项目周期#
1人,1-1.5个月即可。
参考周期:#
- 需求分析与架构设计1 周
- 核心模块开发3 周(可适当延长)
- 联调测试与优化1 周
- 效果验证与上线1 周
项目简介#
归因分析智能体是一个面向业务分析、经营诊断、问题定位场景的智能体应用。和普通问答式聊天应用不同,这个项目强调的不只是模型给出一句回答,而是让系统能够围绕一个真实分析任务持续推进,直到生成阶段性结论、分析材料和可交付结果。
在很多真实业务场景里,用户面对的问题往往不是一句话就能回答清楚的。归因分析智能体解决的就是这种复杂问题,比如某个指标为什么下滑、某个业务区域为什么异常、某次活动为什么效果不达预期,这些问题通常都需要先拆解,再查数,再结合上下文做判断,最后把结果整理成可复用的输出。通过将复杂任务进行拆解,并执行一个调用工具、查找信息、整理文档的智能分析流程,将一次分析逐渐发展成一个可持续推进的工作过程。
适用业务场景:#
- 销售额 / 订单量 / 转化率指标下滑原因分析
- 品类、渠道、地域、用户分层多维拆解信息
- 季节性、供应链、库存积压 & 缺货风险分析
- 营销活动效果复盘、渠道贡献分析
- 历史分析任务沉淀、可回溯可复用
整体架构设计#
Q核心模块划分#
会话与消息管理模块#
- 会话创建 / 删除 / 改名 / 列表查询
- 历史消息持久化、顺序号管理
- 长对话上下文自动压缩
- 用户鉴权、会话隔离、草稿会话机制
Agent 智能分析引擎模块#
- 大模型接入与管理(通义千问、MiniMax 等)
- MCP 外部工具接入
- Skill 技能约束归因分析流程
- 会话独立工作区机制
数据查询与分析模块#
- 对接独立 Data Agent 服务
文件与报告生成模块#
- 结构化 JSON 报告中间层
- 报告支持预览、下载、复用
