项目周期#
- 1人团队,总计约2个月。
- 需求分析与技术选型5天
- 数据准备与预处理2周
- 模型开发与训练2周
- 推理模块开发1周
- 系统集成与后端对接1周
- 部署上线1周
功能介绍#
根据商家上传的商品图片生成推荐标题,底层是通过多模态图生文实现的。
实现流程#
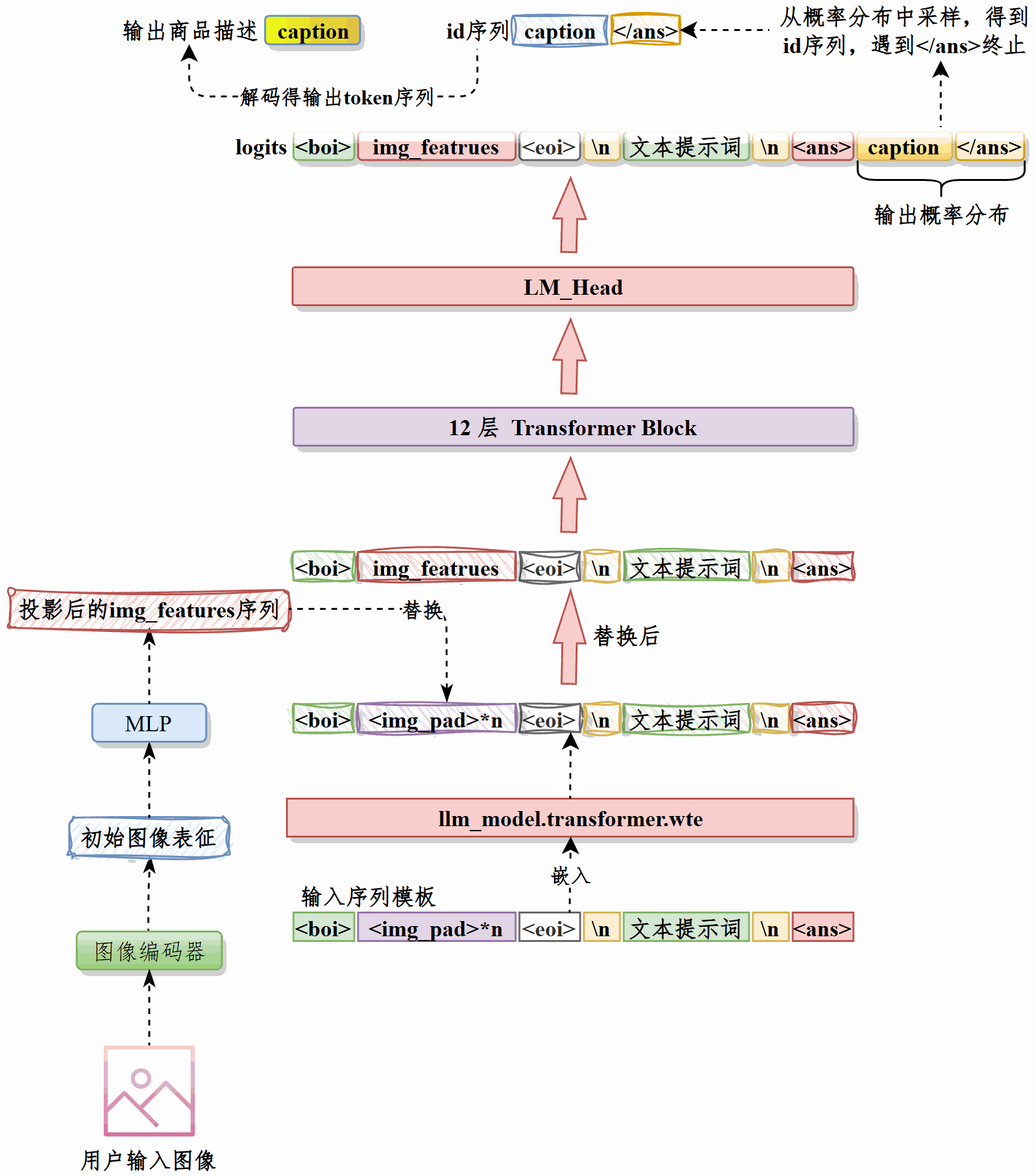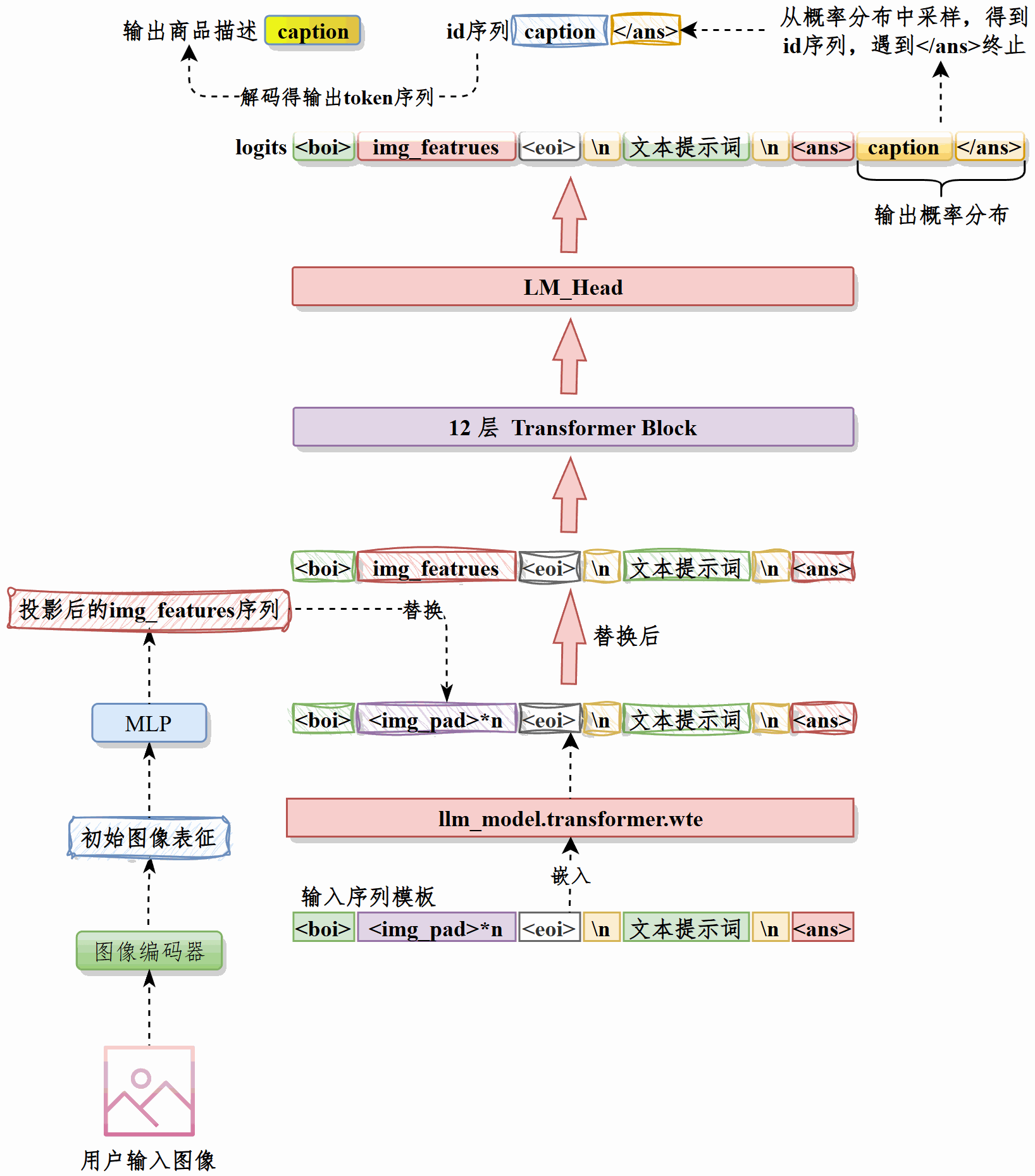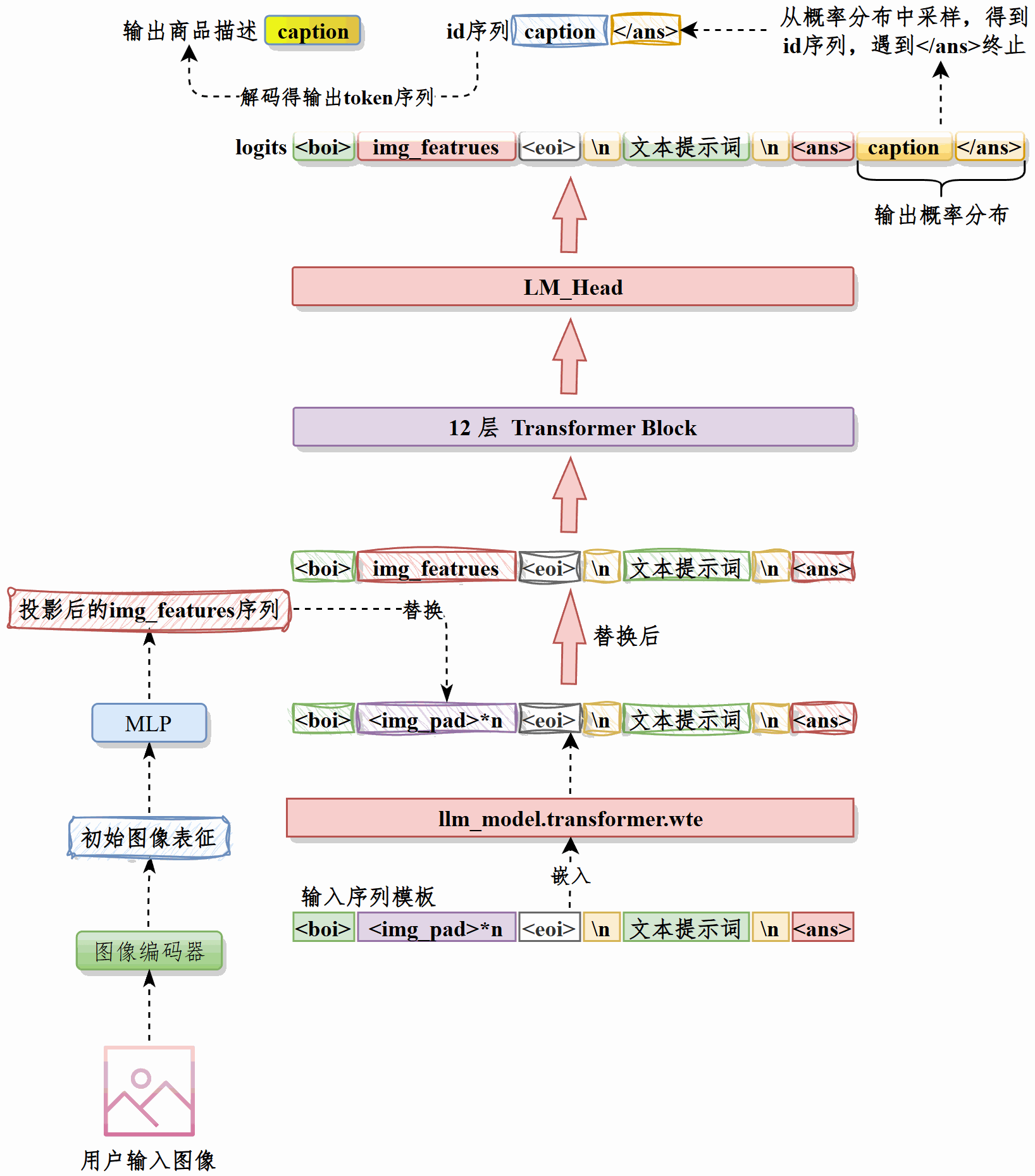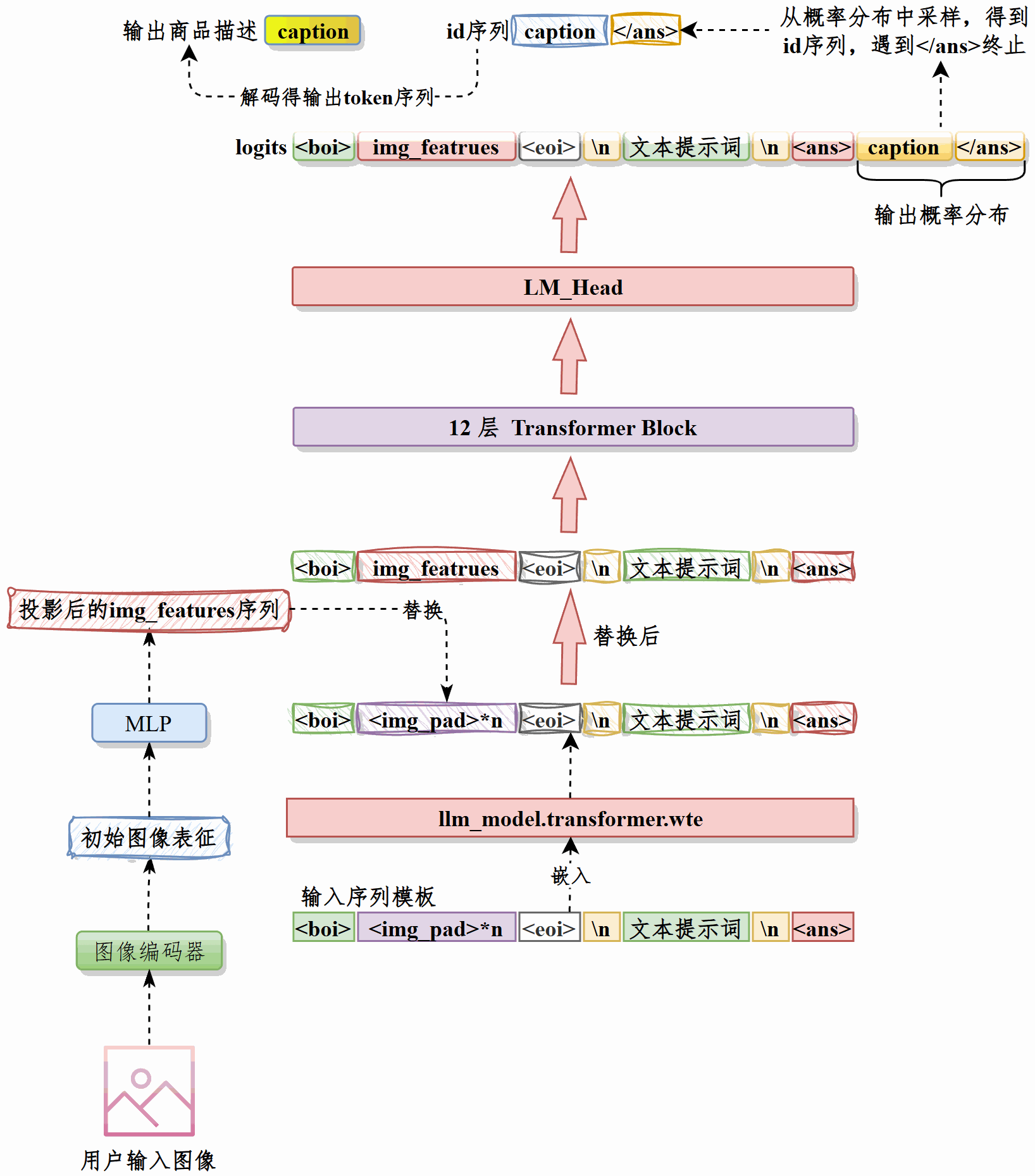
通过编码器将图像转换为特征->图像特征投影->和文本提示嵌入拼接为完整Prompt序列->LLM根据Prompt生成推荐标题。
技术细节#
