项目周期#
- 2人团队,总计约5.5个月。
- 需求分析与技术选型2周
- 环境搭建与熟悉框架3周
- 基础任务流开发与集成4周
- 测试与部署2周
- GraphRAG流程开发1周
- 集成与调试2周
- LLM微调数据准备2周
- LLM微调与评估1周
- 模型部署与测试2周
- 更多任务流扩展4周
功能介绍
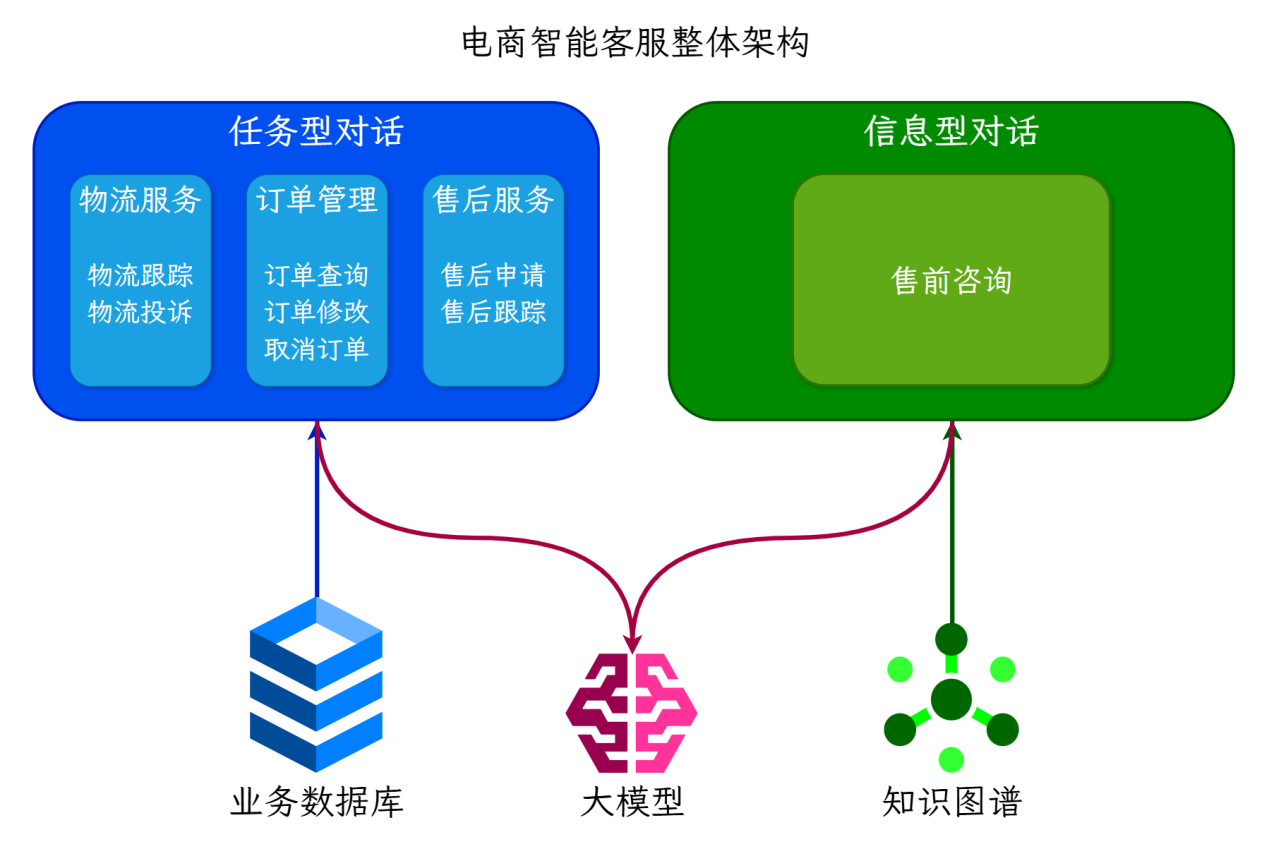
基于Rasa Pro框架结合LLM和知识图谱构建的智能电商客服系统,主要有以下功能:
提供任务型对话,根据预设流程进行对话,通过多轮对话交互帮助用户完成特定任务,如物流、订单、售后相关业务流程等。
提供知识库问答对话,基于知识图谱和GraphRAG,支持售前产品咨询的复杂问题和多跳推理。
支持意外对话修复和闲聊,接入LLM支持用户的非业务对话,并对回复内容做出严肃限制,避免涉及敏感内容的回复。
实现流程#
Q调用流程#
部署服务:Rasa Pro + LLM(vllm部署) + 知识图谱(neo4j)+ Embedding模型(fastapi+uvicorn)
后端服务:Rasa提供restful接口,供前端调用。
前端服务:公司自研web、app,调用后端服务。
Q实现流程#
用户query
=》Rasa对话理解(读取tracker store,调用LLM)
=》Rasa对话管理器(执行flow或者pattern)
-》匹配到flow,执行flow和对应的action,返回结果
-》未匹配到flow,执行pattern_search -> 执行企业搜索策略 -> 调用GraphRAG
-》标签路由:LLM识别问题涉及的节点类型和实体
-》节点检索:使用混合检索找到候选入口节点
-》Cypher生成:LLM根据入口节点和问题生成Cypher查询语句
-》语句验证:验证Cypher语句的正确性
