项目周期#
- 2人团队,总计约3个月。
- 需求分析与架构设计2周
- 数据管道搭建与调试3周
- 实体抽取模块开发与测试4周
- 索引构建与应用层开发1周
- 部署与测试2周
功能介绍#
互联网医疗知识图谱基于Neo4j图数据库构建,包含疾病、科室、症状、诱因、药物、食物、传播途径等。
数据的来源包含三部分。一是开源医疗知识图谱种的结构化数据,二是开源带标注的医疗数据集,三是部分医学书籍和期刊等非结构化数据。
为方便上层应用,为图谱中的数据构建了全文索引和向量索引,以支持全文检索和语义检索。
完整架构如下图所示:
实现流程#
Q数据建模#
图数据库#
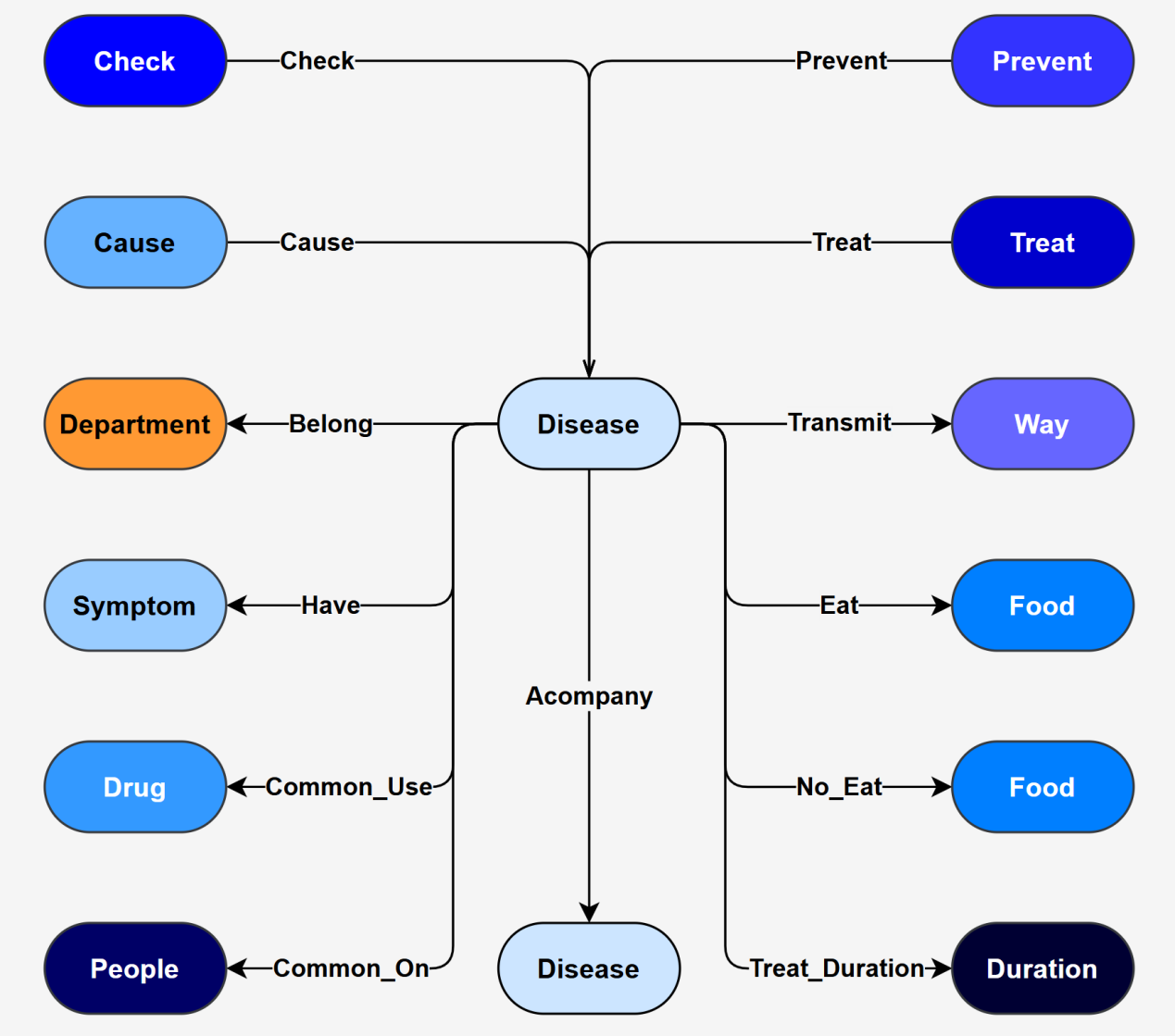
图数据库中的数据模型如下图所示。
Q实体抽取#