Q图像编码器#
使用openai/clip-vit-base-patch32作为图像编码器,训练过程冻结模型。
该模型接收3通道、尺寸224*224的图像,将模型输出中的pooler_output向量作为图像特征传递给下游。该向量汇总了图像的全局信息,维度为768。
Q图像投影层#
将两个线性层构成MLP,作为图像投影层。将768维的图像特征映射为10*768的向量,然后再通过view将形状变换为(10, 768),即长度为10的特征向量序列,传递给下游。
Q拼接图像提示和文本提示#
构造这样的提示词前缀。
<boi><img_pad>*10<eoi>\n用户提示词\n<ans><img_pad>是图像特征的占位符。
上述内容经过LLM的嵌入层处理为向量,然后用图像投影层输出的10个特征替换<img_pad>对应的10个向量,得到的嵌入矩阵input_embeds将作为下游LLM的输入。
QLLM#
选择uer/gpt2-chinese-cluecorpussmall作为LLM,模型由12个Transformer Block构成。
接收input_embeds作为输入,输出推荐标题。
总结#
图生文模块的功能是:根据用户输入的商品图片生成推荐标题。
首先,我们通过图像编码器将图像处理为特征表示。#
在训练过程中图像编码器是完全冻结的,我们完全可以将原始图像提前处理为表征并落盘,训练时加载处理好的图像表征文件而非原图。这样一来,训练时就省去了图像编码器的前向传播过程,显著提升训练效率,节省资源开销。每张图像只需要在预处理时经图像编码器进行一次前向传播,总体的计算量也显著降低。#
首先对图像进行预处理,统一为RGB 3通道格式,尺寸为224*224。。#