-》语句校正:如有错误则进行校正
-》执行查询:在Neo4j中执行Cypher查询
-》返回结果:将查询结果返回
-》pattern_search无结果-》最终回退到pattern-chat闲聊
-》更新tracker store:添加新对话、更新slot等
=》Rasa NLG:将结果输入到LLM上下文,由LLM生成回复
技术细节#
QRasa Pro框架介绍#
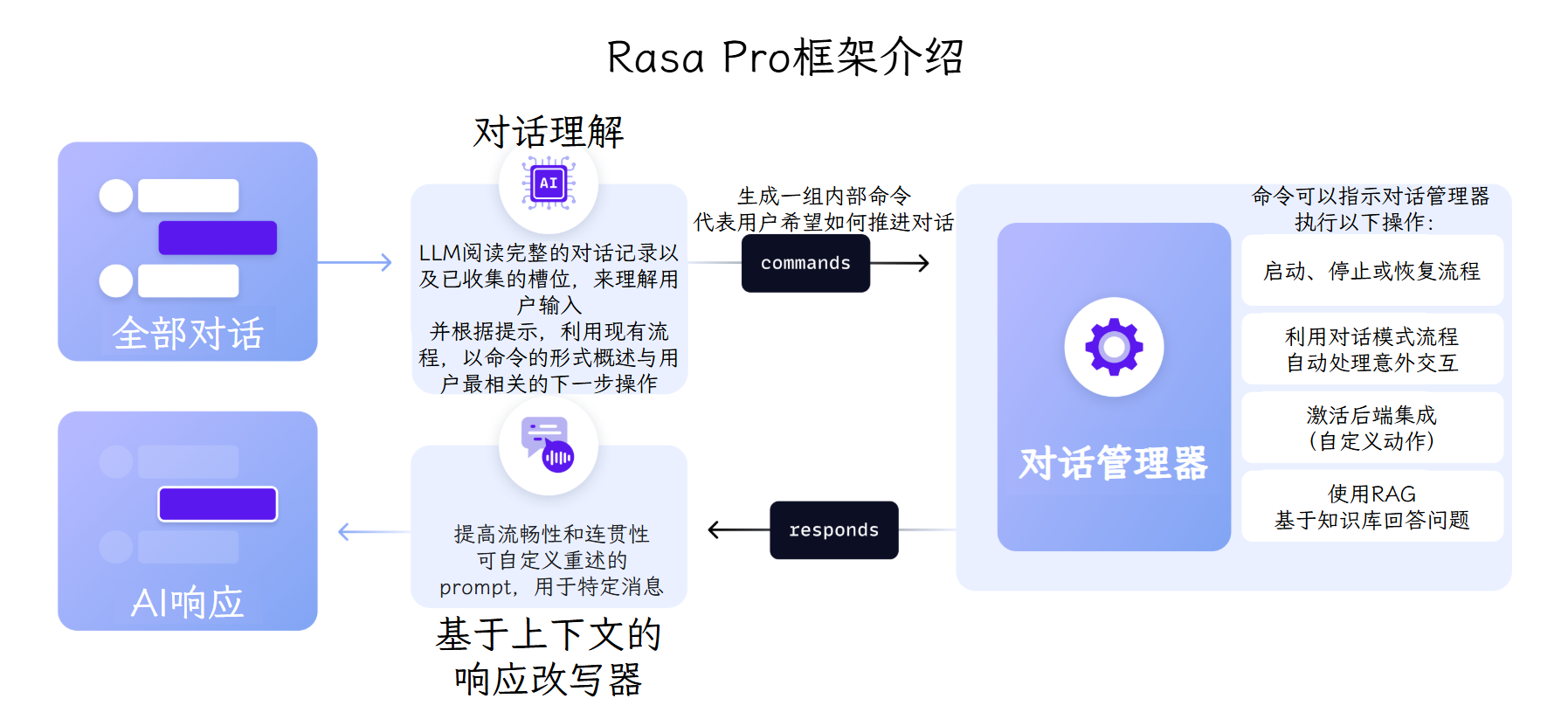
CALM由三部分组成:对话理解、对话管理、响应生成#
对话理解#
当用户发送消息时,LLM命令生成器从tracker store读取完整对话记录与已收集的信息,调用LLM,识别用户意图、提取槽位,并生成下一步的命令列表,发送给对话管理器。
这里prompt的内容包括:
① 任务描述
② 可用的Flows和Slots(开启流程检索,只放匹配度高的几个流程)
③ 可用操作:start flow、set slot、search and reply等
④ 通用指令:指令+描述
⑤ 决策规则表:满足xx条件,触发xx指令=》生成xx命令
⑥ 当前状态:活跃的flow、当前请求的slot和已填充的slots等
⑦ 对话历史
⑧ 要求生成最新命令序列
这里使用的SearchReadyLLMCommandGenerator,可以触发RAG。
对话管理#
对话管理器接收命令序列,采取下一步操作:
启动、停止或回复流程
对话模式流程处理意外交互
执行企业搜索RAG
收集信息
触发action
响应生成#
利用上下文响应重述器,生成自然的回复,提高对话的流程性和连贯性。
这里配置了LLM进行对执行结果的重述响应。
Rasa构建AI助手流程#
配置rasa:pipeline、policy、endpoint等#
根据业务设计和用户行为设计流程。#
编写流程中设计的槽位、响应、动作等。#