在利用医学书籍和期刊构建知识图谱时,我们需要从文本片段中将疾病、症状、诱因、并发症等实体和关系抽取出来。此外如果期刊是英文我们需要先将其翻译为中文。所有抽取出的内容必须经过人工审核通过之后才能存入知识图谱。
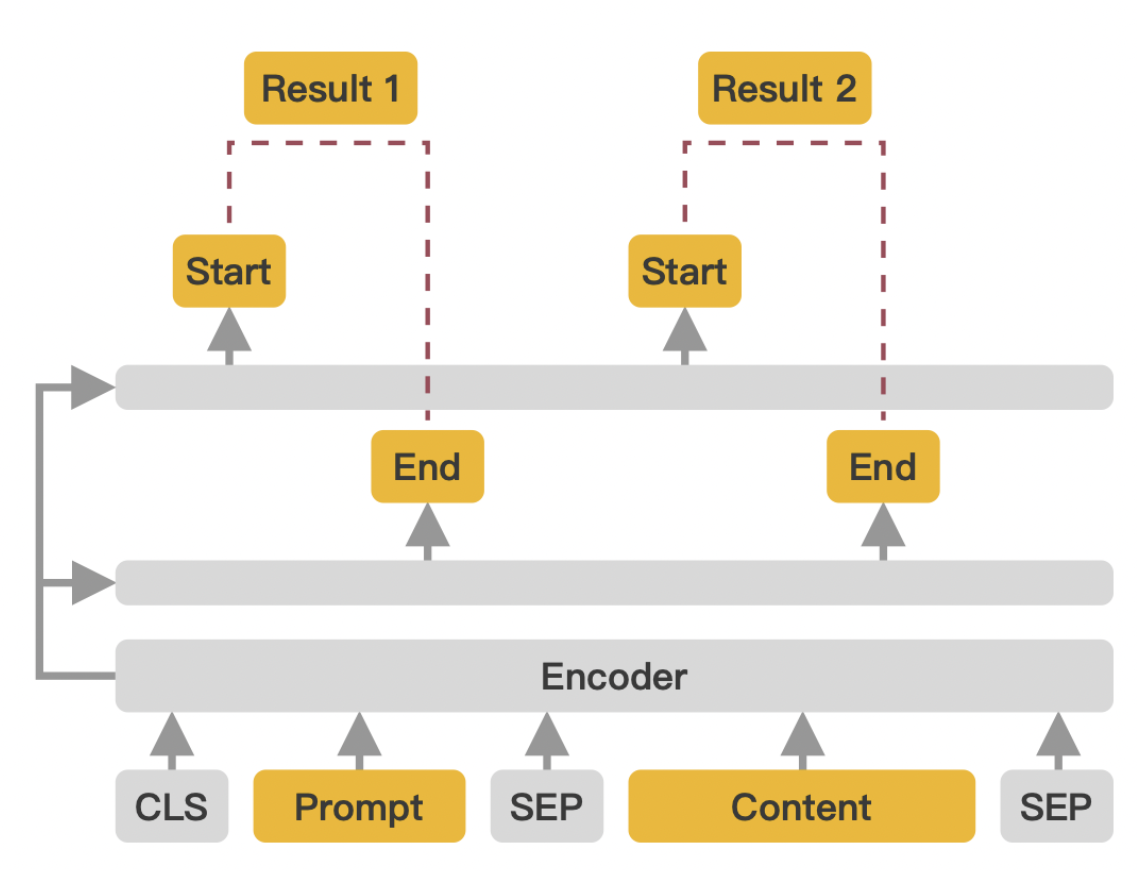
医学实体和关系抽取使用的模型是百度开源的通用抽取模型——UIE,其基于ERNIE模型,并在ERNIE模型的基础上增加了两个线性层,一个用于预测实体的起始位置,一个用于预测结束位置。
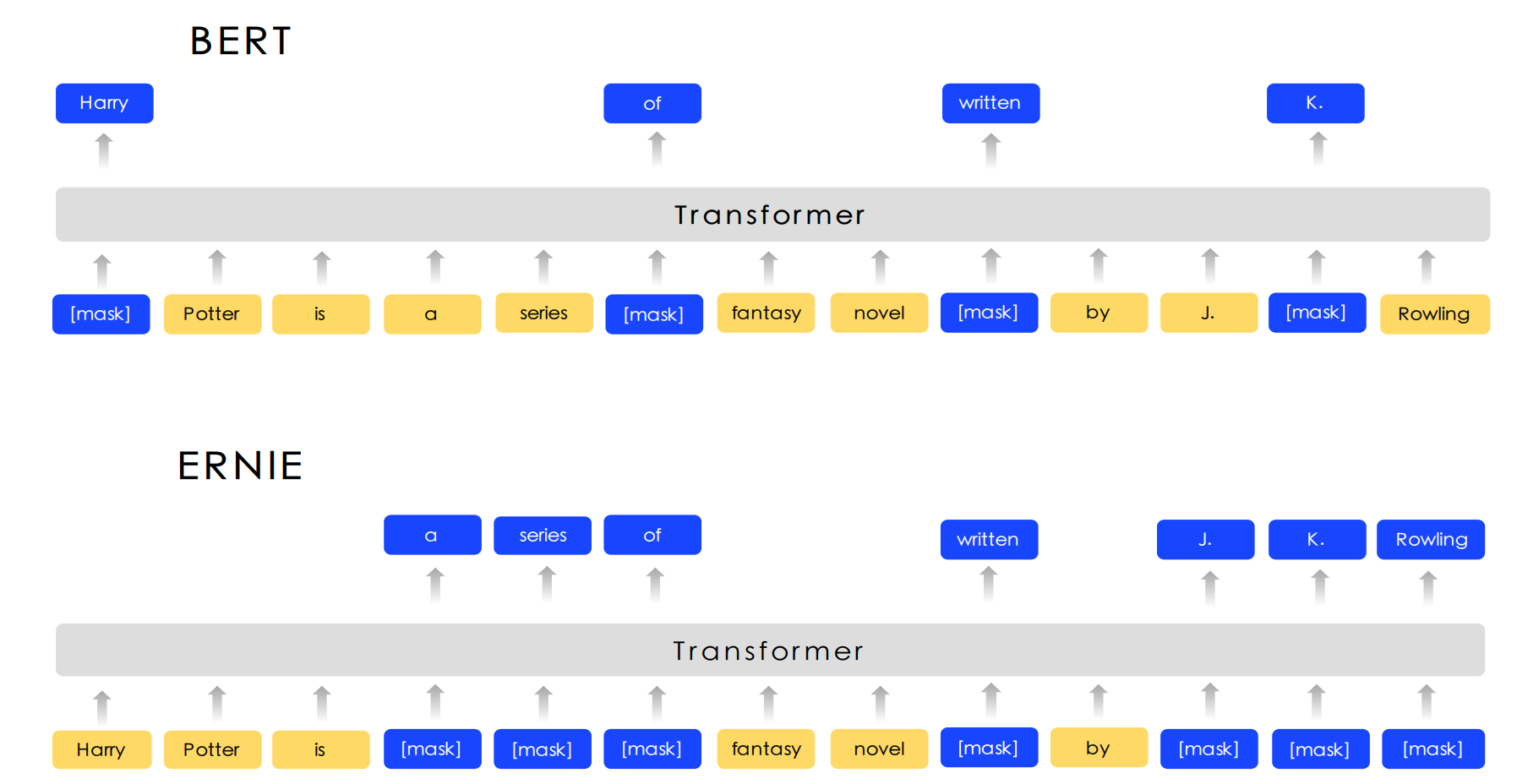
ERNIE和BERT的结构类似,都是编码器模型。不同的是预训练方式,BERT在训练时是随机掩盖若干个独立的token,然后令模型预测这些token,而ERNIE在训练时不是掩盖单个Token,而是掩盖整个实体,这样模型就能学到更丰富的实体知识,所以其在实体抽取任务上更有优势。
