项目周期#
- 1人团队,总计约3周。
- 需求分析与技术选型2天
- 数据准备与预处理5天
- 模型开发与训练3天
- 推理模块开发2天
- 系统集成与后端对接3天
- 部署上线2天
功能介绍#
根据商品标题,自动预测商品所属的三级类目,快速完成商品录入。

实现流程#
Q文本分类#
上述功能的本质就是一个文本分类任务,此处选择使用bert-base-chinese模型实现。如下图所示:
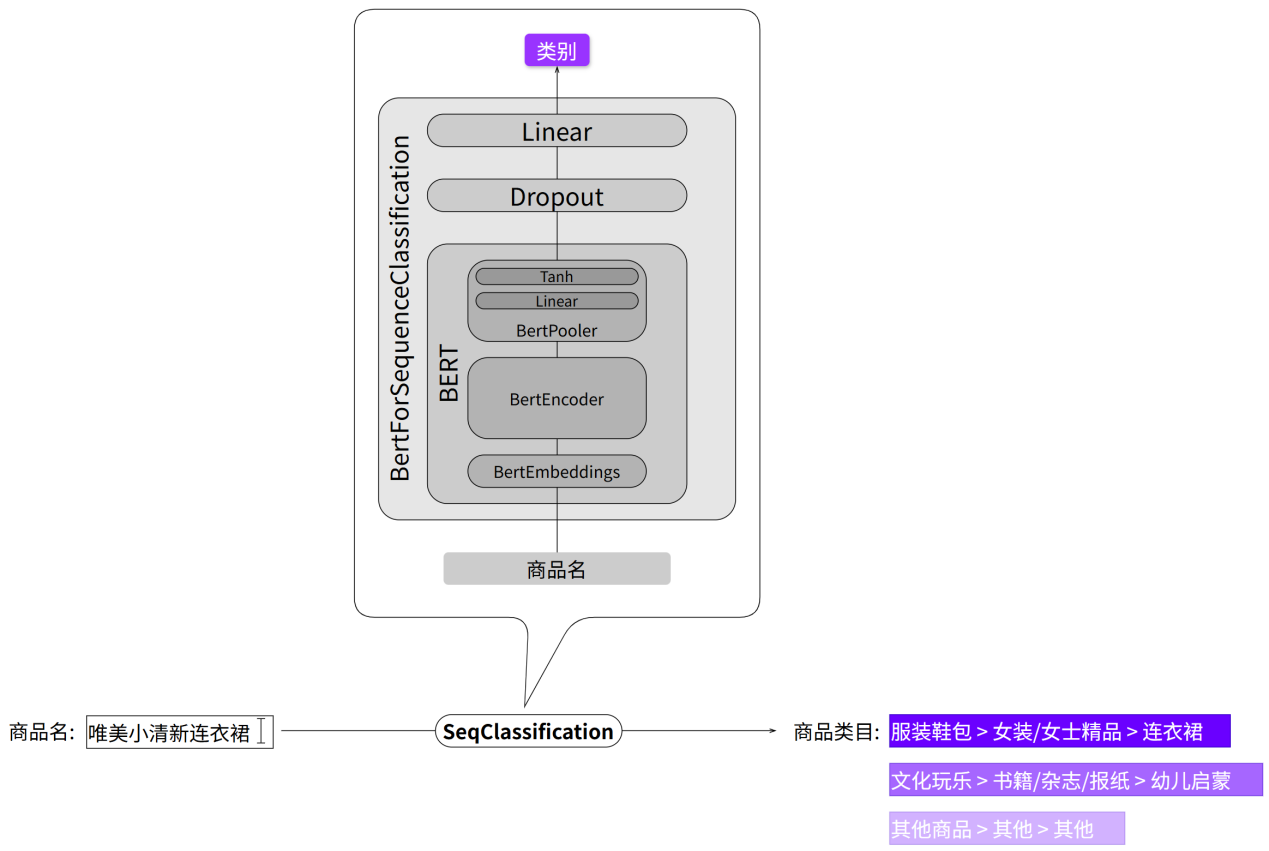
技术细节#
Q构建数据集#
数据集来自实际的业务数据库,spu_info和base_category1、base_category2、base_category3。
项目的目标是分别预测商品所属的一级分类、二级分类和三级分类,由于这三级分类存在严格的层级关系,因此只需预测三级分类,即可根据结果反推其所属的二级分类和一级分类。
所以训练集的格式为spu_namebase_category3。
由于数据库中的商品存在分类不均衡的问题,所以我们又通过大模型生成了一部分的小类别样本。
Q微调模型#
具体参数细节如下表:
面试串讲#
这个智能商品发布项目的主要职责就是辅助商家更高效地发布商品,主要包含如下几个功能模块:
第一,根据用户上传的商品图片自动生成商品标题
第二,根据商品标题预测商品所属品类
第三,复刻其它平台相同商品的视频简介
我负责的主要是第二个模块,这个模块相对比较简单。其具体任务是分别预测商品所属的一级分类、二级分类和三级分类,由于这三级分类存在严格的层级关系,因此,其实只需预测三级分类即可,然后再根据结果反推其所属的二级分类和一级分类。所以这个任务本质上就是一个简单的文本多分类任务。
下面我介绍一下实现细节,首先是数据集的构建,原始数据就来自我们的业务数据库,差不多有50万条样本,但是数据存在类别分布不均的问题,也就是一些冷门类别,商品较少,所以为了保证数据的均衡,我们随机删掉了一部分的热门类别下的商品,然后有使用大模型生成一部分的冷门类别的商品。
然后分类模型选用的就是bert-base-chinese,基于Huggingface的Transformers库进行训练,在一张V100显卡上训练了一个小时,最终的F1能达到将近70%,因为类别比较多,所以得分不是特别高。以上就是这个模块的全部内容。