自定义动作通过继承Action类并重写run方法来实现,可以调用外部API,查询数据库或执行其他逻辑。
槽位和对话历史会自动存储在track store中。
训练并调试助手。在调试过程中将对话保存为端到端测试示例。#
微调小型语言模型用于执行命令生成任务。将其部署并集成到Rasa中。#
Q任务型对话#
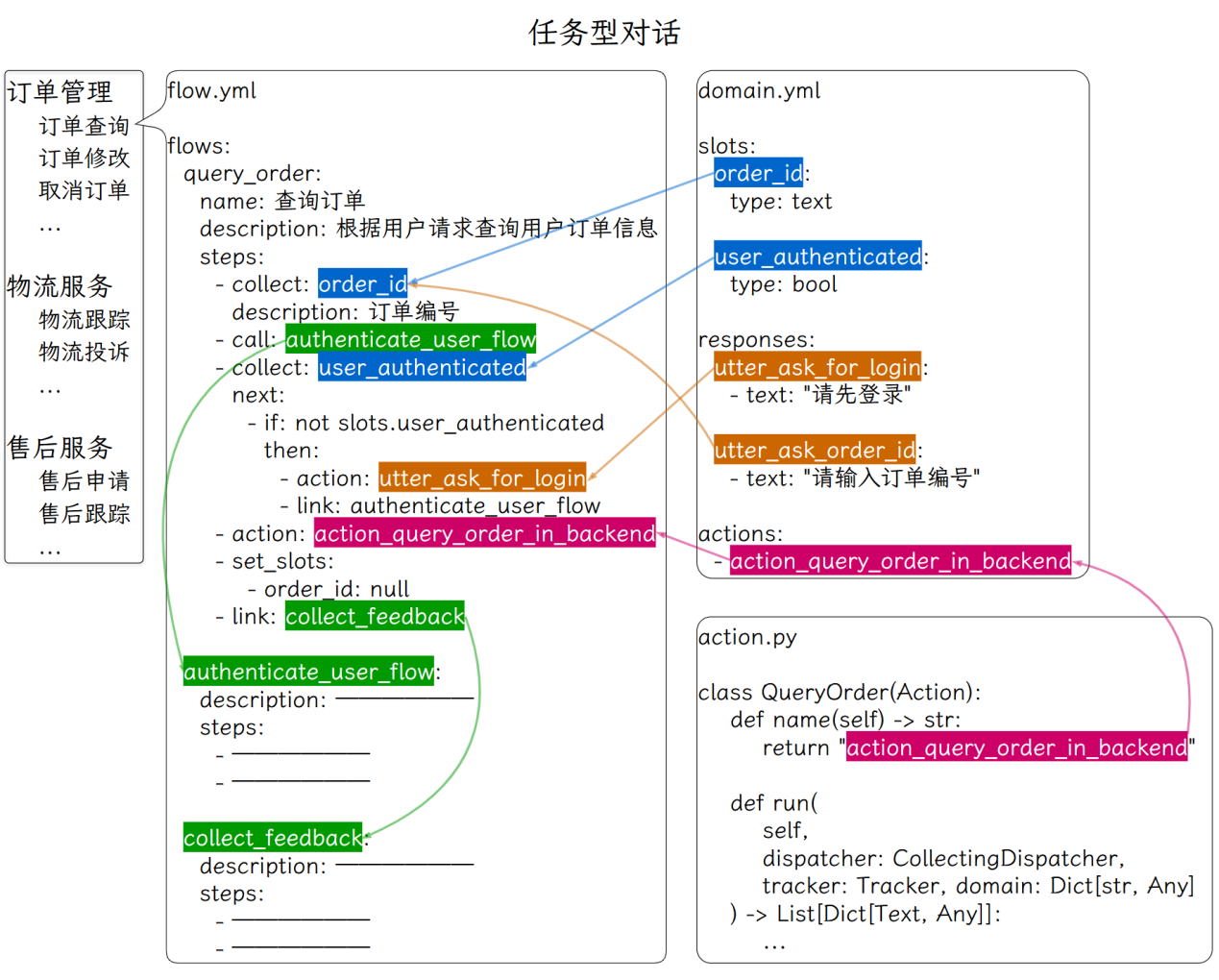
在流程中定义一个业务操作的各个步骤。
通过槽位存储操作过程中所需的信息。
通过定义响应来引导LLM如何回复用户。
通过编写自定义动作来调用外部API,查询或操作业务数据库,来获取业务相关信息或执行用户操作。
Q信息型对话#
结合知识图谱与GraphRAG,支持复杂的商品搜索、推荐、知识问答等功能。
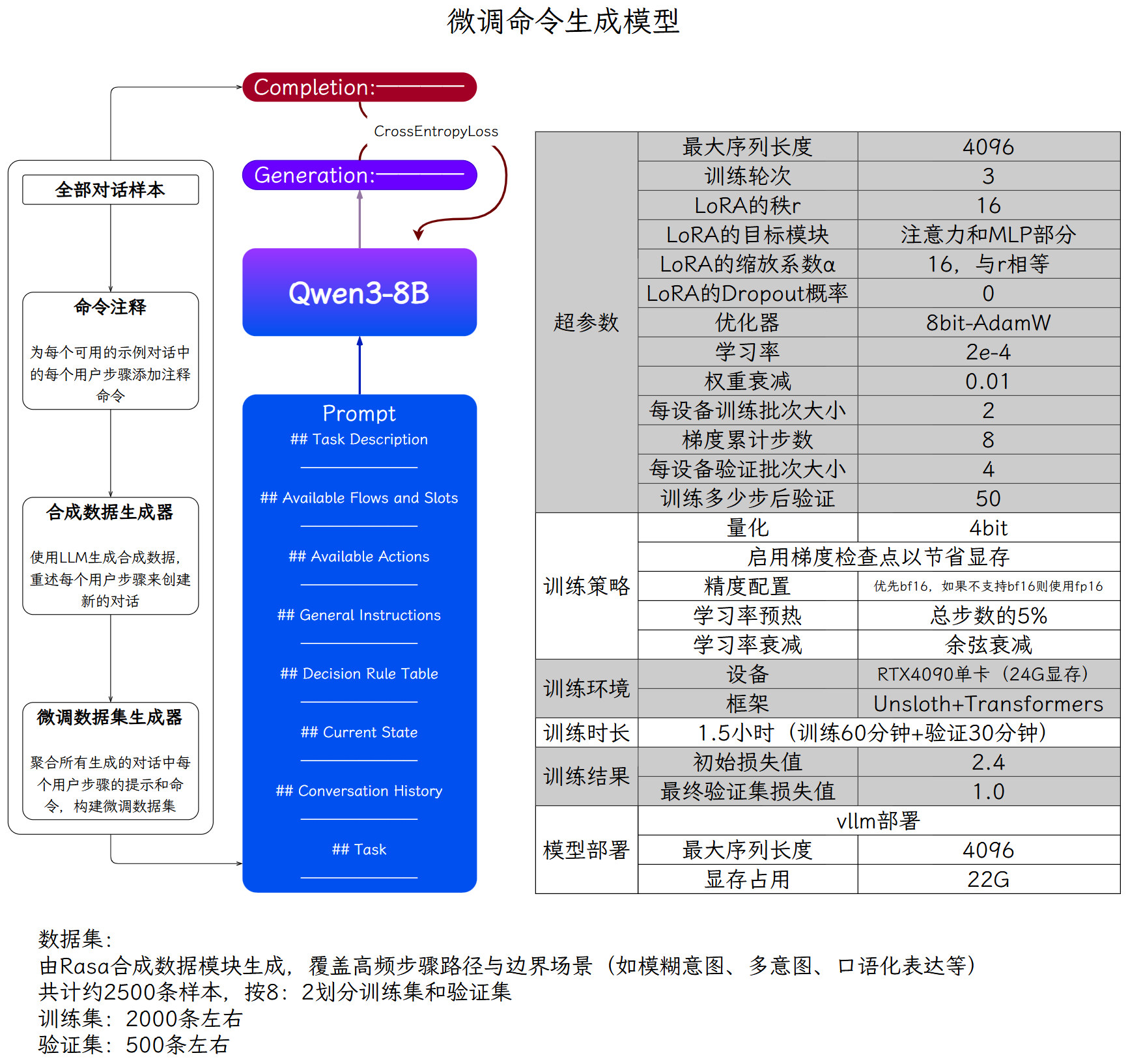
Q生成“命令生成模型”的微调数据#
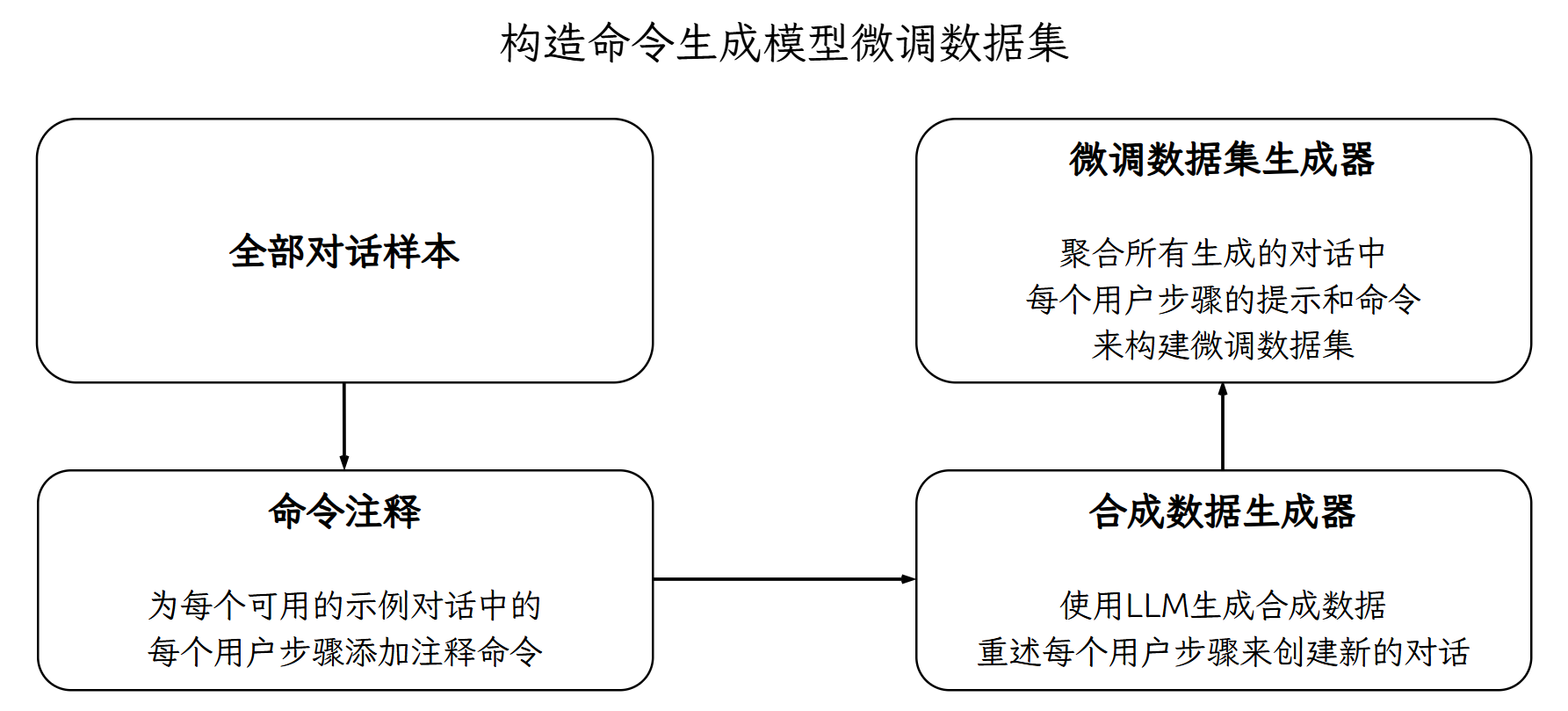
准备覆盖重要对话流程的端到端测试数据,执行rasa命令生成微调数据集。
Q命令生成模型微调与部署#
数据集#
由Rasa合成数据模块生成,覆盖高频步骤路径与边界场景(如模糊意图、多意图、口语化表达等)。
共计约1万条样本,按8:2划分训练集和验证集。
训练集:8000条左右。
验证集:2000条左右。
模型训练#
Q信息型对话(GraphRAG)#
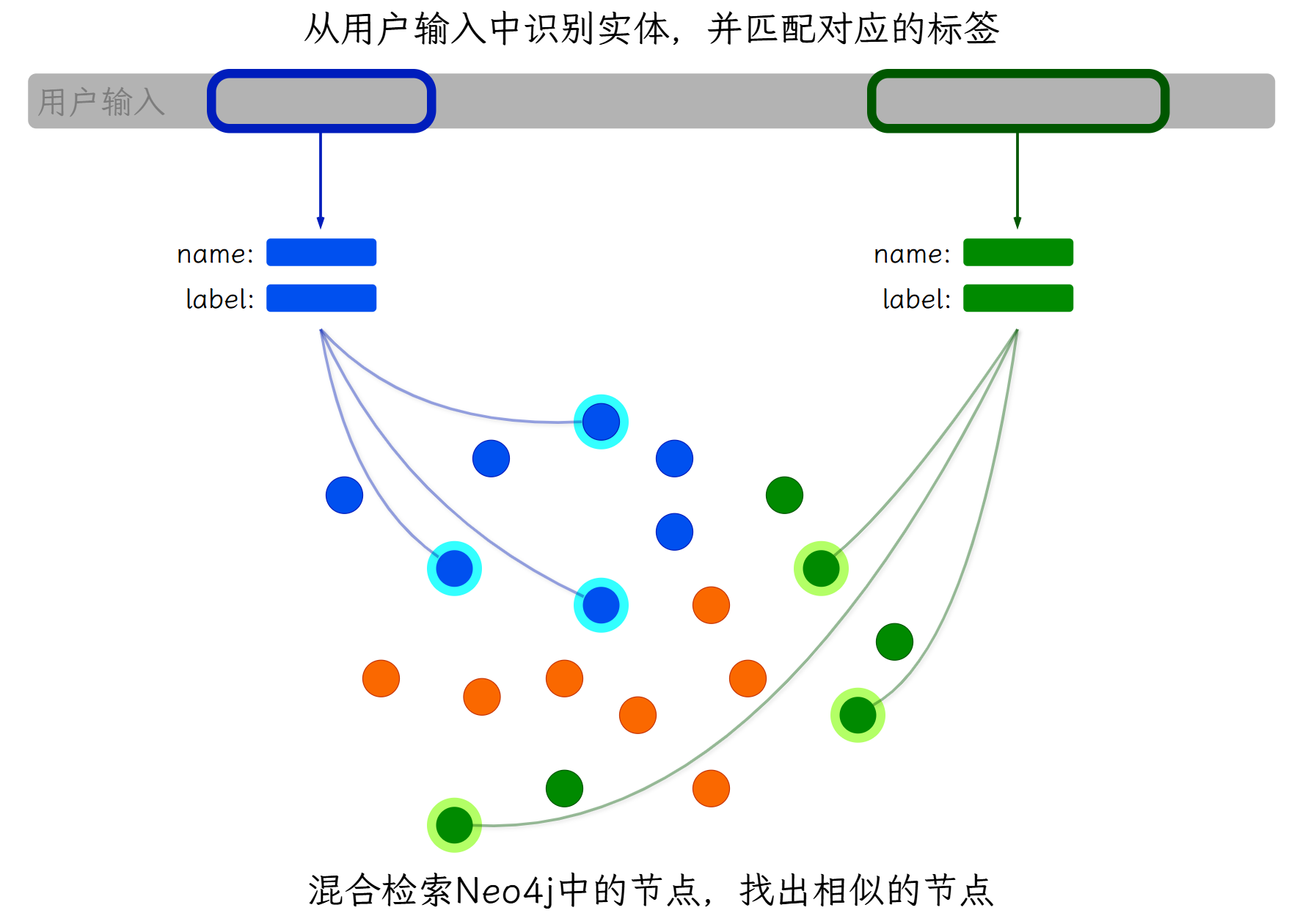
LLM根据Prompt从用户输入中提取入口节点实体和其对应的类型。
获取入口节点实体和标签之后,使用混合检索从Neo4j中检索出若干候选入口节点。
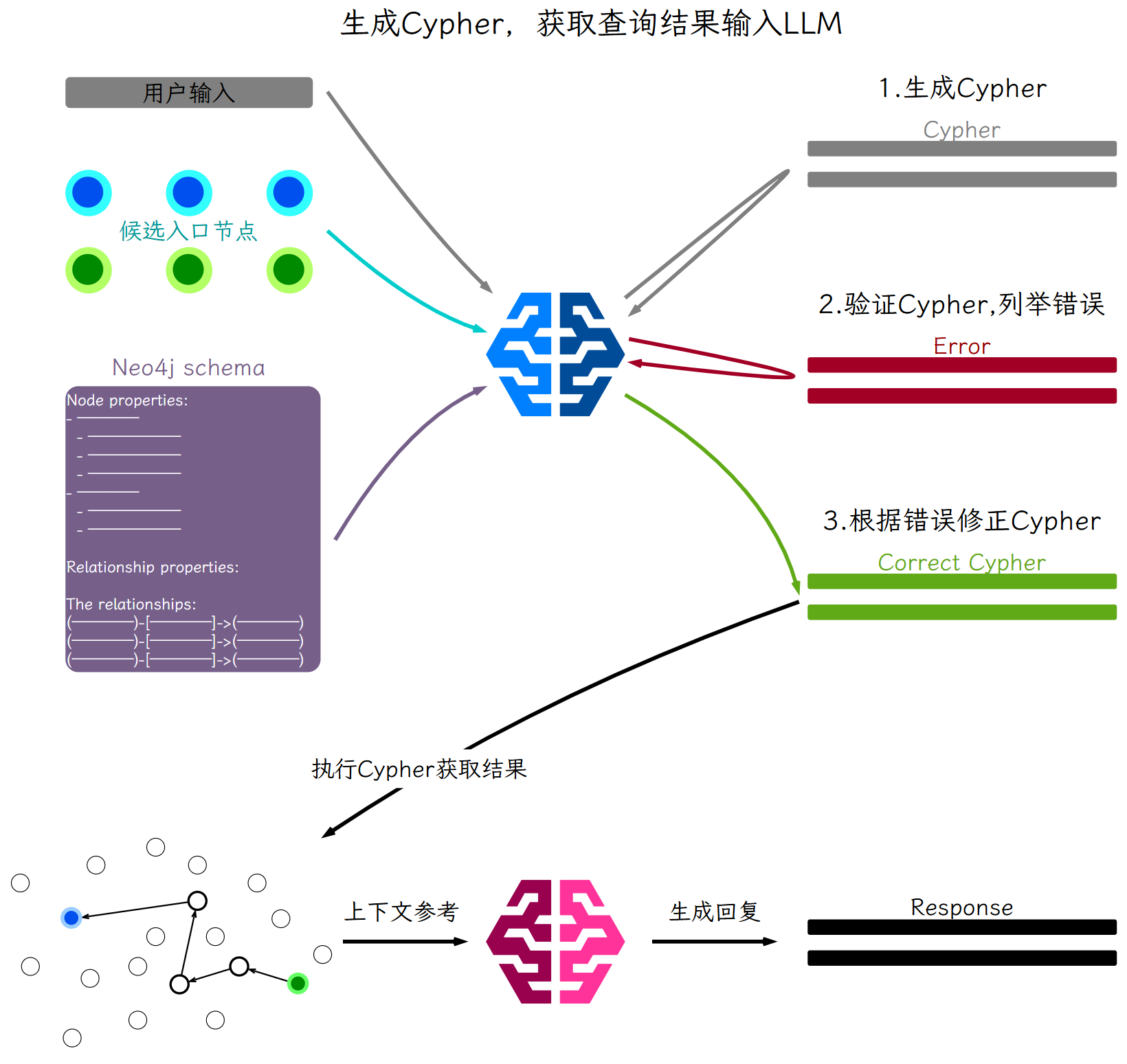
LLM根据用户输入、候选入口节点、Neo4j的schema信息,生成Cypher查询语句。
