取的每个名称进行 Milvus 检索,获取真实商品名和相似分数
- 评分对齐:score > 0.85 放入 confirmed,>= 0.6且< 0.85 放入 options,< 0.6 丢弃
同时实现了历史记录回填机制,延迟确认后补全历史"
R (Result) - 结果:#
"方案上线后,商品名识别准确率从 70% 提升到 95%,
用户澄清率下降 60%,历史记录完整性达到 100%"
Q常见追问#
技术亮点速记#
QBGE-M3 混合向量#
- 稠密向量 (1024 维) + 稀疏向量 (词袋)
- Milvus WeightedRanker 融合权重各50%
Q多路检索融合#
- 向量 / HyDE / 网络三路并行
- RRF 融合算法
- qwen3-rerank 重排序
Q商品名智能确认#
- LLM 提取 + 向量对齐 + 评分过滤
- LLM提取可能误判,因此添加后面的两级过滤机制
- 历史记录回填
Q断崖检测截断#
- 动态确定文档数量
- 绝对差距 >= 0.5 或相对差距 >= 25%
- 最少 3 条,最多 10 条
QSSE 流式响应#
- queue.Queue 存储 SSE 事件
- 事件类型: ready/progress/final/close
- 生命周期管理
QMongoDB 历史对话管理#
- session_id 多轮对话关联
- item_names 延迟回填
- 指代消解上下文传递
QMinerU PDF 解析#
- 支持复杂杂糅式文档
- PDF 转 Markdown,保留表格 / 公式 / 图片
QVLM 图片语义提取#
- Qwen3-VL-Flash 生成图片描述
- 替换原始图片标签为语义文本
- 提升检索召回率
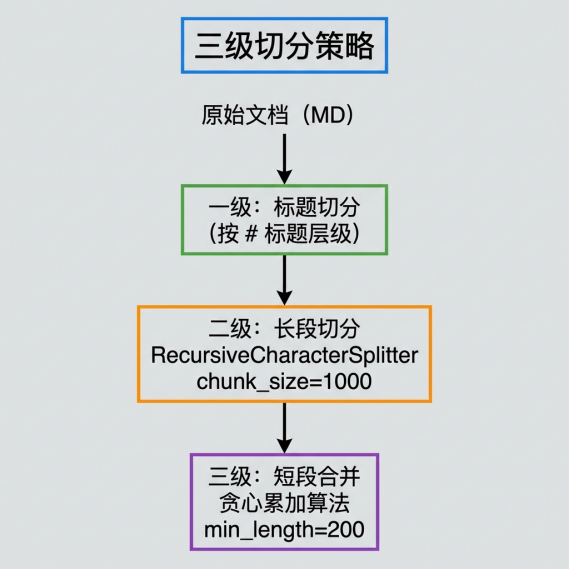
Q智能文档切分#
- 标题层级切分 (Markdown 标题结构)
- 递归切分 (RecursiveCharacterTextSplitter)
- 贪心合并 (max_chunk_size=1000, min_chunk_size=200)
Q控流防过载#
- 模型接口调用速率限制
- 双端队列实现令牌桶算法