项目周期#
- 1人团队,总计约2个月。
- 需求分析与数据审计2周
- 环境搭建与STF阶段2周
- DPO算法实现与调试2周
- 评估测试与迭代1周
- 模型部署与集成1周
功能介绍#
本项目的目标是:在电商客服场景中,让大模型输出更符合用户和业务需求的客服回复。
具体应用场景为:
任务型对话:帮助用户完成物流查询、订单跟踪、售后处理等流程#
知识库问答:基于知识图谱和GraphRAG,回答复杂的售前咨询#
闲聊与修复:在非业务场景下保持自然对话,但避免涉及敏感内容#
为实现这一目标,我们基于 Qwen3-8B 模型,采用监督微调 (SFT) 和 DPO 算法,使模型学会在多轮对话中输出 更贴近客户偏好的回复。
实现流程#
Q选择底座模型#
使用 Qwen3-8B 作为基础大模型
Q监督微调(SFT)#
数据集:公司内部客服多轮对话数据集
策略:只针对 回答部分 计算损失
目标:让模型具备客服多轮对话的基础能力
QDPO微调#
数据集:公司内部标注对话数据(包含正负例回复)
策略:只对回答部分计算损失
算法:实现 Direct Preference Optimization (DPO)
目标:让模型学习客户偏好,生成更符合预期的回答
Q工程实现#
在工程实现中,我们采用Hugging Face TRL库来构建DPO训练流程。TRL提供了稳定的训练基础设施,同时允许我们在其框架内扩展或重写损失函数,从而实现高度可控的训练逻辑,并便于在实验中进行不同损失函数的对比研究。
技术细节#
QSFT阶段#
模型结构:Qwen3-8B#
数据集:内部多轮客服对话(约50万轮)#
训练策略:只对客服回答部分计算损失,避免将用户输入当作监督信号#
超参数#
- 批次大小:128
- 学习率:2e-5
- 训练轮数:1 epoch
- 优化器:AdamW
- 学习率调度:5%线性预热+余弦退火
- 训练环境:1×A800 80GB,耗时约2小时
QDPO阶段#
数据集:内部标注的客服对话(包含正负例回答,约10万对)#
模型结构:Qwen3-8B -SFT#
算法实现:#
输入相同上下文,包含preferred回答(正例)和rejected回答(负例)
使用DPO公式计算loss,只对回答部分的token计算损失
超参数#
- 批次大小:32
- 学习率:1e-5
- 训练轮数:1 epoch
- β值:0.1
训练环境:2×A800 80GB,耗时3小时#
总结#
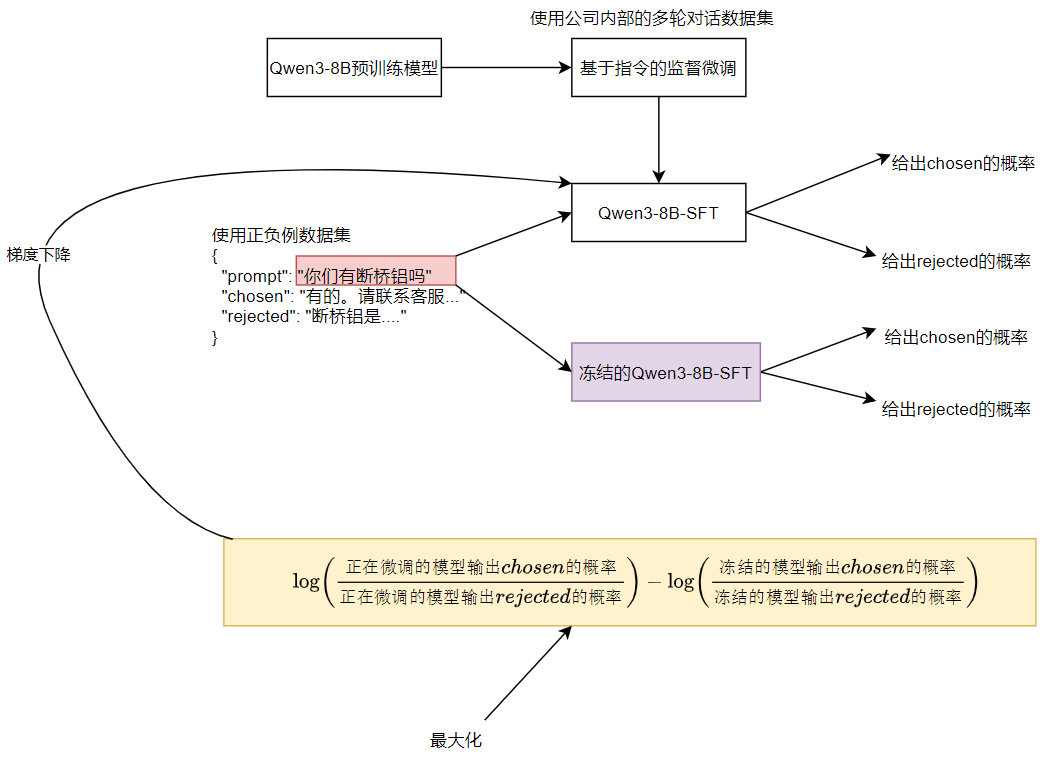
本项目面向 电商客服系统,在 Qwen3-8B 模型基础上,结合公司内部客服多轮对话数据与偏好标注数据,完成了 SFT + DPO 微调。
SFT:让模型具备客服场景下的多轮对话能力#
DPO:通过正负例偏好学习,让模型更贴近客户需求,减少不合适或冷漠的回复#
工程实现:依托TRL的DPOTrainer作为核心训练框架。借助TRL的可扩展接口,我们可以重写默认的DPO loss,或在训练过程中动态切换不同的损失函数。#
最终效果:在电商客服场景下,模型能够输出 更加自然、符合客户偏好且业务安全的回复,在任务型、知识库问答和闲聊场景中均表现稳定。
项目串讲#
我们的业务目标是优化电商客服系统,让模型能在多轮对话中生成更符合客户需求的回答。
我们选择了 Qwen3-8B 作为底座模型,首先利用公司内部的多轮客服对话数据集进行了监督微调。在这个阶段,我们只针对回答部分计算损失,避免训练过程中把用户输入也当作监督信号,这样得到的 Qwen3-8B -SFT 模型具备了客服多轮对话的基础能力。
接下来,我们使用公司内部标注的对话数据,这些数据包含正负例回答。我们通过 DPO 算法,在训练时同样只针对回答部分计算损失。DPO的原理是比较正例和负例回答的对数概率差异,再结合参考模型的对比,最终优化生成结果,让模型更贴近客户的偏好。
