Vit架构#
整体思路#
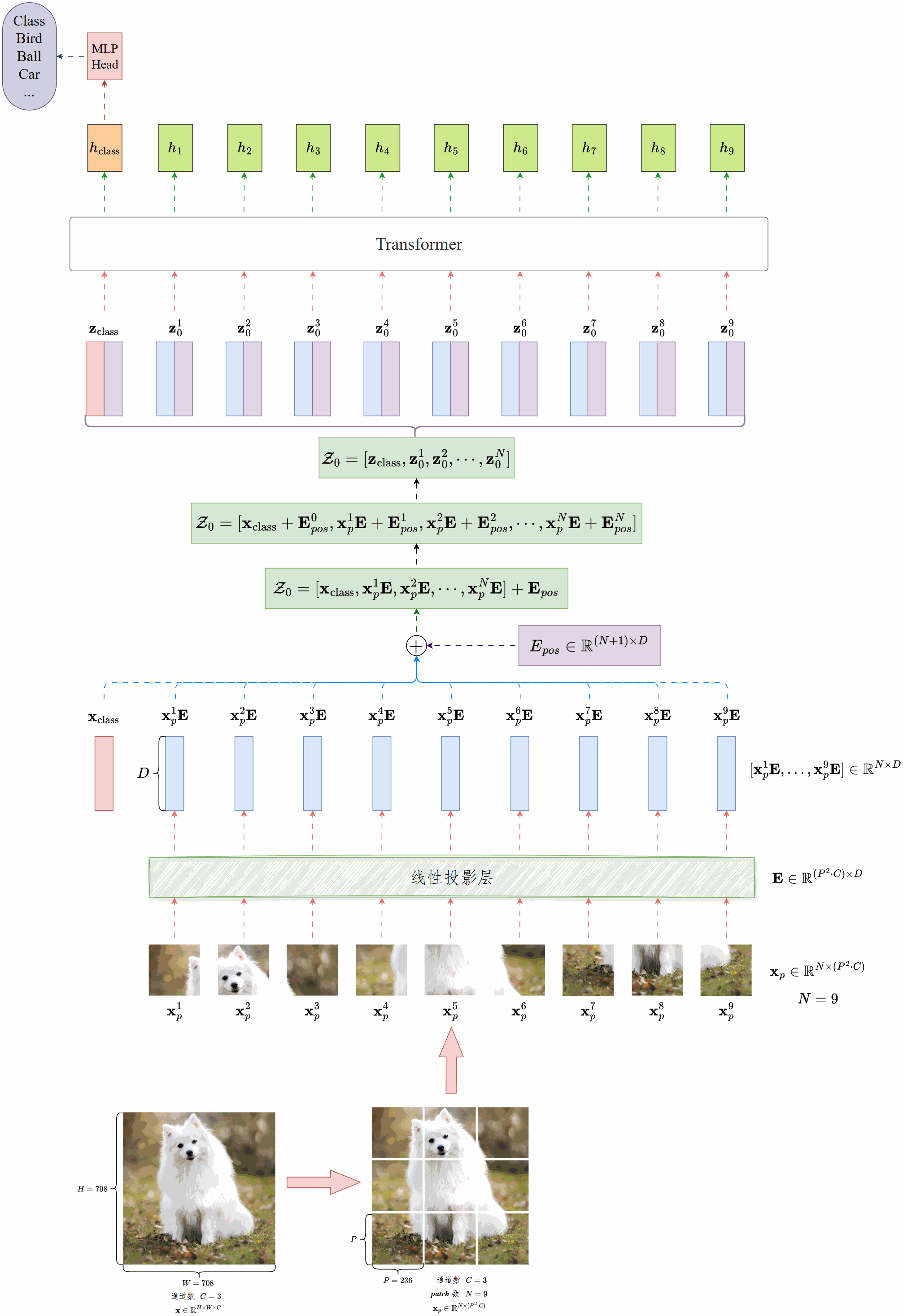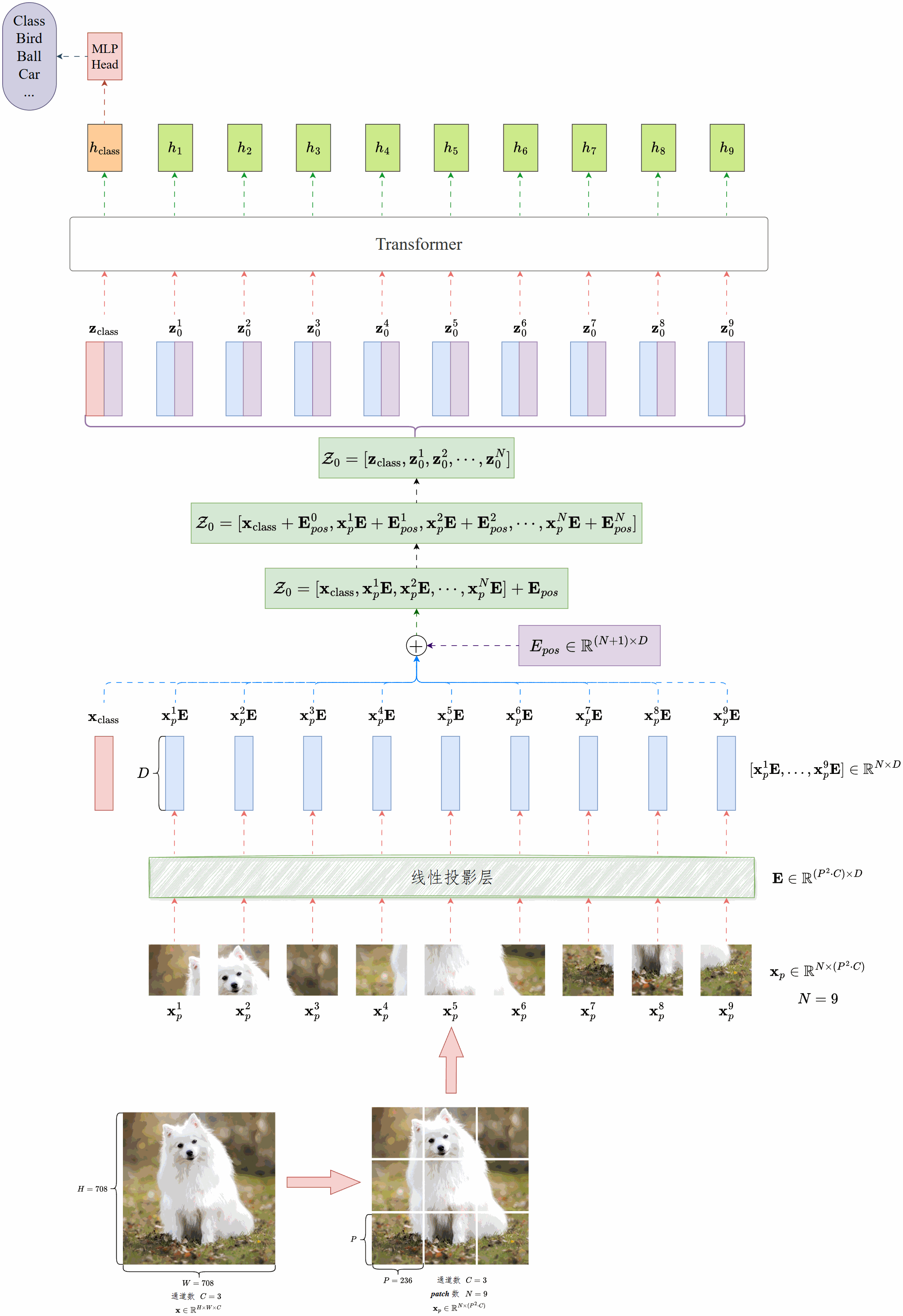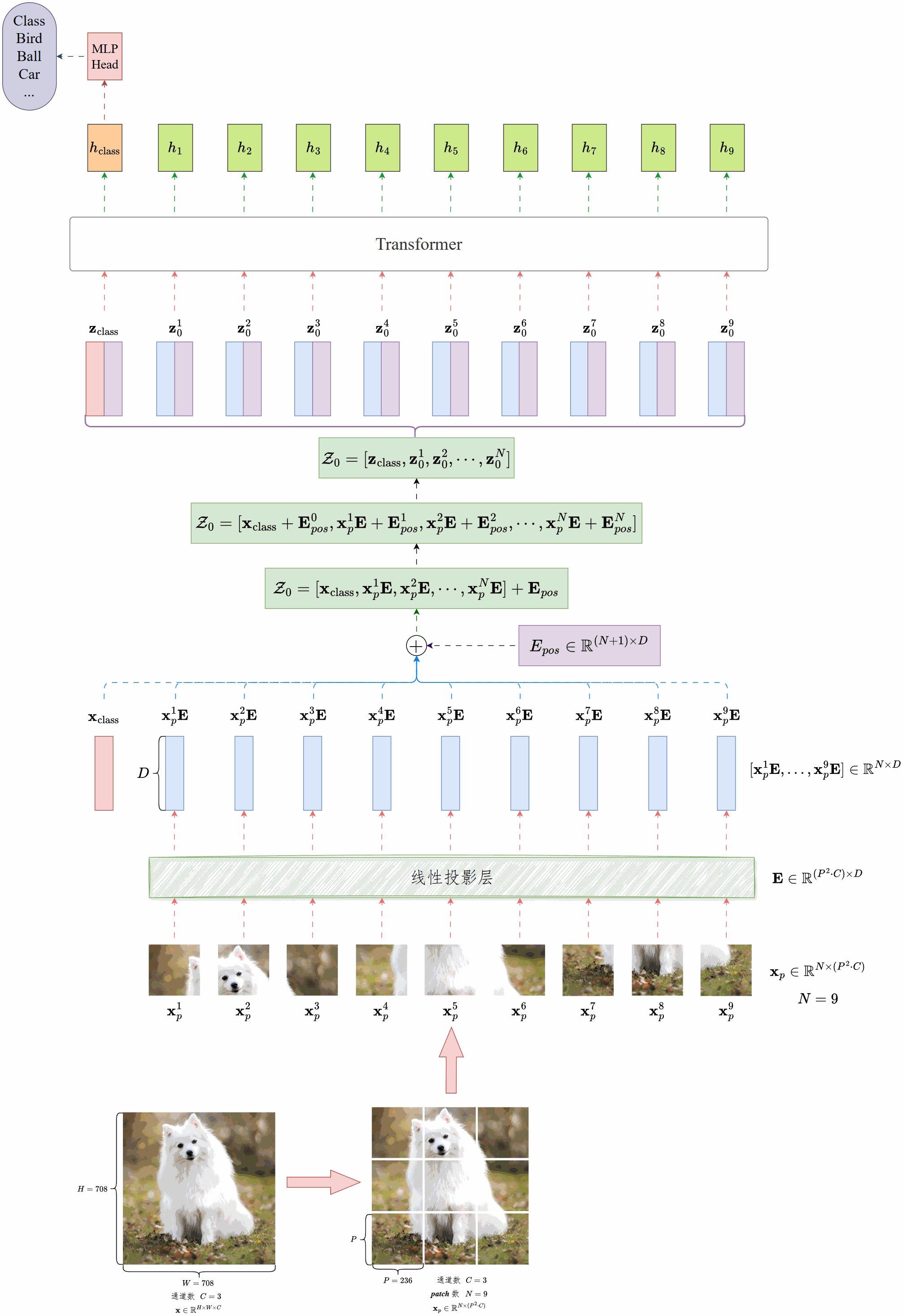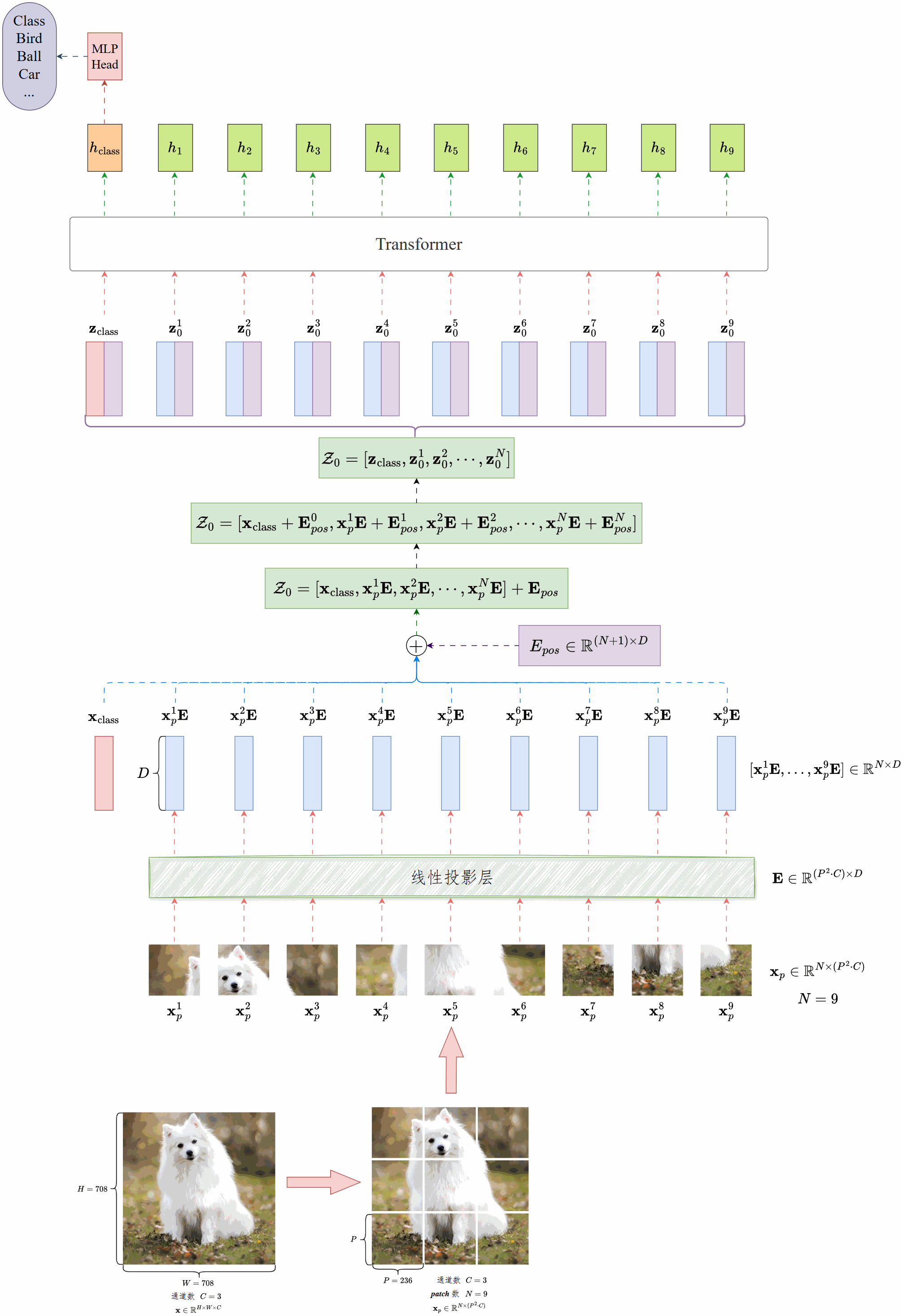
Vision Transformer,简称 ViT,就是把图像识别问题转化成类似 NLP 的序列建模问题。原来我们处理句子是把句子拆成单词,ViT 就是把一张图拆成小块(patch),再用 Transformer 去理解这些块之间的关系。
具体流程#
切图&向量化#
一张图会先被切成很多小块,比如16×16的patch。每个patch都会被拉直,再映射成一个向量,相当于给它一个“词向量”。
加入位置信息#
因为Transformer不像卷积那样天然有位置信息,所以我们要给每个patch加上位置编码,让模型知道这个patch在图里是哪里来的。
加一个分类token#
在所有patch前面,加一个特殊的<CLS> token,专门用来聚合整张图的信息。最后分类的时候,就用它的输出。
Transformer编码器#