接口与实时推送模块#
- 全套 RESTful 业务接口
- WebSocket 长连接流式聊天
- 临时 Token 鉴权、跨域、中间件
- 全局异常处理、日志链路追踪
Q整体架构#
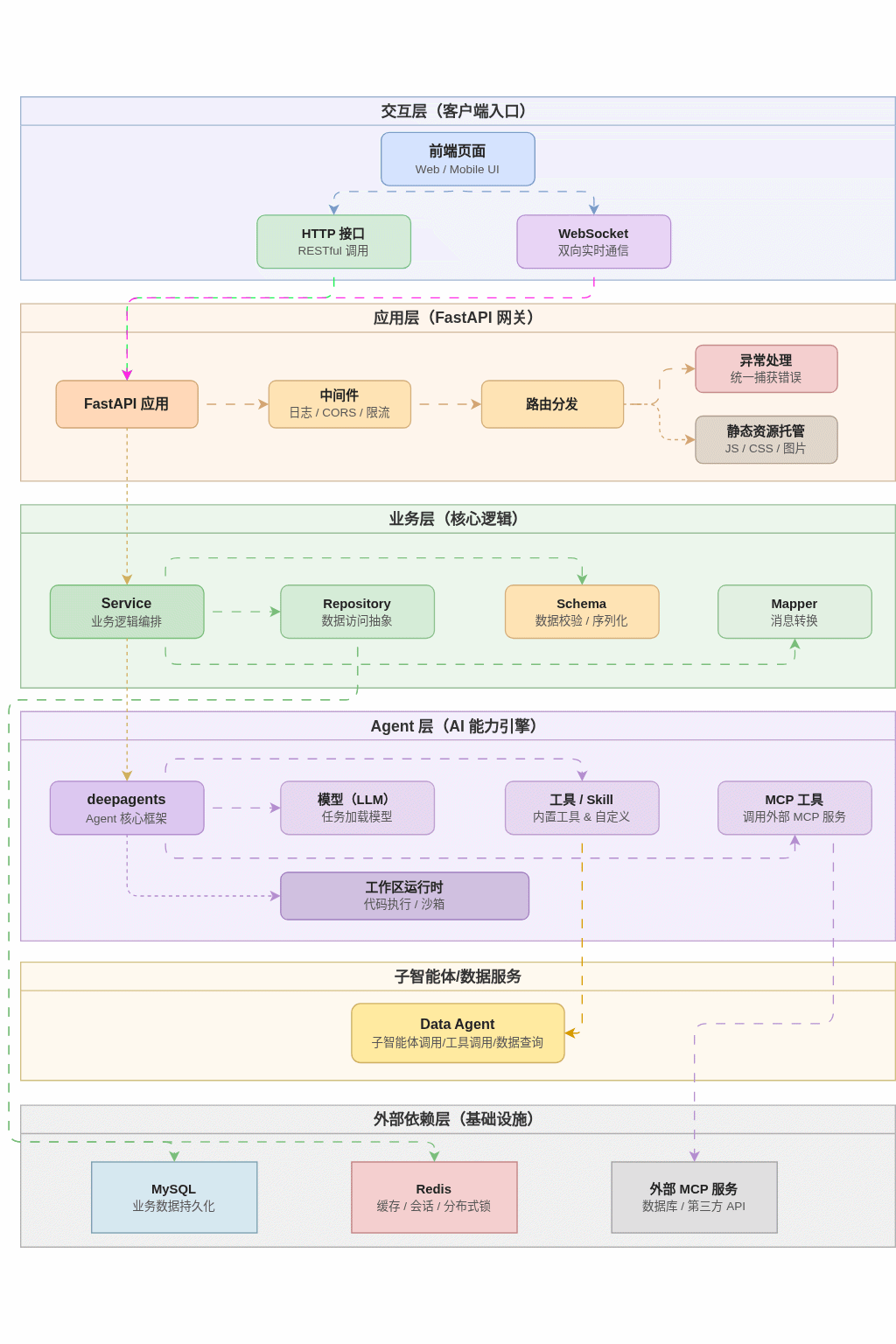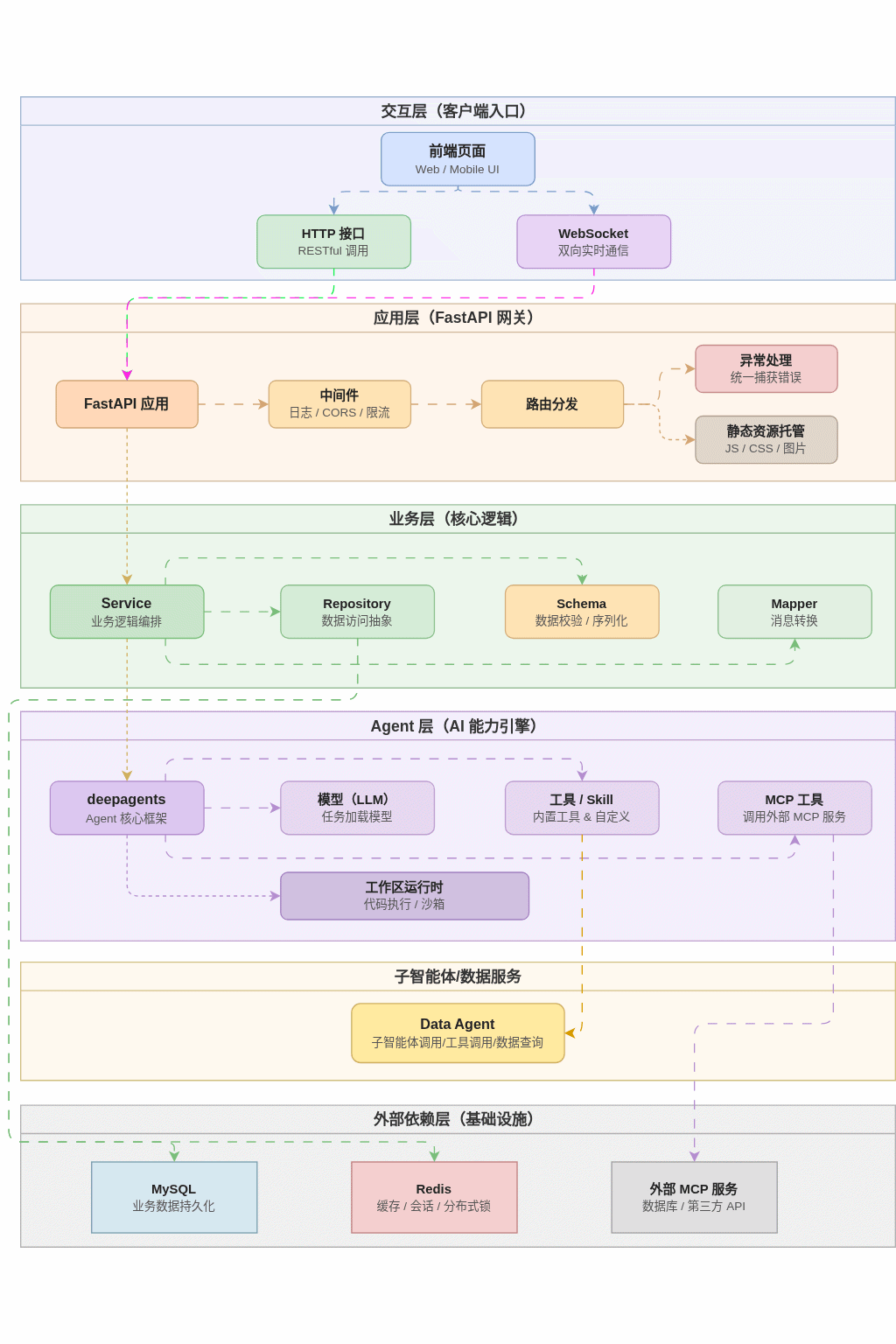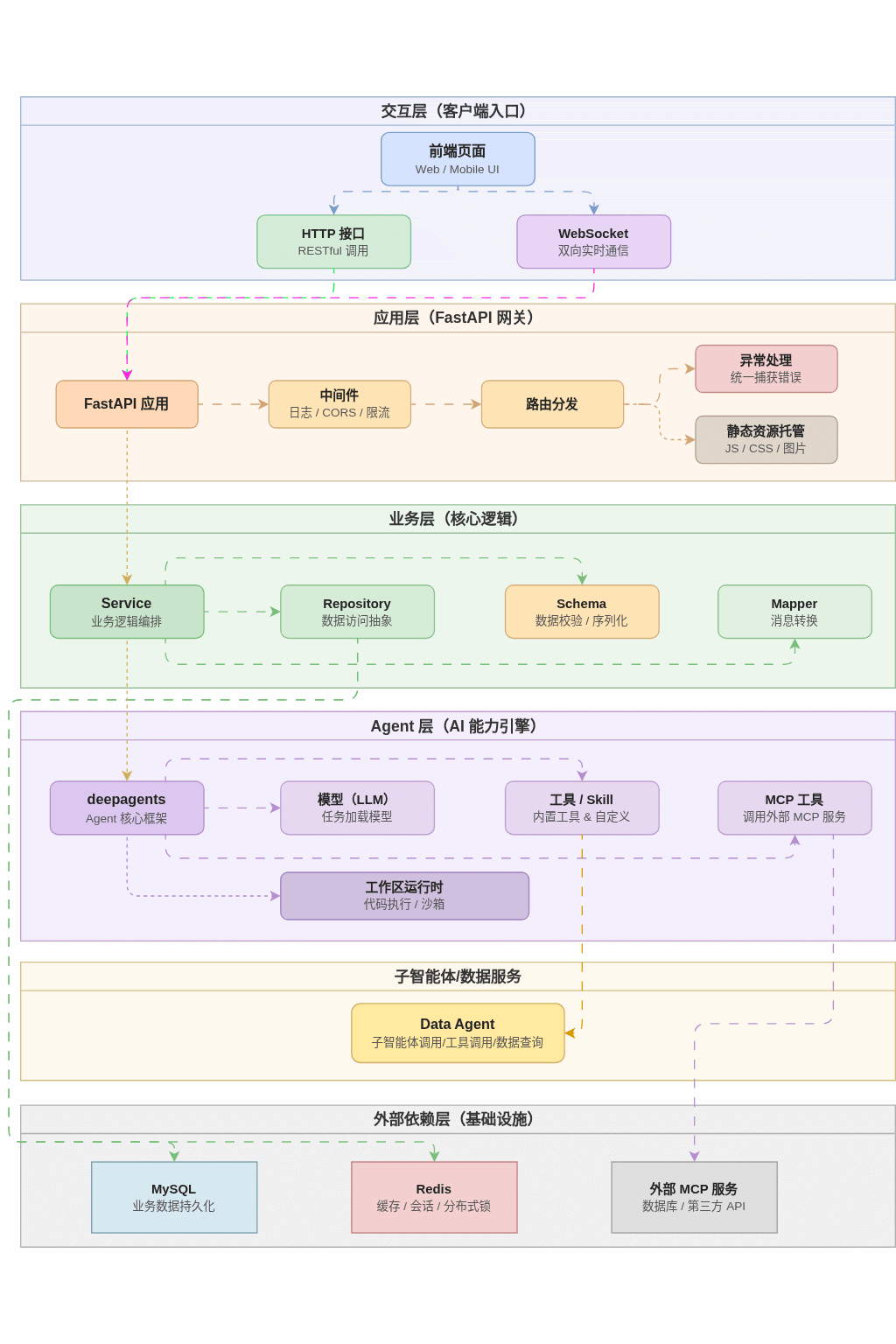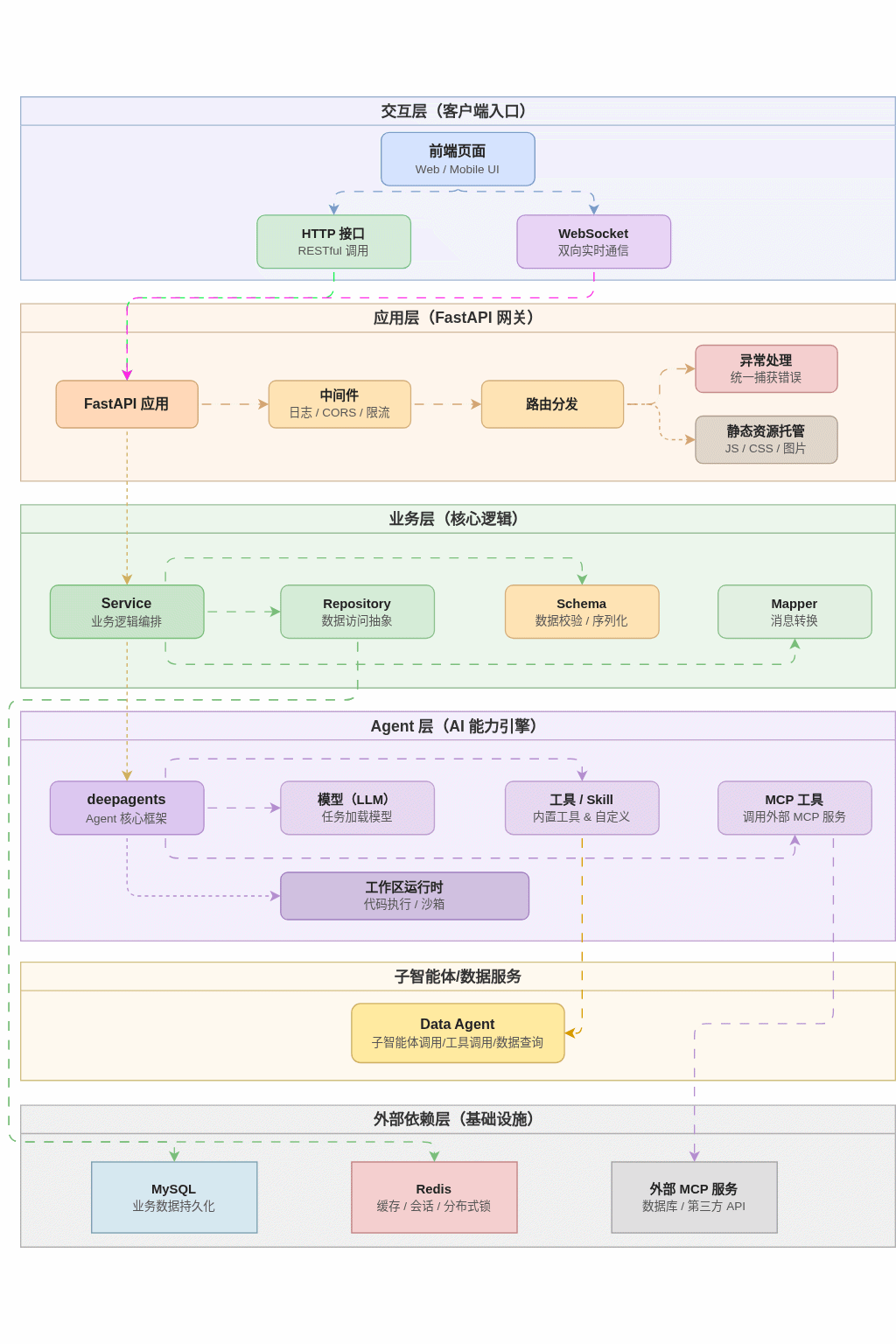
本项目整体分为交互层、应用层、业务层、Agent层、外部依赖层,共五层。
交互层:React 前端页面、WebSocket 实时通信、HTTP 接口请求#
应用层:FastAPI 主服务、路由分发、全局中间件、异常捕获、静态资源托管#
业务 & Agent 层:Service 业务服务、Repository 数据访问、Schema 消息结构、Mapper 格式转;DeepAgents 运行时、模型、工具、Skill、工作区、MCP#
数据层:MySQL 存储会话 / 消息 / 上下文记录、Redis 存储临时 WebSocket Token、缓存状态#
外部依赖层:认证服务、Data Agent、MCP 服务、MySQL、Redis 为系统提供鉴权、数据、扩展能力和存储支持#
技术架构设计#
Q技术架构#
- 后端:Python + FastAPI + SQLAlchemy + Redis
- Agent 引擎:deepagents + LangChain + 大模型
- 前端:React + TypeScript + Vite + Zustand + shadcn/ui
- 存储:MySQL(会话 / 消息)、Redis(Token / 缓存)