将生成的Cypher语句交给LLM进行验证,返回Cypher中的存在的语法与逻辑错误。
LLM根据验证出的错误信息对Cypher进行修正,得到最终的Cypher语句。
执行查询语句,将查询结果返回LLM作为上下文参考。
LLM根据用户输入和上下文参考生成回复。
项目总结#
该项目实现了基于Rasa Pro框架的智能电商客服系统,集成了大语言模型、任务型对话流程管理、知识图谱和GraphRAG。
能够自动化处理售前咨询、订单管理、物流查询、售后服务等核心业务场景,提供高效的客户服务解决方案。
项目主要包含任务型对话部分和信息型对话部分,支持闲聊。
任务型对话针对结构化的目标导向任务,如查询订单或修改地址,通过预定义流程管理输入输出。
信息型对话则集成RAG和GraphRAG,利用外部知识库响应用户问题,如商品搜索和推荐。
首先我们使用Rasa Pro框架构建AI助手,基于CALM(对话理解、管理、响应生成)设计流程。
在对话理解中,采用SearchReadyLLMCommandGenerator,根据prompt将用户消息转换为命令。多轮对话的对话历史、槽位信息由tracker store存储和更新。
prompt包括当前状态、对话历史、可用流程/槽位/动作、可用操作、决策规则等。
对话管理接收命令执行操作,如路由流程、收集信息、执行动作、或处理意外交互,通过对话模式(如修复、导航、外部支持)处理非线性对话。
响应生成利用上下文重述器生成自然回复。
构建流程时,在YAML文件中定义流程ID、描述和步骤,包括收集信息、执行动作、设置槽位等;编写槽位存储信息、响应引导回复、自定义动作调用外部API或数据库。
为优化命令生成并提高响应速度,我们准备了端到端测试数据,使用Rasa命令标注模块提取命令,合成数据生成模块创建重述版本,最终生成微调数据集。