接下来就是一堆标准的Transformer层:多头自注意力、前馈网络、残差连接和归一化。这样模型就能学习到图像中任意两个patch之间的全局关系。
分类头#
最后,拿到<CLS> token的表示,送到一个小的全连接网络里,输出类别。
特点和优势#
ViT的最大特点是它不再像CNN那样只关注局部,而是通过自注意力直接建模全局关系。#
它在小数据集上不如CNN,但在大规模数据上训练后,往往能超过CNN的表现。#
而且它的扩展性很好,模型越大、数据越多,效果提升越明显。#
QVit图像补丁嵌入是什么#
在 ViT 里面,图像补丁嵌入就是把原始图像切成小块,再把这些小块转换成向量表示的过程。
具体来说,一张图像会被均匀切分成很多小patch,比如常见的是大小。每个小patch就像是NLP里的“一个词”。但是模型不能直接处理原始像素,所以会先把每个 patch 展平,再用一个线性映射(其实就是全连接层)把它转成固定维度的向量。这个步骤就叫做 补丁嵌入(Patch Embedding)。
这样,整张图就被表示成一串向量序列,可以直接送进Transformer去做自注意力建模。
其实patch embedding和CNN的卷积很像,如果把卷积核的大小和步幅设置得跟patch一样,就能达到相同效果。CLIP源码中就是这样实现的。
Q讲一讲ViT的图像是怎么输入模型的,class token的作用是什么#