- 通信:HTTP + WebSocket 全双工流式推送
- 部署:可容器化部署,环境统一配置
Q关键技术选型#
实现流程图#
Q系统总流程#
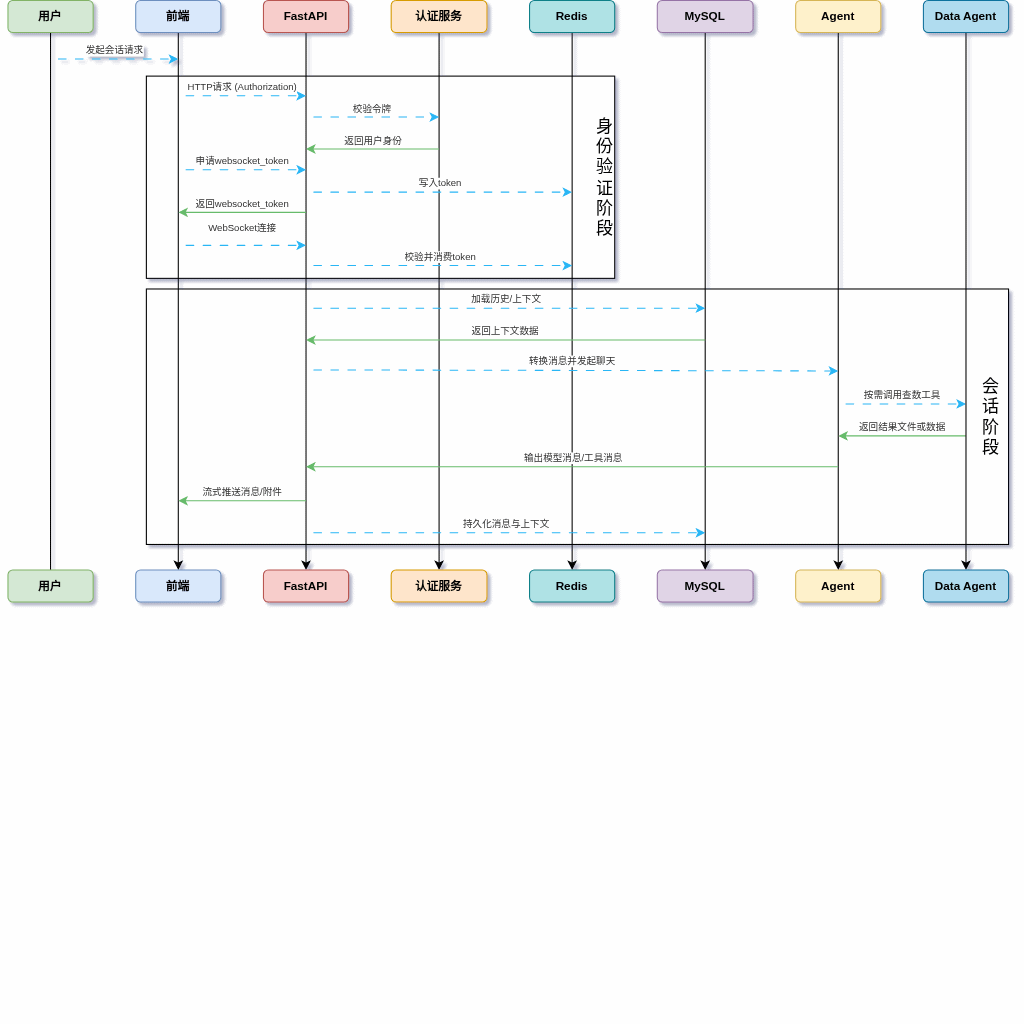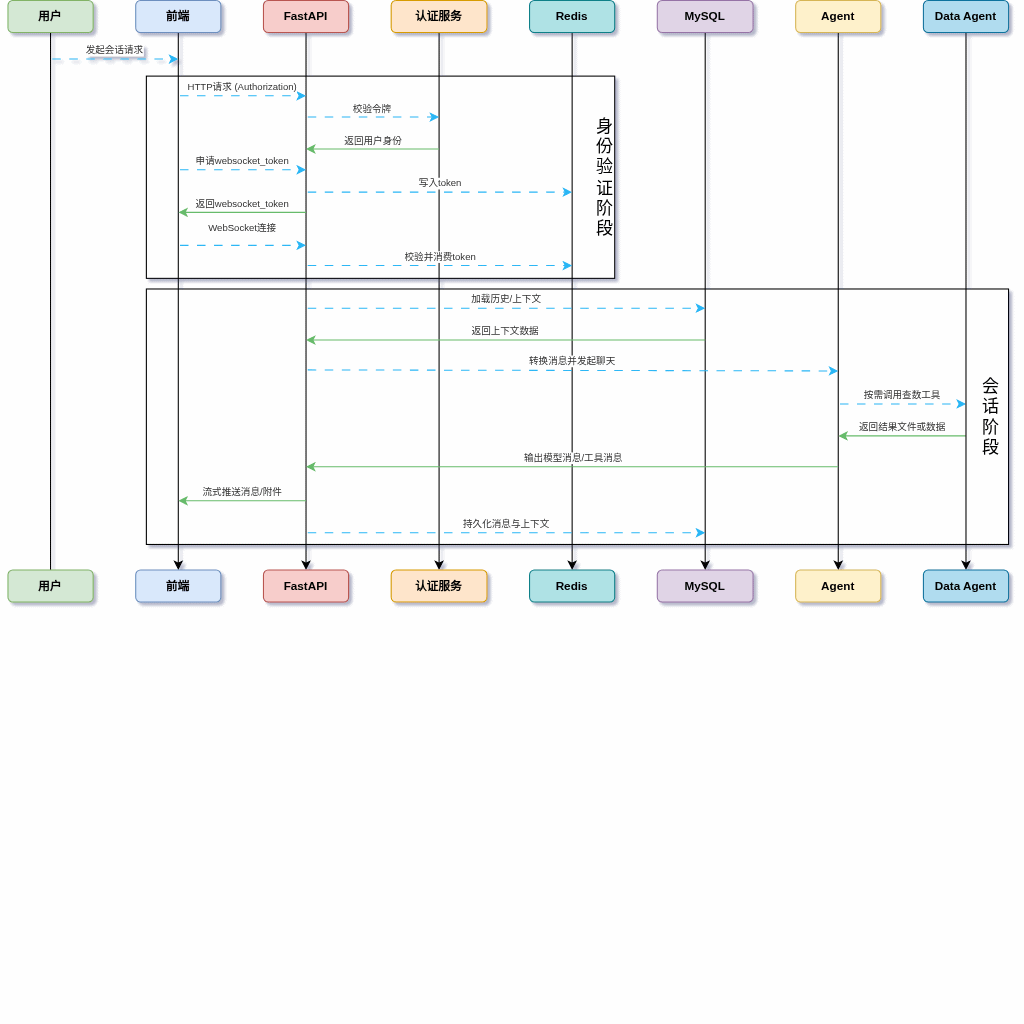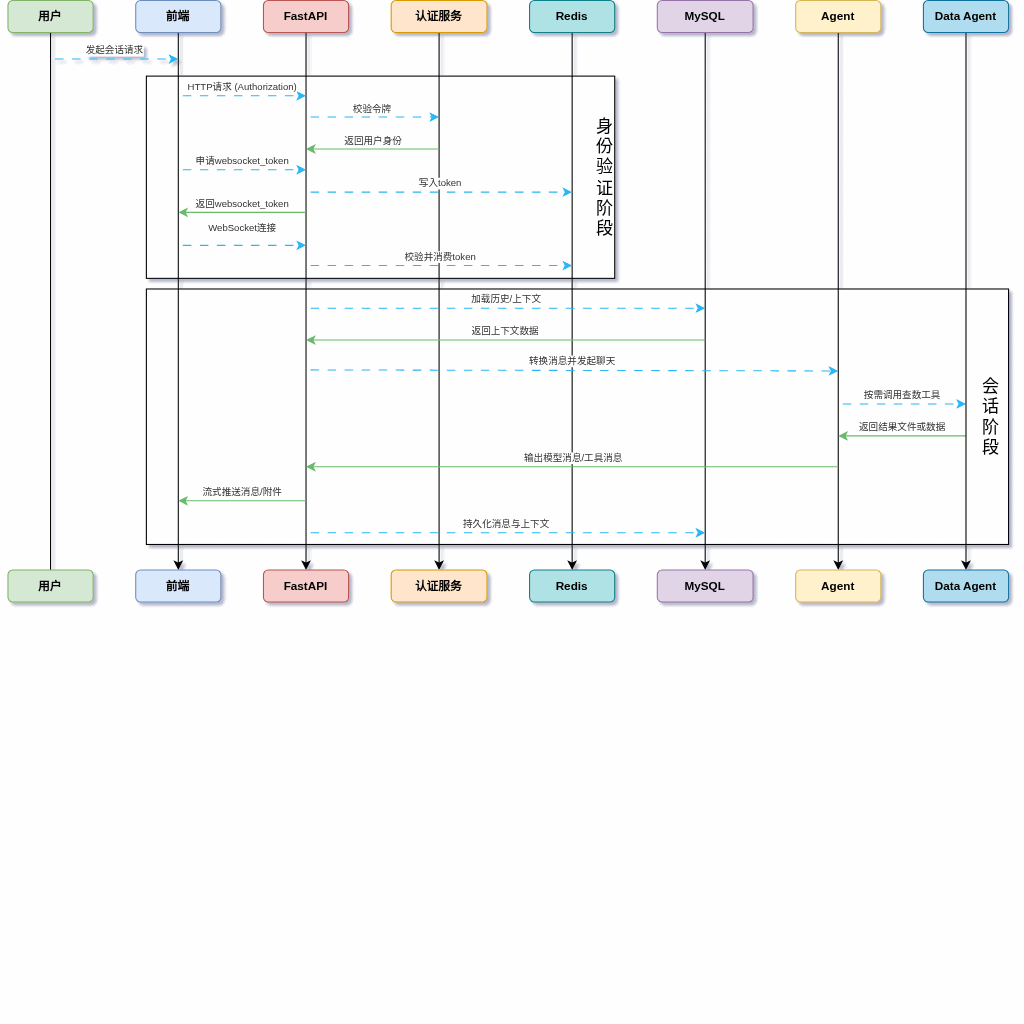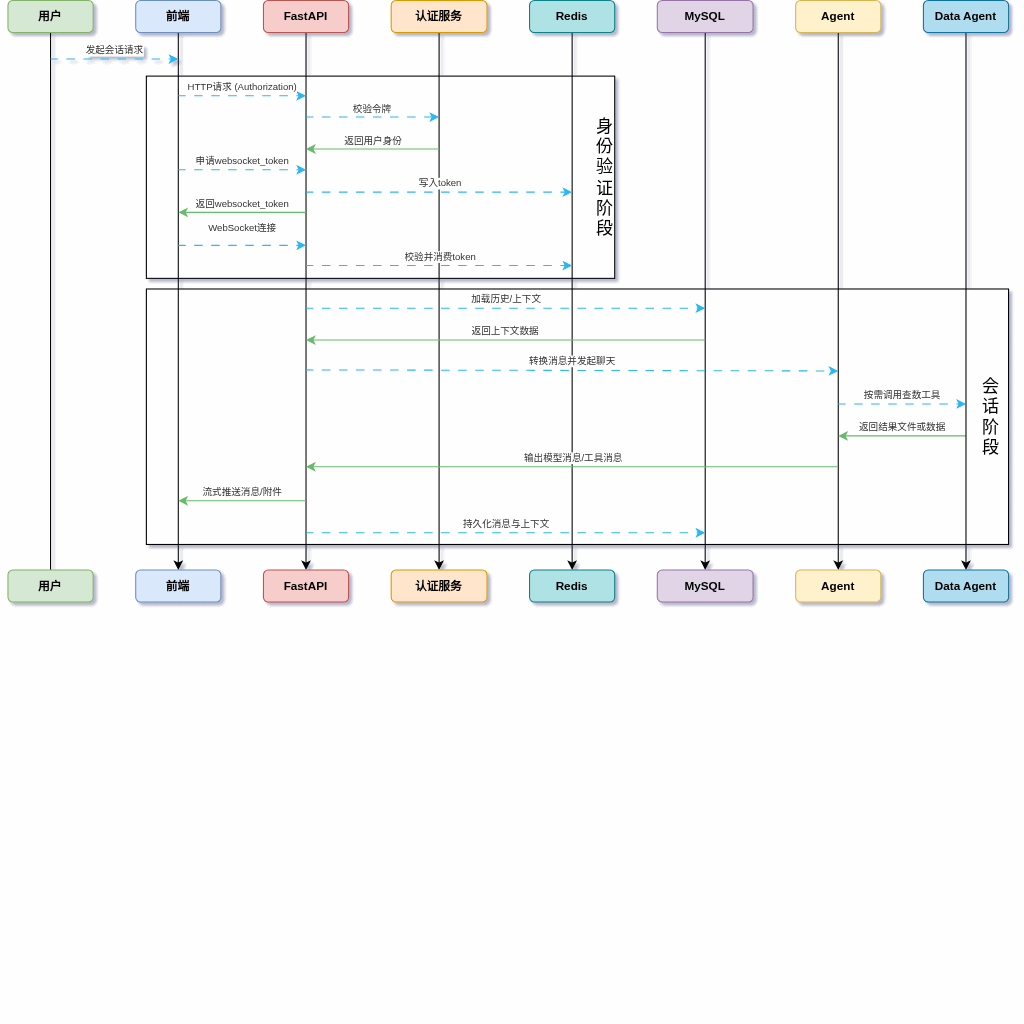
用户登录 → 鉴权服务校验身份#
前端创建会话#
前端申请 WebSocket 一次性临时 Token#
携带 Token 建立 WebSocket 长连接#
后端校验 Token、加载历史消息 + 压缩摘要#
用户发送归因分析问题#
Agent 触发 insight Skill(洞察技能) 进入标准归因流程:
拆解分析目标#
调用db_query数据库查询工具,使用自然语言查业务数据库#
数据落工作区 CSV/JSON#
使用Pandas 做多维度、趋势、结构、贡献拆解#
识别波动、季节、供应链、库存风险#
生成结构化报告 JSON#
自动渲染 ECharts 可视化 HTML#
流式推送:模型文本、工具调用、数据预览、报告文件#
消息自动落库、上下文增量压缩#
支持随时继续追问、复用历史数据和报告#
关键实现细节#
Q会话与工作区机制#
- 每个用户每个会话独立隔离工作区
- 隔离优势:不同会话文件互不干扰、历史永久沉淀、可随时回溯复用
- 支持草稿会话:先上传附件、后发消息自动转正式会话
Q三大自定义核心工具#
db_query数据库查询工具#
- 接收自然语言查询需求
- 调用Data Agent生成SQL查询业务库
- 支持60万+条大数据量查询