数据集覆盖高频路径和边界场景,共计约1万条样本,训练集8000条、验证集2000条。
预训练模型选择Qwen3-8B,采用LoRA微调。训练时使用4bit量化、梯度检查点、bf16精度。每设备训练批次大小2,梯度累计步数8;使用Unsloth在V100单卡上训练。
之后使用vllm部署模型,最大序列长度4096。
对于信息型对话我们结合了知识图谱和GraphRAG。
LLM从用户输入提取入口节点实体和类型,使用混合检索从Neo4j中获取候选节点。
根据用户输入、候选节点和schema生成Cypher查询语句,之后LLM验证并修正语法逻辑错误。
得到修正后的Cypher语句后执行查询,将结果作为上下文参考生成回复。
结合任务型对话和信息型对话功能,最终实现了支持多场景的AI助手,可满足不同业务的需求。
疑难解析#
Q其他可用框架,Rasa Pro的选用原因。#
其他框架:LangChain、Langgraph、Rasa/Rasa Pro、Botpress、Amazon Lex
LangChain:是通用LLM应用开发框架,并非为客服专门设计,优势在于可编辑性强,自行结合各类大模型、Rag,生态丰富,是可以构建智能客服逻辑的,但无原生对话管理能力、状态管理、复杂多轮对话维护困难、缺乏可视化监控软件、更多的逻辑需要自行实现。这要求更高的工程能力,与更长的项目周期。
Langgraph:通用LLM工作流编排框架,更多地侧重于使用多agent去完成任务流的搭建,优势在于状态管理、上下文、可扩展LangChain,适合多Agent的电商客服系统。缺点在于框架新、生态不完善,缺少可视化工具、日志分析工具,以及多Agent带来的成本与延迟问题。
Rasa/Rasa Pro:成熟稳定、开源生态大,支持企业私有化部署、支持可视化流程,“意图识别+对话管理模块”的管理逻辑使得业务流逻辑严谨,适合复杂业务流,容易集成后端系统,并且具有银行、电商、运营商等场景的丰富应用案例。缺点在于,需要大量训练意图与实体、规则型设计多,缺少灵活性。
