项目周期与分工#
- 3人团队,一个半月
- 需求分析&设计2周
- 核心功能开发2周
- 前端开发&集成2周
- 测试&优化&上线2周
Q第一阶段:需求分析与架构设计(week 1-2)#
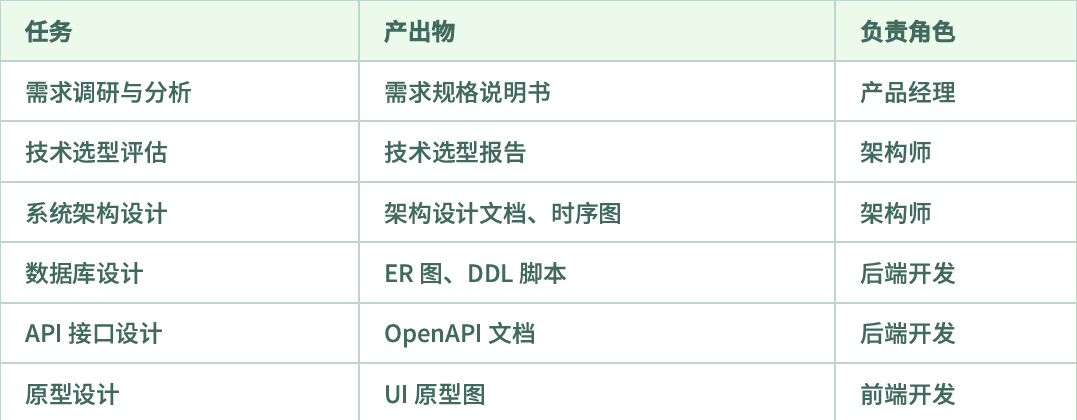
Q第二阶段:核心功能开发(week 3-4)#
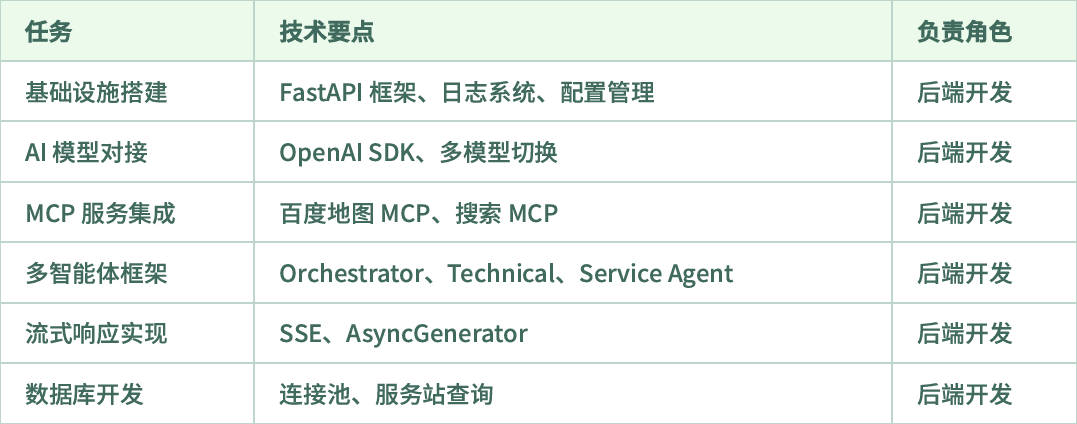
Q第三阶段:前端开发与联调(week 4-5)#

Q第四阶段:测试与上线(week 5-6)#
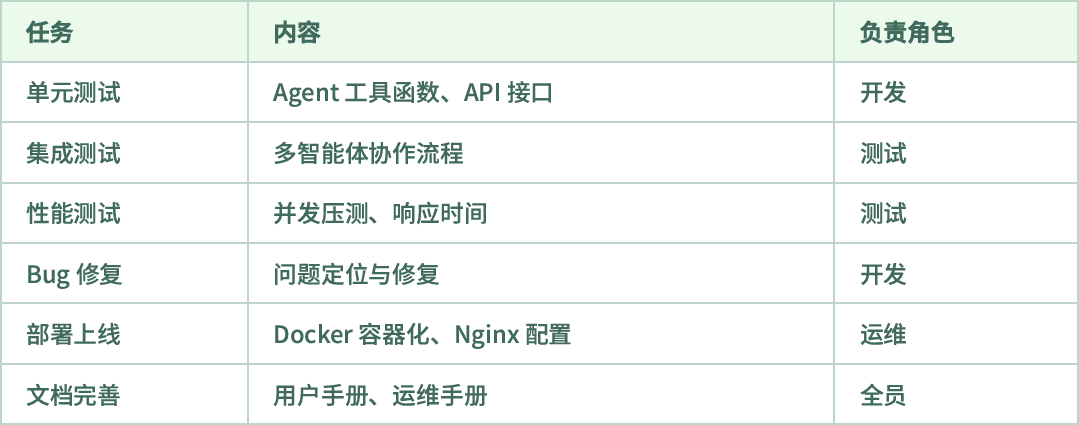
Q团队分工建议:#
后端开发(1-2人):API开发、多智能体框架、MCP集成,数据库