在工程上,我们采用TRL库来构建DPO训练流程,在保证基础设施稳定的同时,还可以借助TRL的可扩展接口,重写默认的DPO Loss,或在训练过程中切换不同的损失函数,快速对比多种偏好优化策略。
最终效果是:在电商客服场景中,无论是任务型对话、知识库问答还是闲聊修复,模型的回复都更自然、更符合客户预期,并且能够避免出现敏感或不合适的内容。
疑难解析#
Q为什么要使用DPO训练#
之前训练的模型的回复效果并不理想,虽然能够一定程度上基于规则进行拒答,但仍会出现复杂敏感词遗漏,回复质量不高(例如情绪倾向不好、对话延伸性不强、机械化回复)。当出现任务流匹配错误等情况下,回复质量会明显下降。
这里使用强化学习的目标,是为了学习生成人类更能接受的回复的策略,这与模型微调的训练目的并不一样。
QSFT与DPO训练目标的区别,SFT+DPO训练方式的优点#
训练目标不同,SFT让模型学会模仿人类示例,DPO优化模型输出、使学习更符合人类偏好的回答。SFT并非必须,但是进行会使得模型性能更为稳定,DPO训练更为平稳。SFT可以很好的保障模型的基本能力,避免DPO过度偏离。DPO通常训练数据量较少,SFT可以提供大量基础数据,并且有效避免模型过度追求奖励。
QDPO损失函数中β的作用,如何取到散度的作用#
β是超参数,用来控制KL惩罚强度。KL散度确保微调策略模型不会偏离基础模型太远,KL 散度正则项是对新策略与旧策略的分布差距进行惩罚项,作用是约束策略更新幅度,防止过度偏离基础模型或训练前策略,从而保证训练稳定性和生成安全性。
β越大,更新越保守,探索性弱。β越小,更新则更为激进,但风险也会更大。
Q数据集如何构建、正负例的构建方法#
数据集中会由业务提供一部分基础数据,之后进行筛选一部分高质量数据,并收集可靠的用户query集合,对于这些query,会由人工撰写一部分高质量回复,也会使用多个模型生成多候选答案,选择最符合偏好的作为正例。负例则多是由构建正例时,淘汰的数据构成,也可直接使用大模型进行数据增强。
QDPO、PPO、GRPO#
DPO(Direct Preference Optimization)#
直接优化偏好,绕开 RLHF 中复杂的策略梯度采样,直接用正负例比较来微调模型。进行对比式学习,而不是直接最大化 reward。
PPO(Proximal Policy Optimization)#
标准的强化学习,策略优化+收敛稳定,PPO通过KL散度、clip等,限制策略更新幅度,避免过度偏离旧策略。允许模型通过RL最大化任意 reward 信号,进行策略更新。
GRPO(Group Relative Policy Optimization)#
对于每个prompt生成候选输出组,在组内计算相对优势来更新策略。优点在于不依赖价值网络,通过组内相对优势进行计算,提高候选区分能力,并且由于每生成一条回复都会先进行模型参数更新,再生成下一次输出,是一种模型参数动态更新方式。
QDPO的优势#
在强化学习算法中,DPO无需采样策略梯度,训练更稳定、易收敛。
Q强化学习训练中,是否出现模型性能倒退的情况#
性能倒退通常会表现为任务准确率下降、输出质量下降、奖励上升但业务指标下降、生成模板化回复。这是由于奖励模型不完备、学习梯度过大、缺乏模型训练策略约束、模型过优化。缓解方式通常是增加数据多样性、奖励模型性能、防过拟化训练策略。
Q奖励模型通常如何设计的#
奖励模型直接决定策略模型的性能,通常会由一个神经网络结构构建完成。设计的关键是,高质量的标注数据、正负例平衡与多样化、多维度奖励融合,并具备评价一致性。奖励模型不存在最优,但一直存在优化空间。