ViT把图像切成小块做embedding,加上位置信息,再在前面拼一个[CLS] token输入模型。最后分类就是用这个token的输出,因为它在自注意力机制中相当于收集了全图的语义。
CLIP架构#
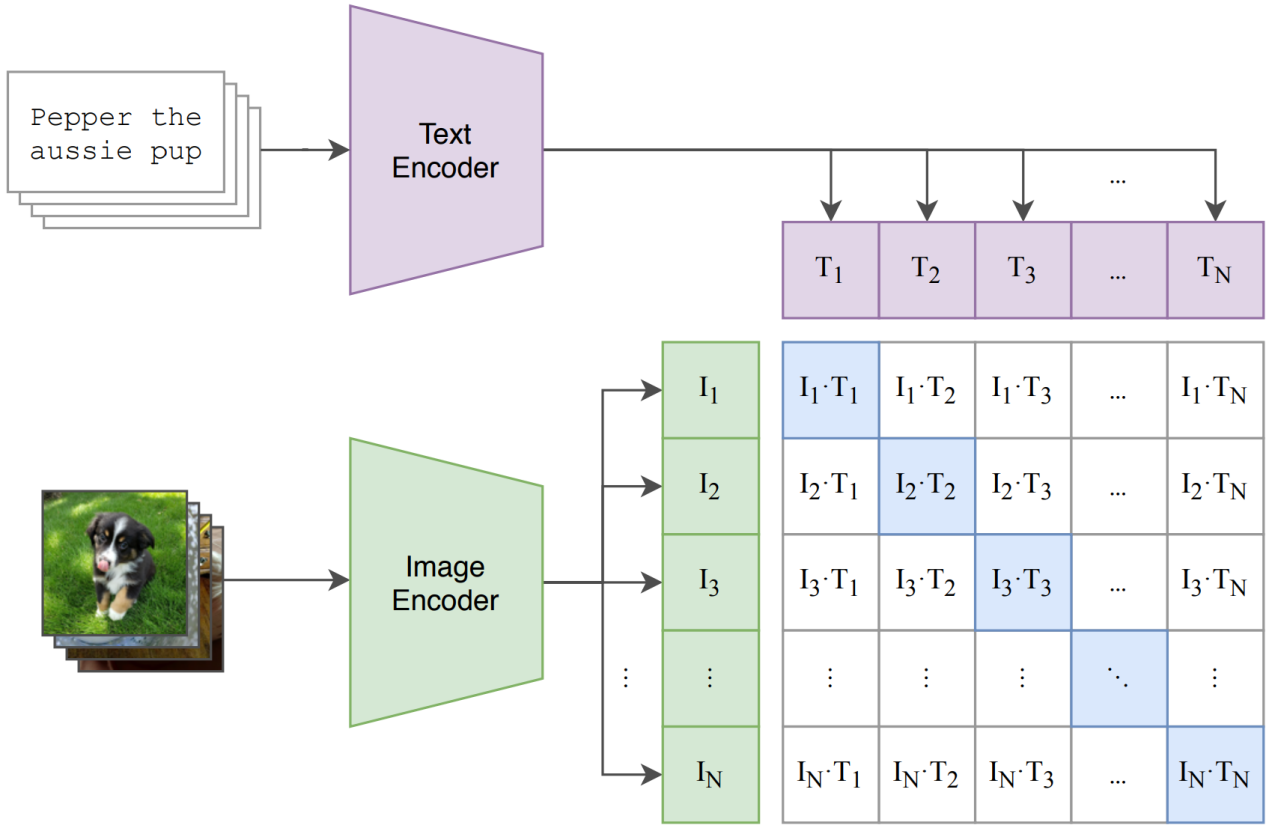
CLIP的架构就是一个图像编码器+文本编码器+投影层的双塔结构,在同一个嵌入空间里通过对比学习实现图文对齐。
双塔结构(Two-Tower)#
图像编码器(Image Encoder):可以是ResNet或Vision Transformer(ViT),输入图像后得到一个全局图像特征向量。#
文本编码器(Text Encoder):是Transformer(类似GPT/BERT的结构),输入tokenized的文本后,取最后的[EOS]向量作为整句的表示。#
共同嵌入空间(Joint Embedding Space)#
两个编码器输出的特征会通过一个线性投影层(Projection Head)映射到同一个维度空间。这样图像和文本就可以直接比较相似度。
对比学习训练目标(InfoNCE Loss)#
在一个batch内,模型会计算所有图像和文本之间的相似度(点积/cosine similarity)。正确的图文对被拉近,错误的被推远。