Botpress:Node.js可视化对话机器人平台,提供可视化流程,可低代码搭建,集成方便,可扩展API多。缺点在于LLM能力依靠插件扩展,流程编排复杂时可视化维护艰难,中文意图识别效果差,定制性差。
Amazon Lex:AWS(亚马逊云服务,Amazon Web Service)的对话机器人平台,支持语音与文本的输入,与AWS生态无缝集成,适合大规模部署,有丰富的企业级安全和日志支持。缺点在于灵活性不如开源框架、中文支持一般、成本回持续增长。
选用Rasa Pro,是出于工程性、稳定性的考虑。Rasa Pro框架提供强大的对话管理工具、支持多语言意图识别/实体识别能力、具有可视化对话管理工具rasa studio、支持非线性对话、私有化部署及本地部署模型调用,并且框架整体可控性较好(可自行调优意图识别、调优对话策略),发展(版本更新)也较为稳定。
Q客服系统常见业务评价指标#
500人左右的小公司-中小型电商团队
日均请求量QPS约5000-10000条;峰值10-15QPS
单次平均输出60-120tokens,复杂问题250tokens以内
响应时间1.2-1.5秒
1000-2000人左右的中大型公司
日均请求量QPS约50000-150000条;峰值40-80QPS
单次平均输出120-250tokens,复杂问题400tokens以内
响应时间0.8-1.2秒
推荐:准确率90-94%、召回率88-92%、拒识率5-10%
人工替代率取40-60%即可,智能客服主要替换标准化、高频、重复性强的人工操作,夜间工作场景。
Q对话管理怎么做的#
Rasa Pro的对话管理是基于“意图(Intent)+ 实体(Entity)+ 槽位(Slot)+ 策略(Policy)”的有状态流程管理。决策流程为“意图识别+实体抽取、槽位填充、根据策略与当前状态选择动作、执行动作、更新对话状态”。
Q意图识别怎么做的,如何接入大模型#
意图识别本质上是一个多分类任务,Rasa Pro会在config.yml中定义一个NLU PipeLine,通常会使用到Rasa Pro提供的DIETClassifier模型(百万参数的小模型),模型可以同时完成意图分类与实体识别。
LLM参与意图识别,可以与DIETClassifier模型结合使用,通常情况下由DIETClassifier模型进行意图识别,当意图识别的置信度低于阈值,则调用LLM进行意图推理与实体识别。
Q意图的数量,评价指标有哪些#
意图数量,根据业务场景定,中小公司2000-5000,中大型公司20000左右都是合适的数值。
意图识别需确保准确率超过90%,意图数量在复杂制造业中可能达几千。评估指标包括PRF(精确率、召回率、F1分数)。模型训练优化时需要分析哪些意图识别良好、哪些需优化,并针对弱意图调整训练数据或模型。
Q用户描述清洗的情况下,依然无法匹配正确工作流#
意图识别歧义、槽位提取不完整、工作流设计细致度不足、上下文感知不足,都可能会导致工作流无法正常匹配。
QGraph RAG的使用原因,使用方式#
相比于RAG,Graph RAG更关注于实体之间的关系,逻辑性更好,可以有效完成复杂关系的多条查询。Graph RAG帮助模型对私有数据集进行推理,效果更好。
推荐的回答是,RAG仍是客服系统检索的主力,Graph RAG作为补充。两者都返回结果,大模型根据返回结果生成最终回复。
Q对话模型为何使用Qwen#
目前Qwen系列模型是支持中文最好的模型。
Q客服系统的FAQ#
FAQ,即常见问题解答,黑心你是通过预设知识库+问答对匹配,快速解答用户的高频问题。电商场景下1500-3000条是合适的。
Q对话模型为何是8B#