- 自动区分表格/非表格数据,分别存CSV/JSON
- 返回预览数据、字段、Pandas 读取提示
return_file文件返回工具#
- 从会话工作区读取文件
- 防路径逃逸安全校验
- 封装附件结构给前端渲染
MCP 工具接入#
统一适配多种传输协议,可批量接入外部工具
QInsight Skill 技能约束#
强制约束 Agent 不能自由闲聊,必须按专业归因流程执行#
触发条件:用户问为什么、下滑原因、复盘、分析、诊断#
强制步骤:查数→清洗→多维拆解→基线对比→异常识别#
强制维度:时间 / 渠道 / 品类 / 地域 / 用户 / 供应链#
强制产出:中间分析文件 + 标准化 HTML 报告#
强制规范:统一使用 uv 管理 Python 环境,禁止随意 pip#
报告强制结构:摘要、指标卡、多维图表、归因结论、业务建议#
约束的内容主要包括:#
任务进入条件:当问题属于归因分析、经营诊断、活动复盘、营销分析等场景时,按分析模式推进,而不是只返回一条查询结果#
数据获取方式:数据库数据统一通过 db_query 获取,后续分析优先基于查询结果文件继续处理#
执行环境约束:工作区内的 Python 命令统一使用 uv run,依赖安装统一使用 uv add#
分析动作约束:默认补齐基线对比、规模拆解、结构拆解、效率拆解、贡献拆解和异常识别#
分析维度约束:围绕用户、渠道、商品、优惠、地域、时间、行为等维度展开,并按场景补充交叉分析#
文件产物约束:原始查询结果、中间分析文件和最终交付文件分别落到约定目录中,便于继续分析和回传#
报告交付约束:详细分析场景默认输出 HTML 报告,并包含摘要、指标卡片、多维拆解、结论与建议等结构#
最终回复约束:回复中需要交代分析问题、数据来源、归因结论和生成文件#
Q三层消息架构设计#
项目采用三种消息格式双向映射,彻底解耦:
Agent 运行时消息:HumanMessage/AIMessage/ToolMessage#
前端交互消息:MessageSchema(文本 / 图片 / 工具调用 / 附件分离)#
数据库存储消息:Entity JSON 序列化落库#
通过 Mapper 实现互相转换,新增消息类型无需改底层架构。
Q上下文自动压缩#
- 长对话自动摘要合并历史
- 替换早期冗余消息,大幅降低 token 消耗
- 重连自动加载最新摘要,保留业务逻辑不丢失
项目成果#
完成企业级大模型归因分析智能体全栈落地#
支持60 万 + 条业务数据自动查询与多维分析#
实现指标波动、季节性、供应链、库存风险自动识别#
全套会话、消息、附件、报告、流式聊天闭环#
输出标准化可视化 HTML 报告,可直接业务汇报#
架构模块化、可快速扩展新行业、新分析场景#
降低业务数据分析门槛,不懂 SQL 也能做专业归因#
分析过程永久沉淀,可回溯、可复用、可迭代#
标准化报告输出,统一业务分析口径#
实现工作区、Skill 约束、三层消息、上下文压缩工程化方案#
面试高频问题与回答#
Q技术难点#
难点1:Agent不按流程分析,随意回答#
问题:大模型容易偷懒,只给简单结论,不查数、不拆维度、不做图表。
解决:通过Insight Skill强约束,定义严格工作流、必须步骤、必须维度、必须产出,强制遵循专业归因流程。
自研 Insight Skill 技能约束:把归因分析的完整流程、必须步骤、强制维度、输出规范全部固化到 Skill 中,成为智能体的 “行为准则”。#
流程强制化:明确规定,当用户提出归因分析类问题时,必须执行查数、数据清洗、多维度拆解、基线对比、异常识别、结论输出、生成报告的完整流程,禁止直接闲聊。#