每张图像经过CLIP的vision_model处理,提取输出中的pooler_output作为图像表征,以图像的唯一ID为key,pooler_output为value构建字典,通过torch.save存储为pytorch文件image_features.pt。该文件只用于训练,不用于推理。#
模型训练细节#
数据集由两部分构成:处理好的图像表征和对应的文本描述,通过图像的唯一ID将图像表征和对应的文本描述caption逐一组合在一起,构建为数据集。#
训练时将caption拼接到下面的提示词模板中#
<boi><img_pad>*10<eoi>\n用户提示词\n<ans>caption</ans>然后用LLM的嵌入层处理为特征矩阵。
将图像表征经过投影层处理为提示词序列,替换特征矩阵中<img_pad>对应的向量,这就是最终给到LLM的input_embeds#
将input_embeds输入LLM,只计算caption</ans>部分的损失,通过反向传播更新整个LLM和投影层权重。#
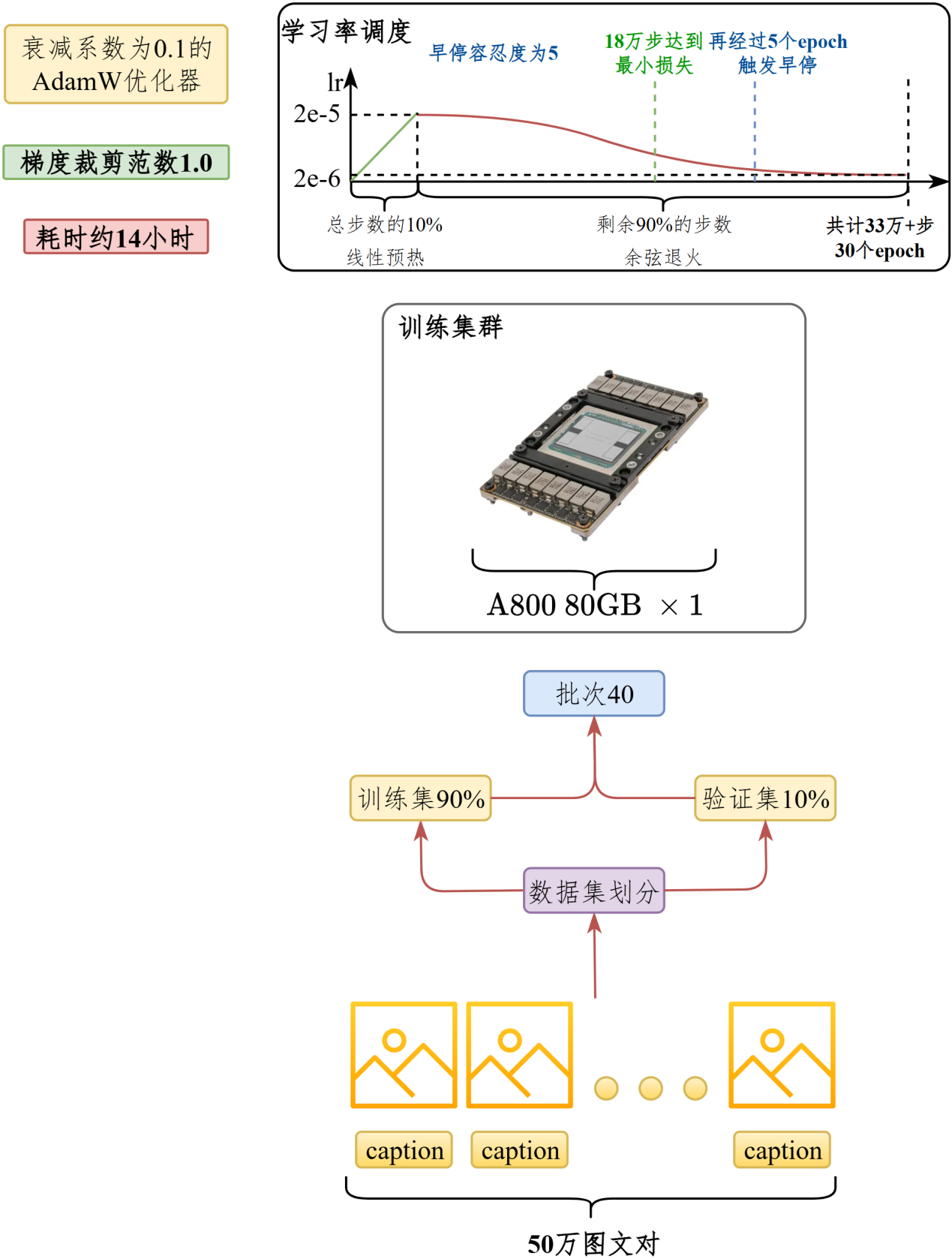
在50万个图文对上训练,训练集和验证集按照9:1划分,批次大小40,采用衰减系数为0.1的AdamW优化器,应用范数为1.0的梯度裁剪。训练共30个epoch,约33万步,在前10%的步数应用线性预热,学习率从0达到最大值2e-5,经过剩余90%的步数学习率衰减至2e-6。早停容忍度为5个epoch。#
训练在【1张A800 80GB】上进行,显存占用在30~40GB之间,训练16个epoch,累计18万步之后验证损失达到最小,再经过5个epoch触发早停。训练时长约14小时。#
推理过程#