Q创建索引#
为方便上层应用查询,创建了全文索引和向量索引。
全文索引#
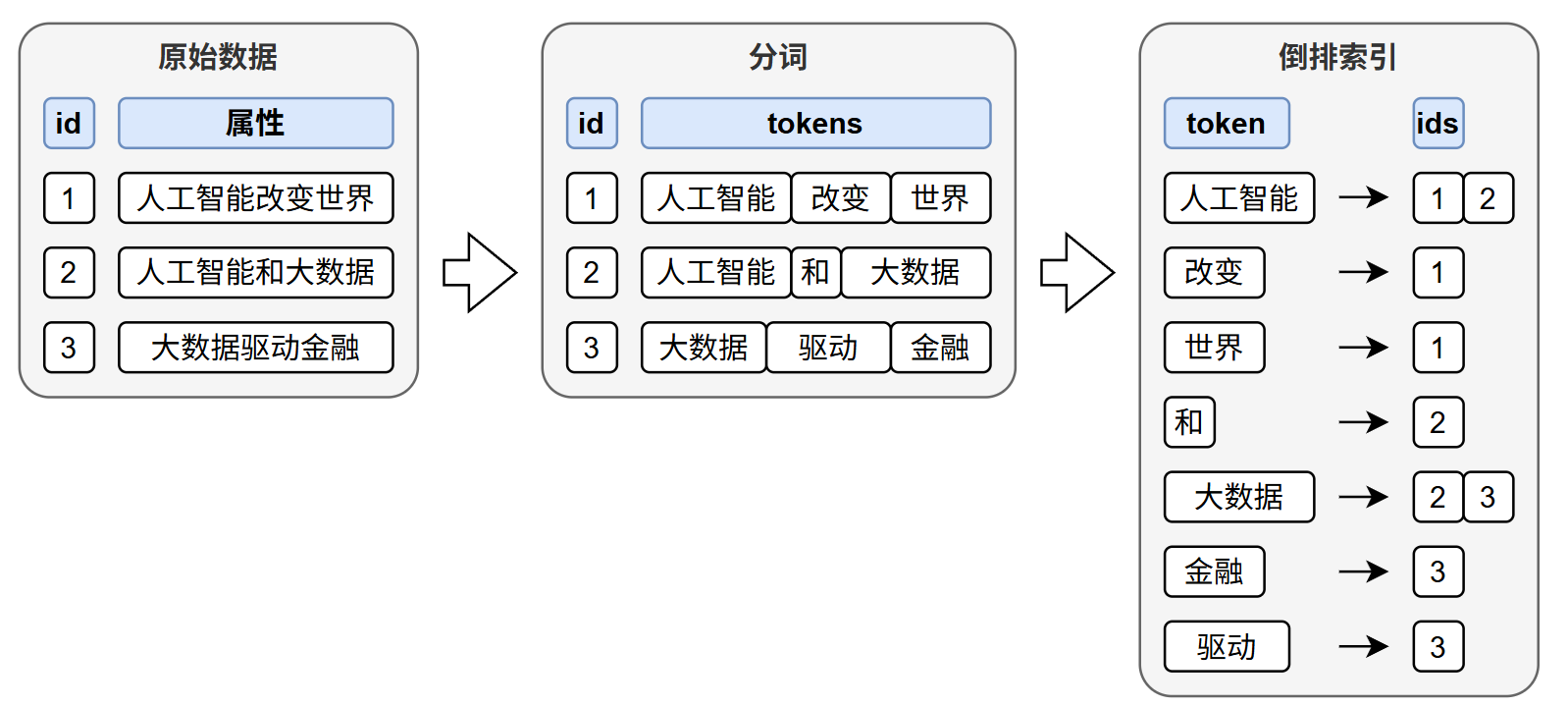
全文索引的基本原理如下图所示:
向量索引#
Neo4j底层的向量索引算法为HNSW(Hierarchical Navigable Small World),其原理图如下所示:
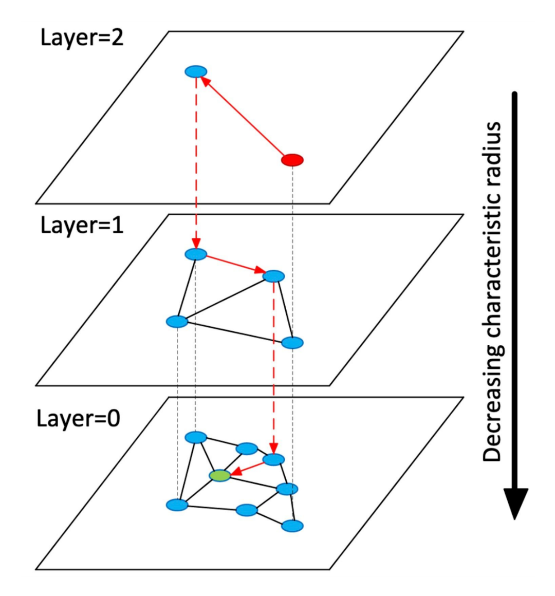
HNSW算法借鉴了如下算法:
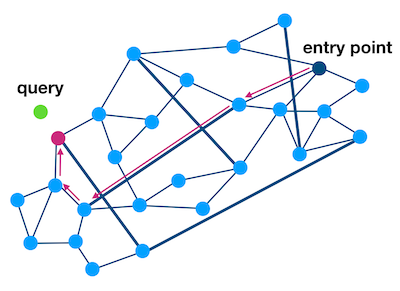
NSW(Navigable Small World)
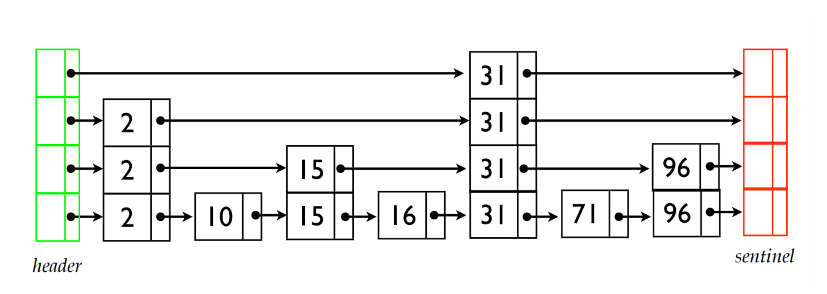
Skip List
技术细节#
Q实体抽取模型#
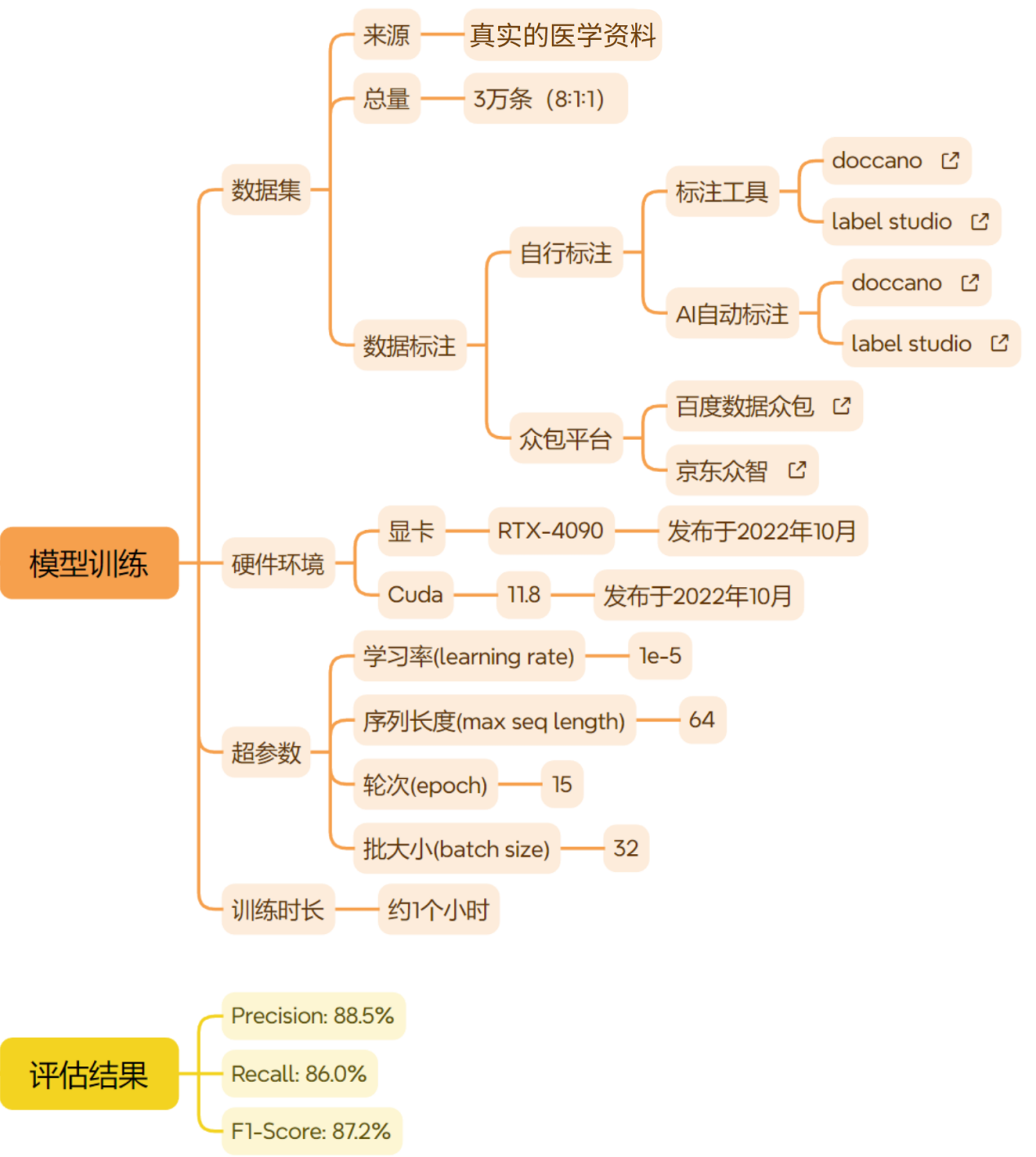
实体抽取采用百度开源的UIE模型,UIE支持零样本预测,但在我们实际的这个场景中,直接使用的效果不太理想,因此又对齐进行了微调。微调细节如下图所示:
QEmbedding模型#
采用BAAI/bge-small-zh-v1.5,向量维度为512。
总结#
我们搭建这互联网医疗知识图谱的初衷主要是为上层的AI应用提供数据支撑,比如智能客服等。
这个图谱主要的数据来源是一些开源的医疗知识图谱数据和开源的带标注医学数据集,包括疾病、症状、诱因、并发症等,这些大都是结构化的数据,除此之外,还有一些非结构化的数据,包括医学书籍和期刊等,我们需要从这些数据中将疾病、症状等和他们之间的关系抽取出来,以构建医疗知识网络。