产出强制化:强制要求输出结构化的中间数据文件、分析结果 JSON,以及标准化的 HTML 报告,否则视为流程未完成。#
难点2:长对话上下文越来越长,成本高、响应慢#
问题:多轮追问后历史消息暴涨,Token成本高、推理慢。
解决:实现自动上下文摘要压缩,把早期对话合并为摘要,保留核心业务信息,控制上下文长度。
实现上下文自动压缩机制:对早期的多轮对话进行自动摘要,将冗长的历史消息压缩为精简的业务摘要,保留核心分析目标、关键结论和数据口径。#
动态触发压缩:当对话轮次超过阈值时,自动触发压缩流程,用摘要替换原始长消息,控制上下文长度在合理范围。#
摘要持久化:压缩后的摘要单独存储,会话重连时先加载摘要,保证业务逻辑的连续性。#
难点4:大模型直接生成HTML报告格式混乱#
问题:LLM不擅长排版,标签错乱、布局丑陋、无法复用。
解决:引入报告中间IR层,模型只负责生成业务结构,后端统一渲染标准HTML+ECharts。
引入 报告中间 IR 层:定义一套结构化的报告中间表示(IR),包含指标卡、折线图、柱状图、表格、文本段落等模块,让大模型只负责生成符合规范的 IR 结构。#
后端统一渲染:开发独立的报告渲染引擎,根据 IR 结构自动渲染带 ECharts 图表的标准化 HTML 报告,样式完全可控。#
支持多格式导出:基于同一套 IR,后续可以扩展生成 Markdown、PDF 等多种格式的报告。#
难点5:海量60万级数据查询与分析性能问题#
问题:数据量大,查询慢、内存占用高。
解决:基于DataAgent分页查数、结果落文件、Pandas按需分析,避免全量加载。
采用一次性临时Token方案:用户先通过 HTTP 接口申请 WebSocket 临时 Token,该 Token 与用户身份、会话绑定,仅能使用一次,有效期极短。#