接收用户输入的图像,经过图像编码器处理为向量,然后通过最佳的投影模型投影为向量序列img_features。#
将下面的提示词前缀处理为嵌入#
<boi><img_pad>*10<eoi>\n用户提示词\n<ans>用img_featrures替换嵌入后的向量中10个<img_pad>的位置,这就是input_embeds,将其输入LLM。#
LLM输出下一个token的logits,根据用户输入的topp和topk调整logits,然后得到下一个token的概率分布,采样得到下一个token的ID。重复此过程直至达到最大输出长度或遇到</ans> token。得到生成标题的token ID序列。#
对ID序列解码得到模型生成的标题。#
项目串讲#
Q训练逻辑#
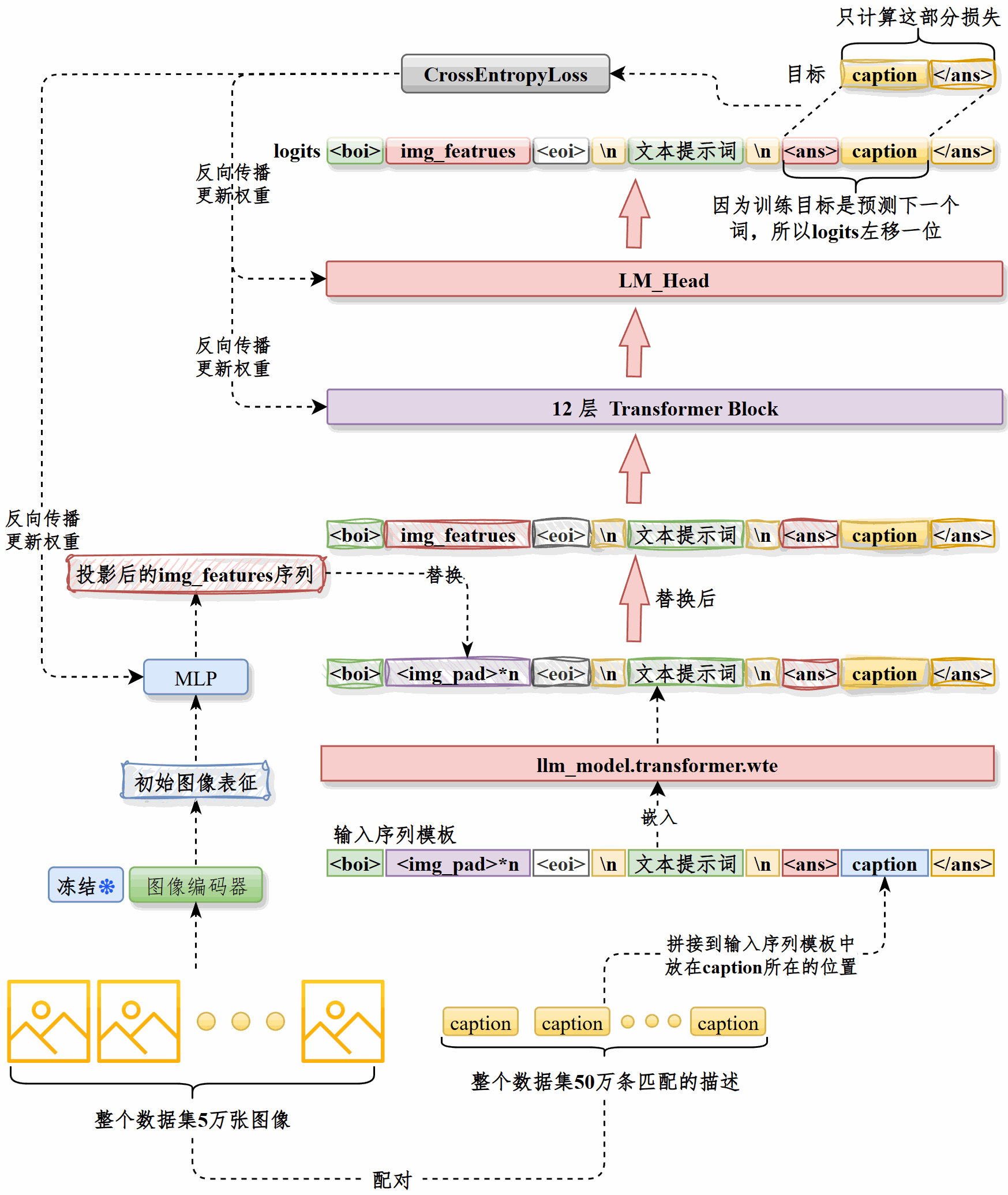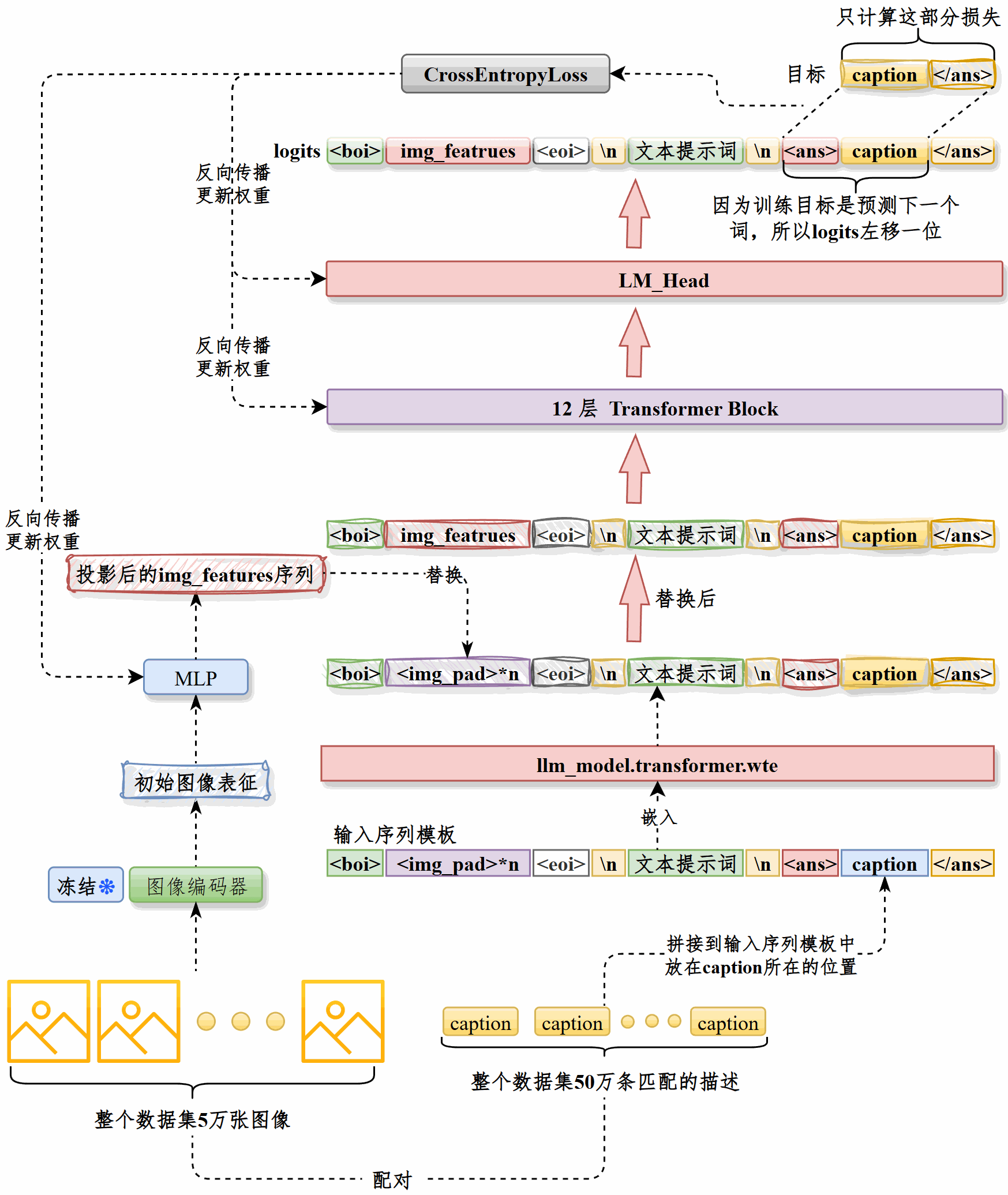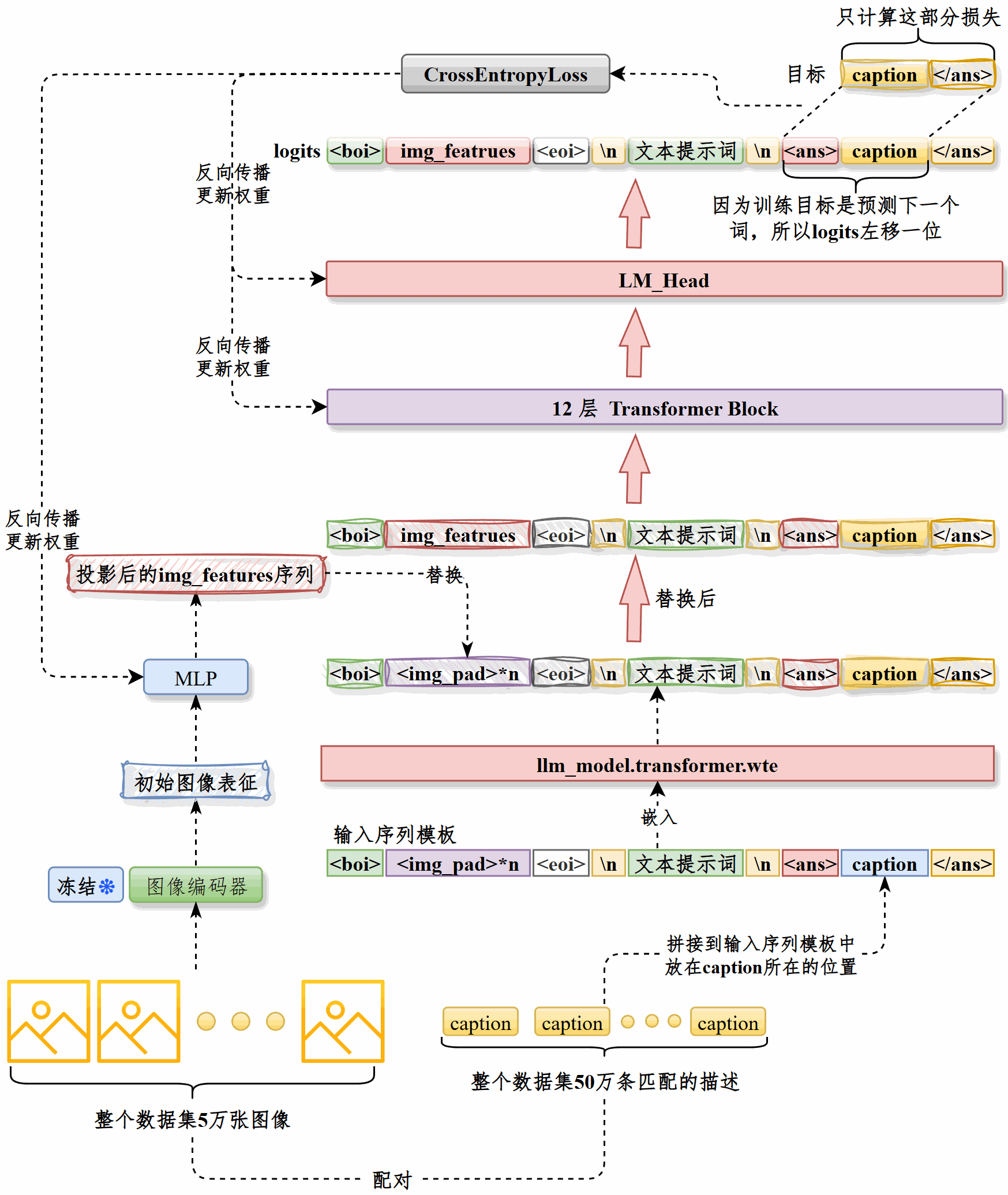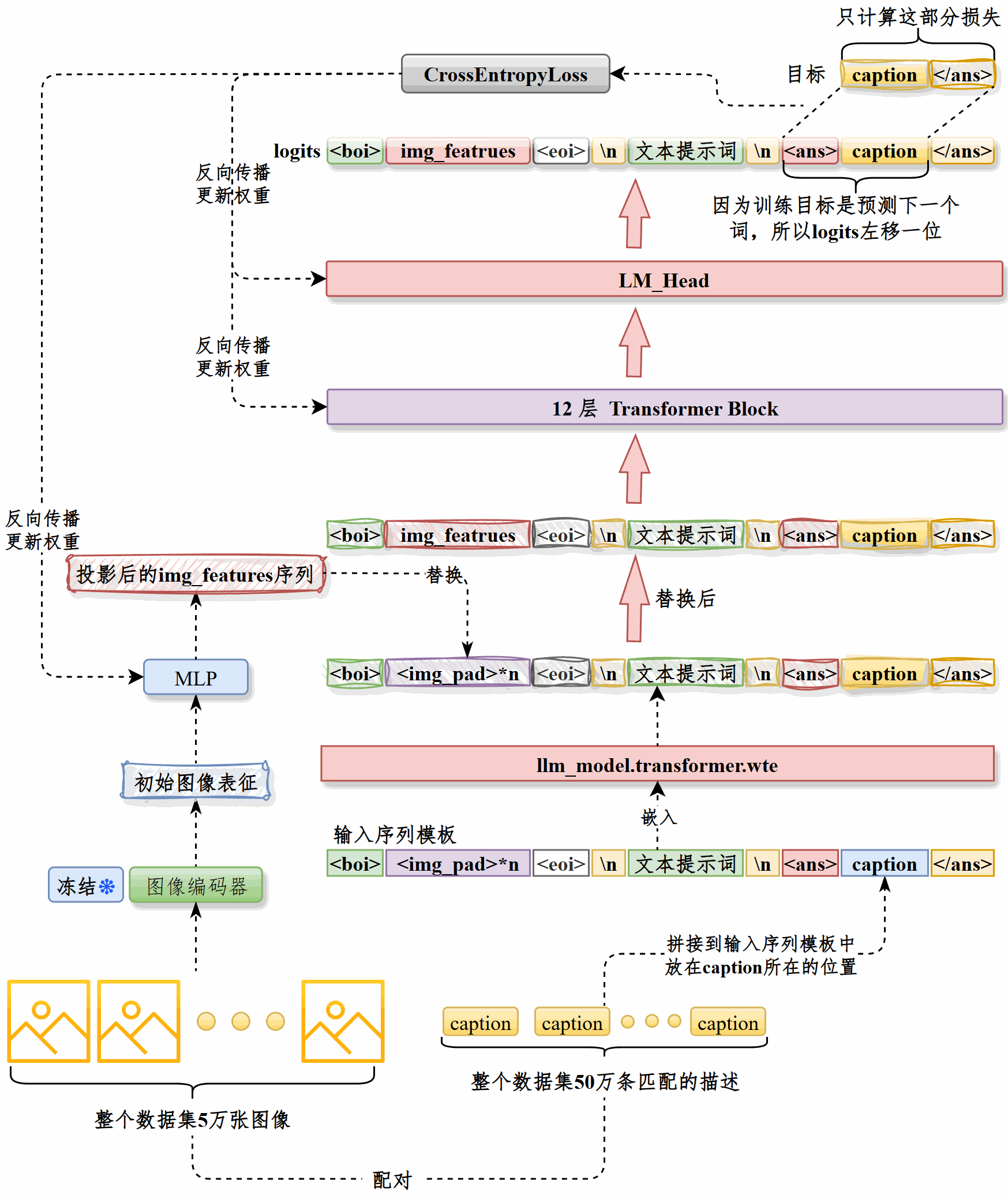
串讲#
图生文模块的目标是根据商品图片自动生成推荐标题
整体流程是先对图像进行预处理,统一为 RGB 三通道、224×224 尺寸,再通过CLIP 的vision_model提取pooler_output作为图像表征,用图像ID唯一标识,然后将ID和表征共同存储,训练时直接加载。这种方式显著提升了训练效率和资源利用率。
训练时将caption拼接到提示词模板中,经由LLM的嵌入层处理,然后将图像表征经过投影层处理,用其输出替换<img_pad>部分得到最终的输入向量,输入LLM。
只计算caption部分的损失,通过反向传播更新LLM和投影层权重。
在50万图文对上训练,采用AdamW 优化器和梯度裁剪,应用学习率预热和衰减策略,最终在一张A800 80GB显卡上完成约18万步后达到最优效果并触发早停。训练时长约14小时。
关键超参数#
Q推理逻辑#
串讲#
推理时先接收用户图像,经图像编码器得到向量表示并用最佳投影模型映射为向量序列 img_features。然后将提示词前缀经过LLM嵌入层得到文本向量,用img_features依次替换其中10个图像占位符<img_pad>的位置,形成融合图像语义的input_embeds并输入 LLM。
后者逐步输出下一token的 logits,按用户设定的top-p与top-k进行筛选与采样,获取下一token的 ID,循环直至达到最大输出长度或遇到</ans>。最后对得到的ID序列解码,输出模型生成的标题。