我们使用的是Neo4j图数据库来构建知识图谱。
同步过程中的实体抽取,主要是从医学数据和期刊的文本片段中抽取各种实体和关系。如果文本是英文的,在抽取之前我们还需要将其先翻译为中文。这里我们使用了百度开源的一个通用信息抽取模型,叫做UIE,这个模型以百度自家的ERNIE预训练模型作为基础。ERNIE和BERT的结构类似,都是编码器模型。但它们的预训练方式不一样:BERT在训练时是随机掩盖若干个独立的token,然后令模型预测这些token,而ERNIE在训练时不是掩盖单个Token,而是掩盖整个实体,这样模型就能学到更丰富的实体知识,所以其在实体抽取任务上更有优势。
然后在UIE在ERNIE的基础之上,又使用了两个线性层,一个线性层用于预测实体的起始位置,另一个线性层用于预测结束位置。在推理时,根据起始位置和结束位置就能截取到实体信息了。
UIE是支持零样本预测,但在我们实际的这个场景中,直接使用的效果不太理想。所以我们人工标注了大约3万条数据,对模型进行了微调。调优之后,F1值达到了88%,基本满足了我们业务上的要求。
在抽取出实体和关系之后,必须经过人工的检查校验才能够进入Neo4j。
最后,数据进入Neo4j之后,为了支持上层复杂查询,我们给图谱建立了两种索引:一个是全文索引,主要用于关键词检索;另一个是向量索引,用于语义相似度查询,当然,建立向量索引需要先有向量,这里我们使用的Embedding模型是BGE,这是一个开箱即用的高质量Embedding模型,不需要微调就能有很好的效果。
以上就是这个图谱项目的全部内容。