也是学习项目。
项目周期#
- 1人团队,总计约1.5月。
- 奖励函数设计与实现1周
- 徒手实现DAPO算法3周
- 训练与超参数调试2周
- 评估与对比2天
功能介绍#
本项目目标是:基于强化学习改进大模型的推理能力,尤其是在数学推理与医学问答场景中。
我们选择了一个已经监督微调过的底座模型Qwen2.5-3B-Instruct,在此基础上从零实现 字节提出的GRPO算法改进版DAPO,并结合数学与医学推理数据集进行训练。
最终目标是让模型:
在通用任务中具备更强的逻辑推理能力
在医疗类任务中能涌现出结构化、逐步推理的解答能力,为病人病情提供合理回答
实现流程#
Q选择SFT底座模型#
采用 Qwen2.5-3B-Instruct 作为基础模型
Q实现 DAPO 算法(基于GRPO改进)#
每次对同一问题生成8条候选回答#
奖励函数对8条回答进行打分#
计算每条回答相对组内均值的优势 (Group Relative Policy Optimization)#
将 token级别的log概率 × 回答优势 作为损失进行反向传播#
Q混合数据集训练#
数学推理数据集(如GSM8K、MATH)#
医学问答数据集(MedQA、临床问诊数据)#
通过混合训练,使模型既能做逻辑推理,又能在医学领域展现推理能力#
Q训练环境#
使用 AutoDL 平台#
硬件:L20 GPU,显存足够支撑中等规模批次训练#
Q工程实现#
手工实现 GRPO/DAPO/GSPO 算法,未依赖 trl 等RLHF库,确保可控性与可对比性#
集成 unsloth 用于高效LoRA训练,加速迭代#
结合 vLLM 部署推理,提高推理吞吐量与响应速度#
技术细节#
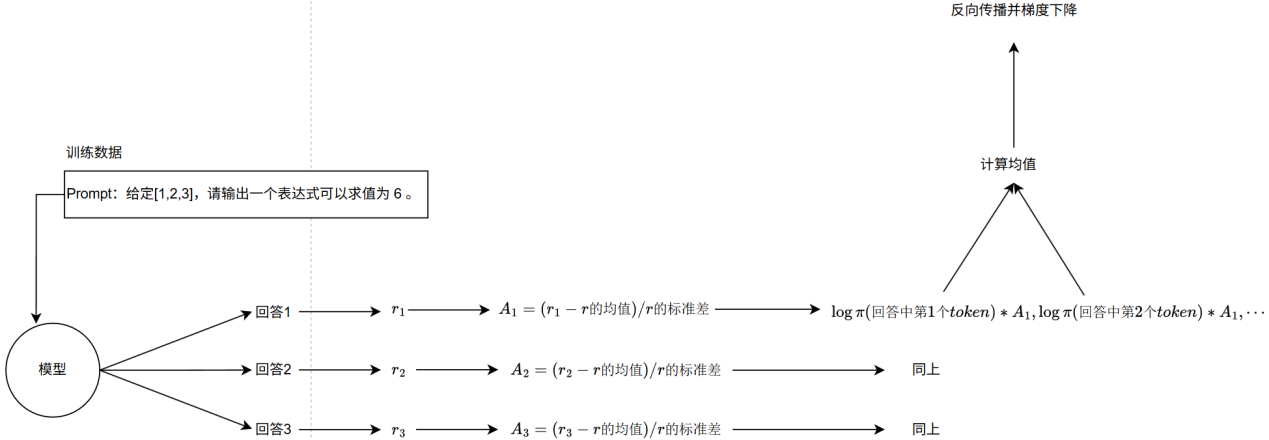
Q算法实现(DAPO)#
输入:一个问题
输出:8条回答
奖励函数:基于回答正确性、逻辑完整性、专业性(医学场景下)打分
优势计算:每条回答减去组平均值,得到 group-relative advantage
损失函数:对每个token,
Q数据集与训练#
数学推理数据集:GSM8K、MATH
医学问答数据集:MedQA、中英双语临床对话数据
数据混合策略:按比例采样(数学:医学 = 7:3)
目标:增强通用推理能力 + 医学专业问答能力
Q超参数配置#
批次大小:128
学习率:1e-5
生成样本数:8 (per prompt)
训练轮数:3 epoch
奖励归一化方式:z-score
优化器:AdamW, weight decay=0.1
=0.99,=0.95 (用于优势估计的折扣因子和tracker系数)
Q工程与工具#
unsloth:用于LoRA微调,显著降低显存占用
vLLM:作为推理引擎,提升吞吐量和延迟表现
AutoDL:云端GPU平台,硬件为L20卡,保证训练效率
手工实现对比实验:实现GRPO、DAPO、GSPO三种算法,用于性能对比和消融实验
总结#
本项目在 Qwen2.5-3B-Instruct 基础上,复现并改进了GRPO类算法,采用DAPO进行强化学习微调,最终实现了一个具备 链式推理能力 的大模型:
在数学任务中能输出逐步推理过程
在医学问答中能够围绕病人病情进行结构化解释与解答
工程层面使用 unsloth + vLLM 提升训练与推理效率
该项目不仅满足了业务需求(医疗场景下的高质量推理回答),也验证了不同策略优化算法(GRPO、DAPO、GSPO)在大模型推理能力提升方面的差异。
项目串讲#
本项目的目标是让大模型具备更强的推理能力,尤其在数学和医学场景下能生成符合人类需求的思维链回答。
我们选择了一个已经SFT过的底座模型Qwen2.5-3B-Instruct,然后从零实现了字节提出的GRPO改进版DAPO算法。具体做法是:模型针对同一个问题一次性输出8条回答,用奖励函数对这8条回答进行评分,再计算每条回答相对于组平均值的优势。训练时,我们把每个token的对数概率乘上该回答的优势作为损失,进行反向传播。这样可以在组内比较回答优劣,从而更稳定地提升模型的生成质量。
在数据上,我们混合使用了数学推理数据和医学问答数据。这样一方面模型学会了逐步推理的能力,另一方面也在医学场景中涌现出了针对病情进行分析和回答的能力。
训练方面,我们使用AutoDL平台的L20 GPU进行训练,并在工程上手工实现了GRPO、DAPO和GSPO等算法,方便对比实验效果。同时结合了unsloth用于高效LoRA训练,以及vLLM作为推理引擎,加速推理吞吐。
最终模型在数学问题上能够生成清晰的逐步推理链,在医学问答中也能给出合理的分析和解释,整体表现符合业务需求。