Q投影层的作用是什么#
在CLIP里,图像编码器和文本编码器出来的特征,原本不在同一个空间:
图像特征可能来自CNN/ViT,分布和尺度不同;#
文本特征来自Transformer,也有自己的分布。#
如果直接拿它们比相似度,效果会很差。
投影层(Projection Layer)的作用就是:
- 统一维度:把图像和文本特征映射到相同的维度空间,方便对齐。
- 对齐表征空间:通过可学习的线性变换,让两种模态的特征在一个共享语义空间里可比较。
- 简化训练目标:投影之后,可以直接用点积或余弦相似度计算图文对的相似性,再配合对比损失来优化。
扩散模型#
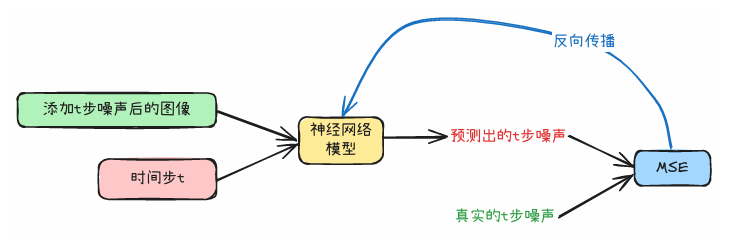
扩散模型架构一般分为前向扩散和逆向扩散:
前向扩散(Forward Diffusion)指的是:在训练阶段,我们从一张干净的原始图像开始,按照预设的噪声调度表,一步一步往图像里加高斯噪声。
一开始,图像还很清晰;
随着步数增加,噪声越来越多,图像内容逐渐模糊;
直到最后几步,图像几乎完全变成随机噪声。
这样做的目的,是构造一个“破坏过程”,让模型学会如何在反向过程中把噪声去掉、逐步恢复出清晰的图像。