连接校验:用户携带临时 Token 建立 WebSocket 连接,后端校验通过后立即销毁 Token,防止重放攻击。#
会话级权限控制:连接建立后,基于用户身份和会话 ID 进行权限校验,保证用户只能访问自己的会话数据。#
Q核心技术类问题#
项目中使用的 DeepAgents + LangChain,你理解的核心原理是什么?#
回答:
DeepAgents 是基于 LangChain 封装的智能体运行时框架,核心原理是通过「模型+工具+记忆+控制流」的组合,让大模型能够执行复杂的业务任务。在项目中,主要利用了它的几个核心能力:
工具调用能力:支持模型调用数据库查询、文件返回等工具,实现数据查询和文件操作。#
工作区隔离:每个会话有独立的工作区,保证不同会话的文件互不干扰、可沉淀。#
Skill约束机制:通过 Skill 定义智能体的行为准则和执行流程,强制模型按规范执行。#
上下文管理:支持多轮对话的上下文维护,也方便我们接入自定义的上下文压缩逻辑。#
上下文压缩的具体实现逻辑是什么?#
回答:
触发条件:当对话轮次超过阈值,或者上下文 Token 数超过上限时,自动触发压缩。#
摘要生成:将早期的多轮对话发送给大模型,让模型生成精简的业务摘要,包括分析目标、关键数据、核心结论和后续需要解决的问题。#
替换与存储:用摘要信息替换原始消息,保留近几轮对话,注入上下文并存储到数据库。#
会话重连恢复:重新连接会话时,加载最新的摘要和最近消息,保证业务逻辑的连续性。#
Q项目设计类问题#
为什么要设计三层消息映射架构?直接用一套格式不行吗?#
回答:
不同场景下的消息需求差异很大:
Agent 运行时:需要支持工具调用、工具结果、图片等复杂类型。#
前端交互:需要结构简单、易解析,方便渲染文本、工具调用状态、附件等内容。#
数据库存储:需要可序列化、可扩展,方便后续回溯和审计。#