对话模型一般参数量会较大,32B是合适的。解释8B,可以从公司业务场景并不复杂,表示8B模型已经可以很好的覆盖。也可以表明8B模型是从较大参数模型蒸馏得来
Q对话任务执行的流程#
对话系统核心流程包括:用户Query->安全检查(敏感词过滤、拒答)->上下文聚合(补全对话历史)->意图解析+槽位提取-> FAQ检索、工作流执行、RAG检索、Graph RAG、兜底对话->多轮对话管理->最终回复生成。
项目中任务型对话、信息型对话,最终返回的响应,都会由对话模型完成对用户的最终回复。
Q执行RAG工作流时,如何平衡检索速度与答案准确性#
这两个指标,对于召回结果的要求,通常是相反的。优化方式可以有:双阶段检索策略、文档的合理切块、top_k策略调整、嵌入模型轻量化、缓存高频检索问答对、上下文取摘要。
Q模型训练的数据来源,如何构建#
数据来源通常是长期业务累积后提供的。
意图数据示例:
{"text": "我想查询我的订单状态", "intent": "check_order_status"}
实体识别数据示例:
{"text": "我想查询订单12345的状态", "entities": [{"start": 5, "end": 10, "entity": "order_id"}]}
多轮对话数据示例:
{
"dialogue": [
{"role": "user", "text": "我想查询订单12345的状态"},
{"role": "agent", "text": "好的,请稍等,我帮您查询订单12345。订单状态是:已发货,预计明天送达。"}
]
}训练数据集构建时,可以考虑加入开源数据、敏感信息数据,三者比例保持在7:2:1较为合适。
Q优化模型推理速度的方法有哪些?#
以vllm为例,框架提供PageAttention、KV cache、动态连续批处理、权重量化、加速核心算子等方法加速模型推理速度。