逆向扩散(Reverse Diffusion):在推理或采样阶段,模型从一张几乎完全是噪声的图像开始,一步一步去掉噪声,逐渐还原出清晰的图像。
每一步,模型都会根据输入的带噪图像和时间步,预测出当初加进去的噪声。
然后把噪声减掉,得到更干净的。
这样不断迭代,噪声逐渐减少,图像内容越来越清晰。
最终,经过多步去噪,就能从随机噪声生成出符合分布的真实图像。
Q扩散模型在训练模型时,预测目标是什么#
在扩散模型的训练里,预测的目标其实就是加在原始图像上的噪声。
具体来说:#
我们从一张干净的图像出发,逐步往里面加高斯噪声,得到不同噪声水平的。
模型的任务就是:给定和时间步,预测出当初加进去的噪声。
这样在反向采样的时候,我们就能通过“减掉这个噪声”一步一步把图像还原回来。
所以总结一下:#
训练阶段:预测噪声,用L2损失去拟合。
生成阶段:用预测的噪声把带噪图像逐步去噪,直到得到清晰图像。
Q为什么扩散模型要对X0步加上的噪声算L2损失?这和Xt-1步的状态有什么联系#
在扩散模型里,我们的目标是学会“从噪声逐步还原出原始图像”。训练时会给加噪声,得到带噪声的图像。模型的任务就是在已知的情况下,去预测当初加上的噪声。
为什么用L2损失?#
因为我们假设加的噪声是高斯分布。对高斯分布来说,最大似然推导的结果就是等价于一个L2(均方误差)损失。
换句话说,用L2去拟合噪声,就是在做“最大化真实噪声分布的似然”。