如果直接用一套格式,会导致格式臃肿、扩展性差、维护成本高。
三层架构通过 Mapper 转换层实现了解耦,各司其职,扩展性和可维护性都大幅提升。
会话级工作区机制的设计思路是什么?解决了什么问题?#
回答:
工作区机制的核心设计思路是「会话级文件隔离 + 过程沉淀复用」。
- 每个用户的每个会话都有独立的文件目录。
- 会话过程中产生的所有文件,包括查询结果 CSV、分析过程 JSON、生成的 HTML 报告,都存储在对应的工作区中。
主要解决了文件隔离、过程沉淀、复杂分析支持三个问题。
Q项目落地与优化类问题#
项目中做了哪些性能优化?效果如何?#
回答:
主要做了这五类优化:
上下文压缩优化:降低 60%的上下文长度,降低Token 成本,降低约 40%推理延迟。#
大数据量处理优化:采用分页查询+文件落盘+按需分析,大幅缓解内存占用压力。#
异步非阻塞优化:使用FastAPI的异步特性,提升了IO 操作等服务的并发处理能力。#
缓存复用优化:缓存数据查询结果,避免重复查询,减少Data Agent服务的调用压力。#
日志与链路优化:优化日志输出,同时通过链路追踪快速定位性能瓶颈。#
系统的响应速度和并发能力都大幅提升,能够稳定支撑业务高峰期的使用。
项目上线前做了哪些测试?遇到过什么问题?#
回答:
做了多轮测试:
单元测试:对核心工具、上下文压缩等多个模块进行单元测试,保证功能正确性。#
联调测试:和前端、数据团队进行全链路联调,解决了多个环节的兼容性问题。#
压测:对 WebSocket 连接和并发场景进行压测,优化了连接池和异步处理逻辑,解决了高并发下的连接不稳定问题。#
业务场景测试:邀请业务人员进行测试,收集反馈并优化了分析流程和报告生成逻辑。#
项目上线后,如何保证系统的稳定性?#
回答:
主要通过这几方面来保证稳定性: