项目周期#
- 1人团队,总计约1个多月。
- 需求分析与技术选型3天
- 数据准备与预处理1周
- 模型开发与训练1周
- 地址对齐模块开发1周
- 系统集成与后端对接1周
- 部署上线3天
功能介绍#
输入一整段收货地址文本,系统自动识别地址信息和用户信息,具体如下
地址信息:省、市、区/县、街道/乡镇、详细地址等
用户信息:收货人姓名,联系电话
输出可直接入库的标准化收货地址与收货人信息。

实现流程#
Q抽取实体#
使用BertForTokenClassification从用户输入的文本中抽取实体信息,包括地址信息(省、市、区/县、街道/乡镇、详细地址)和用户信息(收货人姓名,联系电话)。
Q地址对齐#
考虑到用户输入地址可能不规范,因此需要和数据库中的标准地址进行对齐,数据库中的标准地址如下:
需要处理的不规范行为具体如下:
缺失补全:对用户输入中缺失的部分信息进行补全#
比如用户只输入了市和区,自动补全省份信息。
错误修正:如果地址链路存在部分错误,修正错误部分#
比如用户输入的省和区能匹配,而市不能与省和区匹配上,自动修正市的地址。
剔除无法匹配的信息:对无法与数据库匹配的信息进行剔除#
比如用户输入无法匹配或在现实中不存在的区或街道,将其剔除。
技术细节#
Q地址抽取#
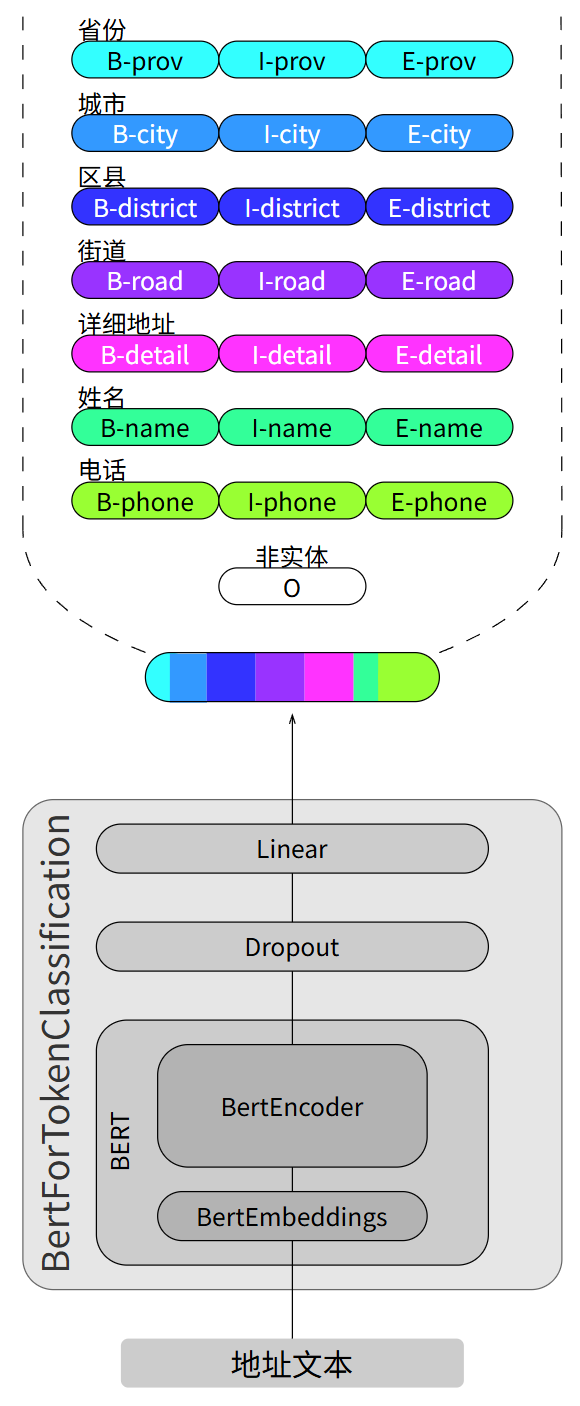
模型#
采用bert-base-chinese模型,具体结构如下图所示:
数据集#
数据来源#
- 开源数据集:清洗过滤,保留符合自身业务规范的数据,统一标签。
- 业务数据库地址信息表:取出数据脱敏拼接成完整地址信息并添加标注。
- AI生成:通过脚本调用大模型批量生成数据,人工抽检确保每批次数据质量。
数据量#
共20万条数据。
训练集:16万条
验证集:2万条
测试集:2万条
标签#
包括姓名、电话、省、市、区、街道、详细地址、非实体8类22个标签。
模型训练#
Q地址对齐#
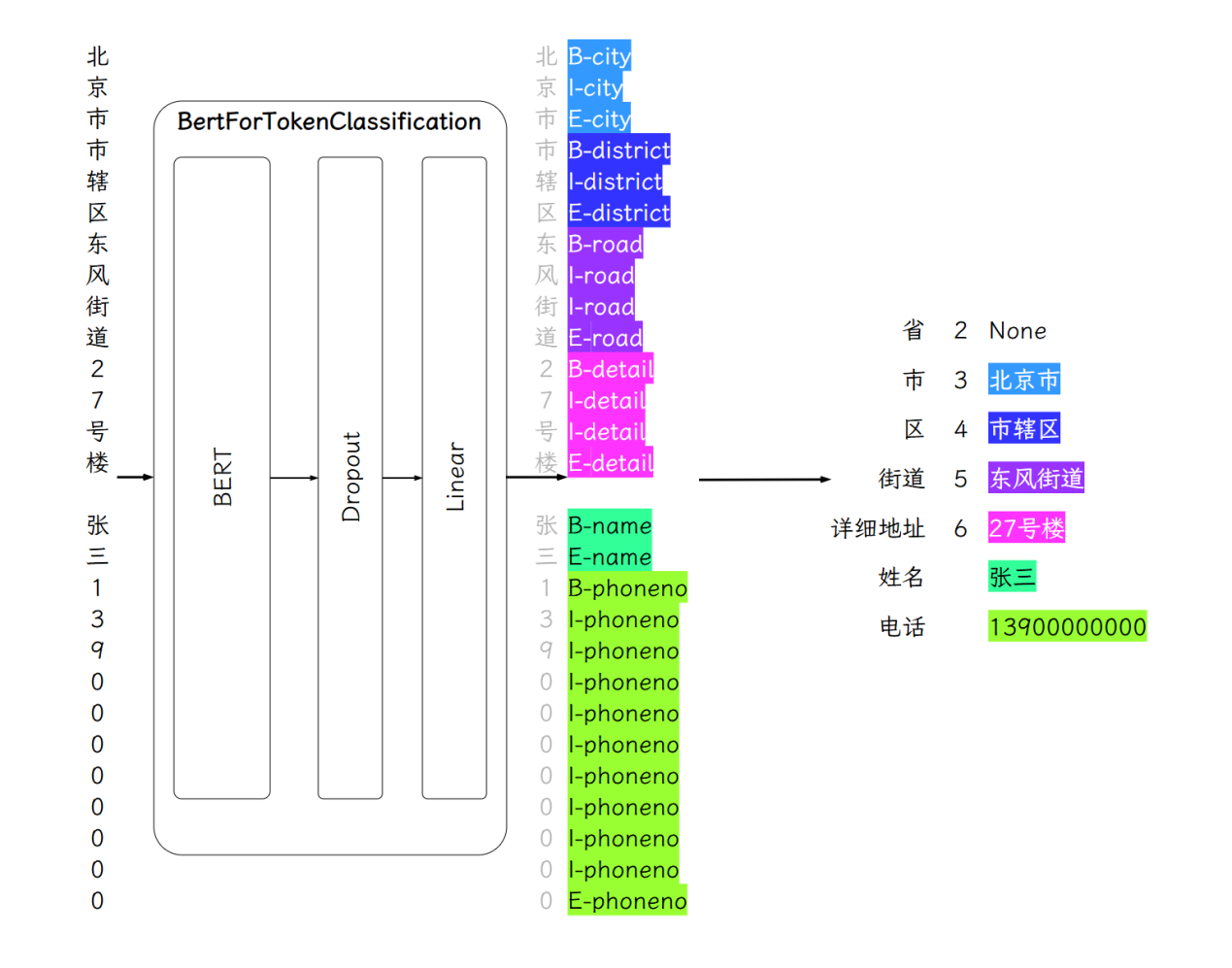
提取各个实体#
根据序列标注结果从原始文本中提取出各个实体,如下图所示
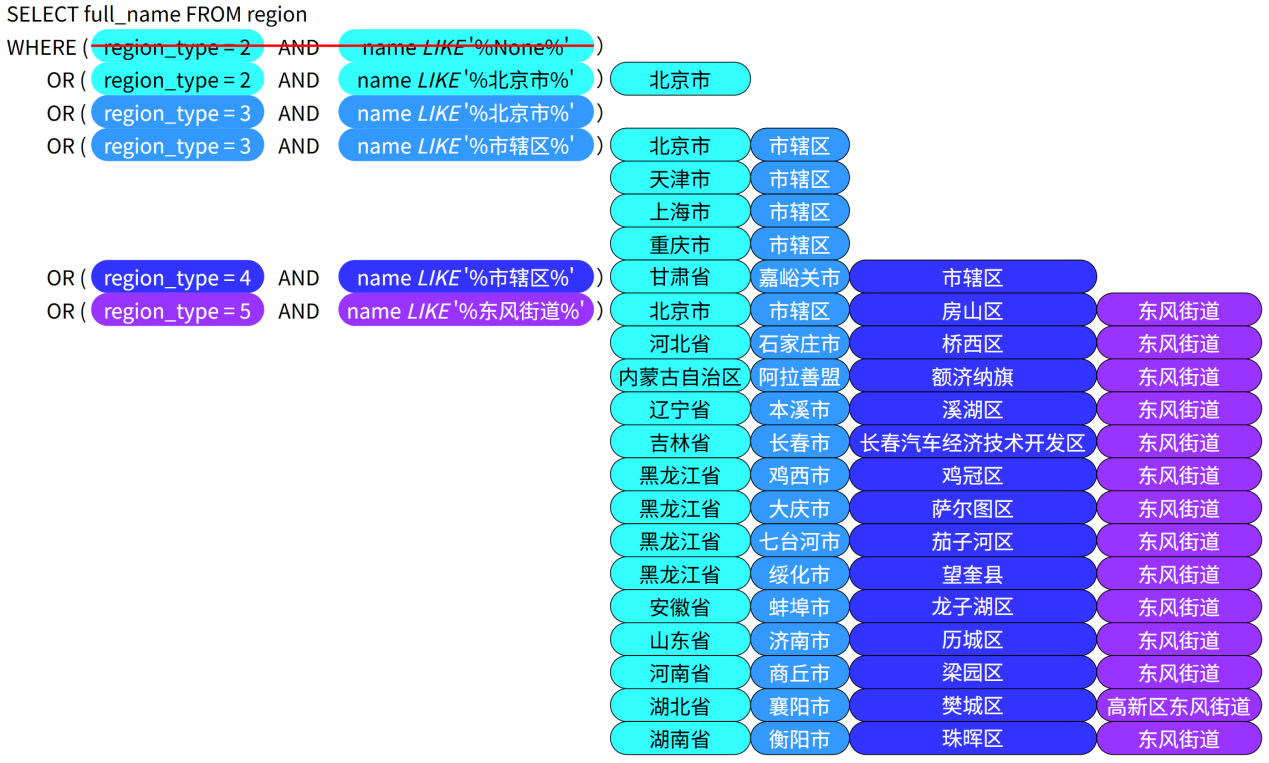
根据抽取出的实体查询获选结果#
考虑到用户输入的地址可能不规范(部分缺失、部分错误),以及模型识别错误(例如将北京市识别为市级、将市辖区识别为区级)。
此处的候选地址选择逻辑如下图所示:
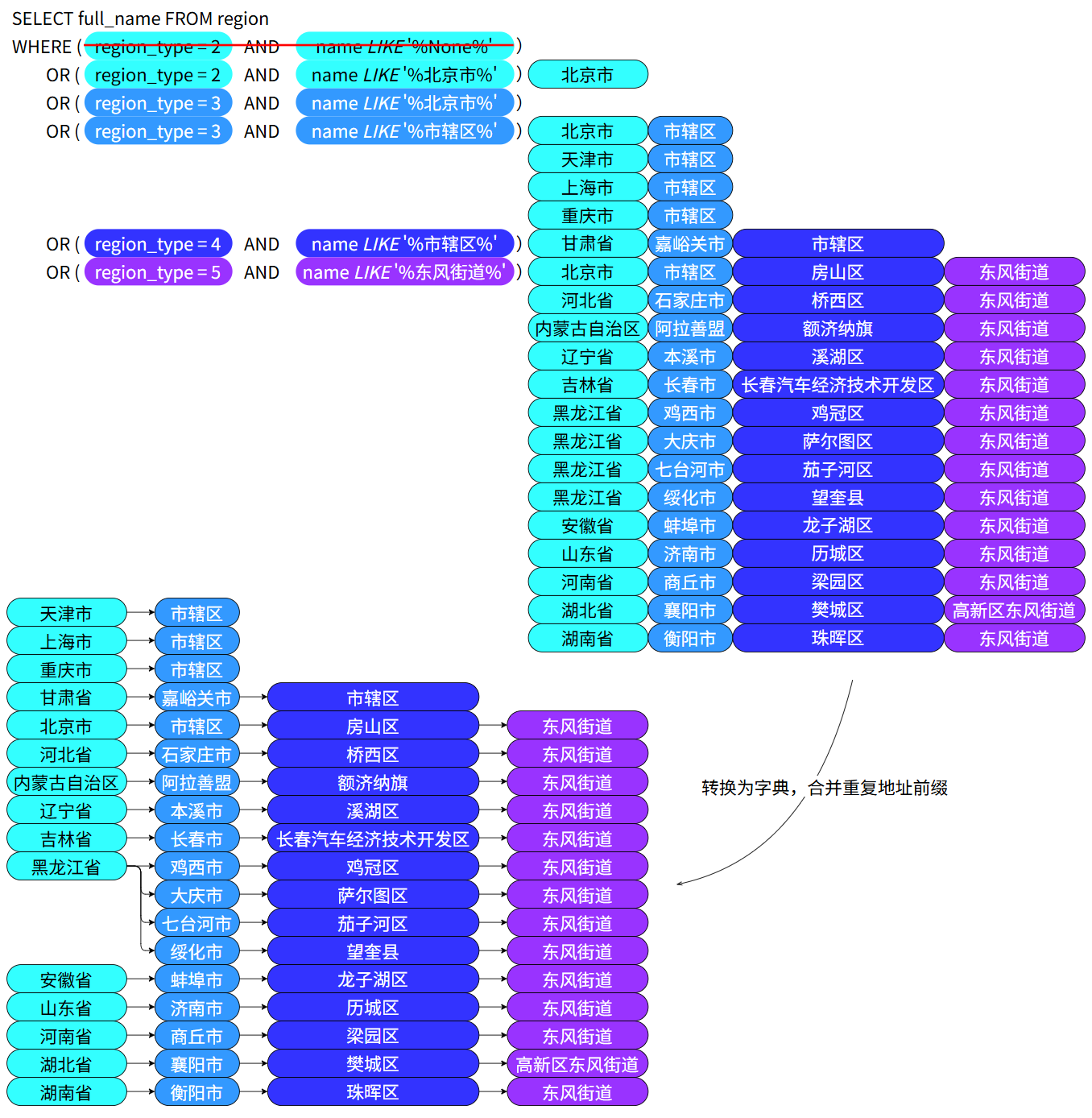
合并前缀相同的候选地址#
可以利用如下数据结构实现合并:
{
prov1:{
city1:{
dist1:[road1,road2]
city2:...
}
prov2:...
}
}
结果如下图所示:
选取最终结果#
将每个候选结果以及抽取出的实体,各自拼接位完整的地址字符串,然后根据抽取结果和候选结果的相似度得分,得到最终的对齐结果。
具体操作如下图所示:
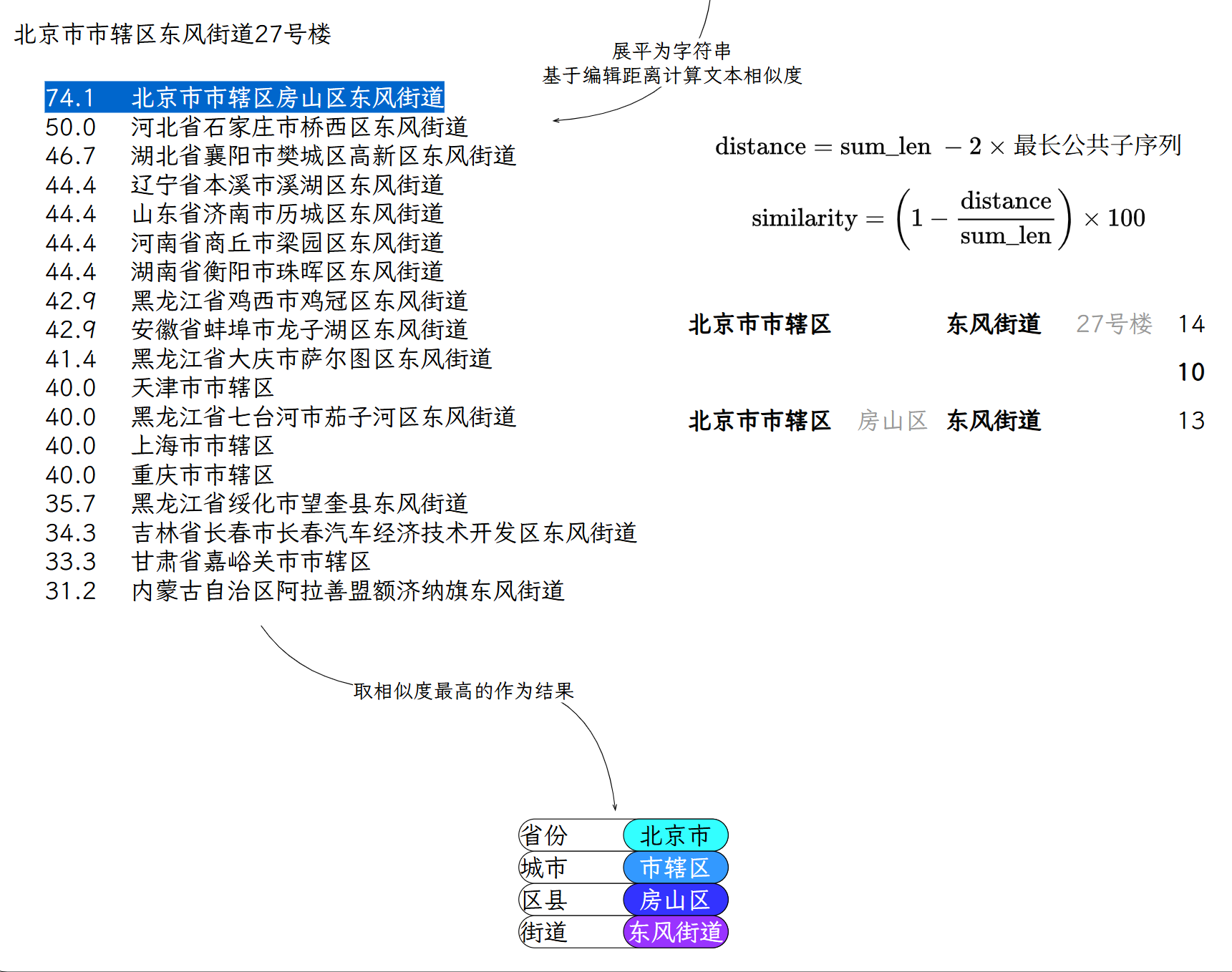
编辑距离是指将字符串A变成字符串B所需要的插入/删除/替换的操作次数。
rapidfuzz.fuzz.ratio():
sum_len = len(str1) + len(str2)
distance = sum_len - 2 * longest_common_subsequence
similarity = (1 - distance / sum_len) * 100
面试串讲#
这个地址抽取项目,主要用于实现用户收货地址的智能录入,具体功能就是从用户输入的一段收货地址文本中,抽取出规范化的地址信息,包括省市区等,以及用户信息,包括姓名和电话号码。
这其实就是一个典型的NER任务,所以我们首先基于bert-base-chinese训练了一个序列标注模型,用于从文本中识别并抽取上述的地址信息实体和用户信息实体。
不过这个项目的难点其实并不在于抽取,而是在于规范化,因为用户输入的文本中所包含的地址信息可能并不完整,甚至是不准确,这自然就会导致模型的抽取结果不完整或者不准确,因此不能直接使用。所以在完成实体抽取之后,我们还设计了一个地址对齐模块,用于将抽取结果与数据库中的标准地址进行匹配,从而得到完整并且规范的地址。
下面我分别介绍一下地址的抽取和对齐这两部分工作。
地址抽取主要就是训练了一个基于bert的序列标注模型,训练数据是一个BIO格式的开源数据集,大约有20万个样本,一共训练了5个Epoch,训练完使用seqeval进行评估,F1评分达到了94.1%
然后是地址对齐,这个地址对齐需要考虑的情况非常复杂,比如用户输入的地址可能缺少某个实体,此时我们就需要根据已有的实体推断缺少的实体,再比如地址中的某个实体有可能是错误的,此时我们就需要识别出错误的实体并对其进行纠正,可想而知,这个对齐规则的编写会非常复杂。
所以这个对齐,我们并未采用基于规则的方案,而是选择了基于文本相似度的方案。接下来我说一下具体思路,首先我们假设抽取到的地址实体是存在问题的,也就说没有哪个实体是可以百分之百信任的,所以我们会以每个实体作为查询条件,从标准数据库中查询以该实体作为最细粒度的完整地址,比如根据省份实体查询省份,根据城市实体查询省份-城市,根据区县实体查询省份-城市-区县,得到的这些地址都会作为候选地址,正常情况下,这些候选地址可能会有重合的部分,所以我们会先合并这些重合的路径,之后再计算这些获选地址和抽取出的地址之间的相似度得分,最后取得分最高的候选地址,作为最终的地址。补充一点,这个相似度得分我们使用的是编辑距离。
以上就是这项目的全部内容。