这和有什么关系?#
在采样的时候,我们不是直接预测,而是一步一步从还原出,再从还原,直到走到原图。
这里关键在于:如果模型能准确预测噪声,那就能把去噪成一个更干净的图像,即得到。
所以说,学习预测噪声(并用L2来训练)和一步步生成是直接挂钩的。预测噪声准确,去噪过程才能稳定,最终才能生成清晰的。
QUnet网络结构#
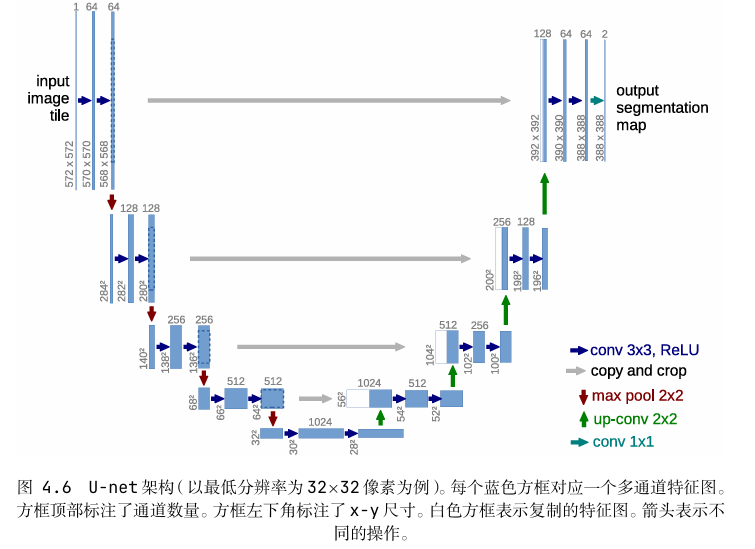
U-Net是一种最早用在医学图像分割上的神经网络结构,它的名字来自它的形状,像字母U。核心思想是:
编码器部分(左边下采样):逐层卷积+池化,把图像分辨率降下来,提取越来越抽象的语义特征。
解码器部分(右边上采样):逐层上采样,把低分辨率的特征图恢复成高分辨率,逐步还原空间信息。
跳跃连接(skip connections):编码器的特征会直接传给对应层的解码器,这样既能利用全局语义信息,也不会丢掉局部细节。
因为有这种“下采样提语义+上采样还原细节+跳跃连接补充信息”的设计,U-Net在处理需要同时关注全局和局部的任务时特别有效。
QUnet在扩散模型中的作用#
在扩散模型里,U-Net常作为核心网络来预测噪声:
编码器负责理解带噪图像的全局特征;#
解码器逐步恢复图像结构;#
跳跃连接保证了模型能同时保留细节和语义。#
如何处理prompt和生成的图像不对齐的问题#
在扩散模型里,prompt和生成图像不对齐,本质上是语言条件没有被很好地映射到图像生成过程。常见的解决思路有几类:
加强文本编码#
如果prompt的语义没有被准确理解,模型就会偏离。
可以用更强的文本编码器(比如更大的Transformer、或者经过图文对比学习的CLIP编码器),让模型更清楚地理解prompt的含义。
优化条件注入方式#
现在主流方法是用交叉注意力把文本特征融入到图像生成。
如果对齐度不够,可以在更多层次、或者更细粒度上注入条件,让模型在生成的每一步都能参考prompt。
增加训练时的对齐约束#
在训练过程中,可以引入额外的损失函数,比如CLIP对比损失,让生成结果和prompt在语义空间里更接近。
这样不仅学会生成图像,还强制学会“和文字对上号”。
采样和后处理技巧#
在推理阶段,用classifier-freeguidance(CFG)增强条件的影响力,让模型更听prompt。
或者生成多个候选图像,再用CLIPscore筛选出和prompt更贴合的结果。
总之,处理prompt和图像不对齐的问题,核心就是四步:文本要理解准→条件要注入好→训练要加对齐约束→推理要有调控和筛选。这样才能保证文字和图像一致。