前端开发(1人):Vue界面、SSE处理、Markdown渲染
架构/全栈(1人):架构设计、技术攻关、Code Review
项目概述#
Q项目背景#
为企业客户提供⼀站式智能客服解决⽅案,涵盖技术咨询、实时资讯查询、线下服务站定位与导航等功能。
技术咨询:解答⽤⼾的技术问题(如系统蓝屏、软件故障等)。
实时资讯:提供股票⾏情、天⽓预报、新闻等实时信息 。
服务站查询:基于用户位置推荐最近的线下服务站并提供导航。
Q技术选型#
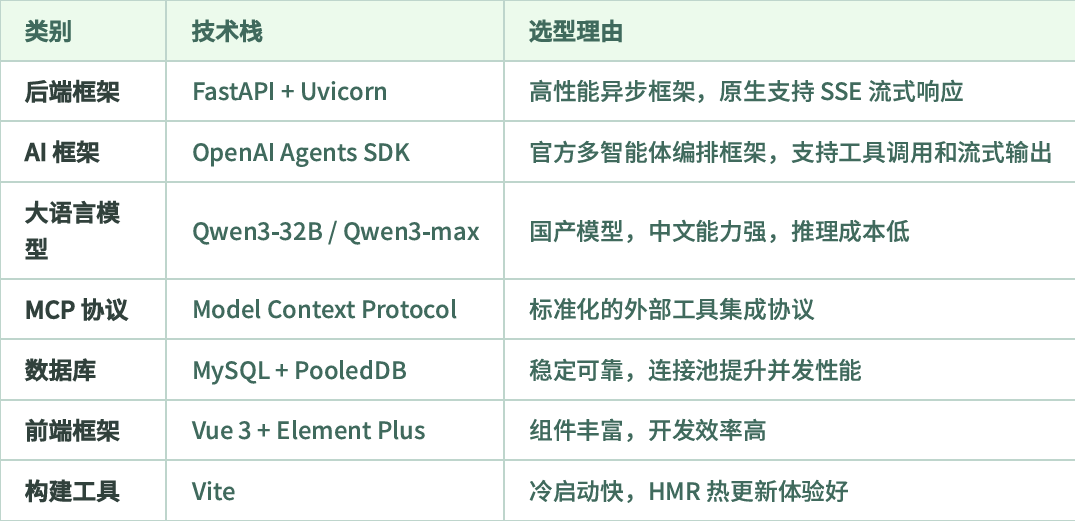
整体架构设计#
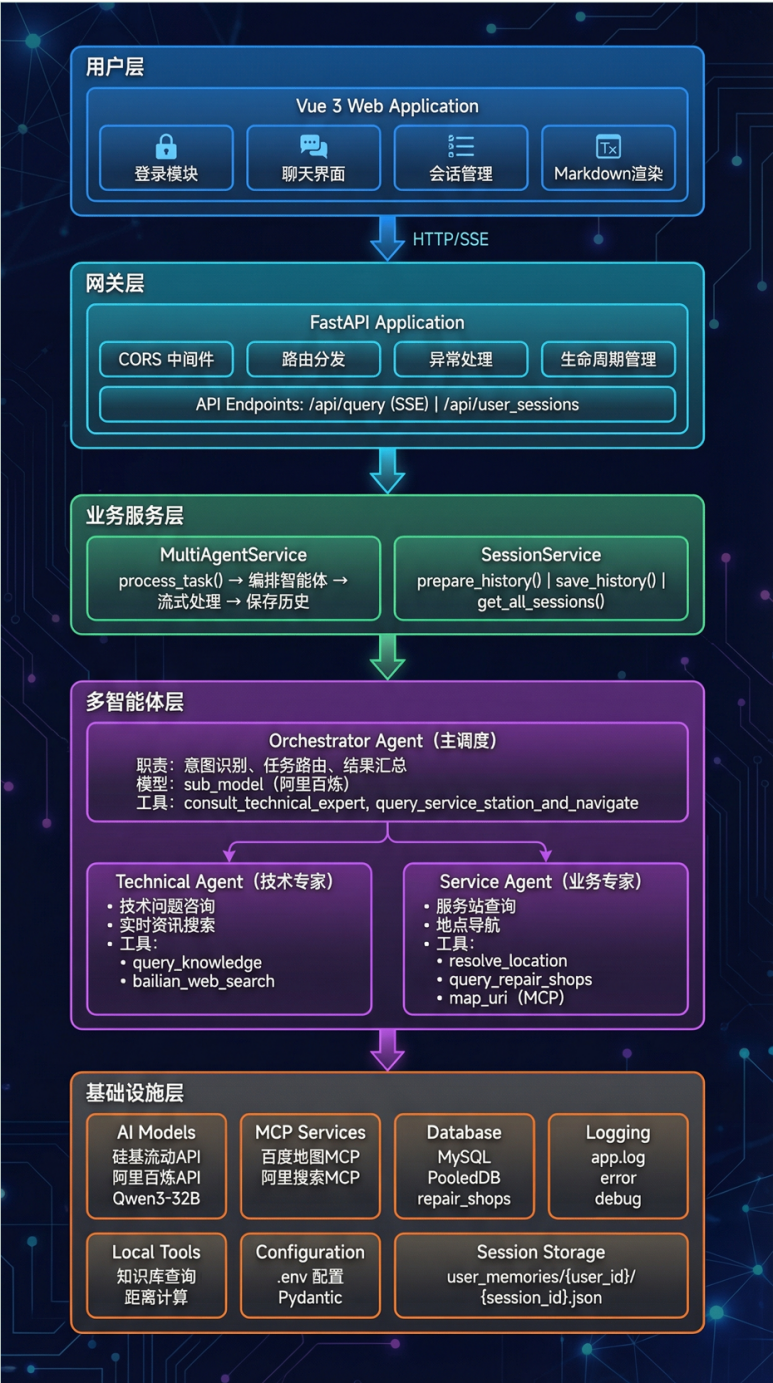
Q系统架构#
Q多智能体协作原理图#
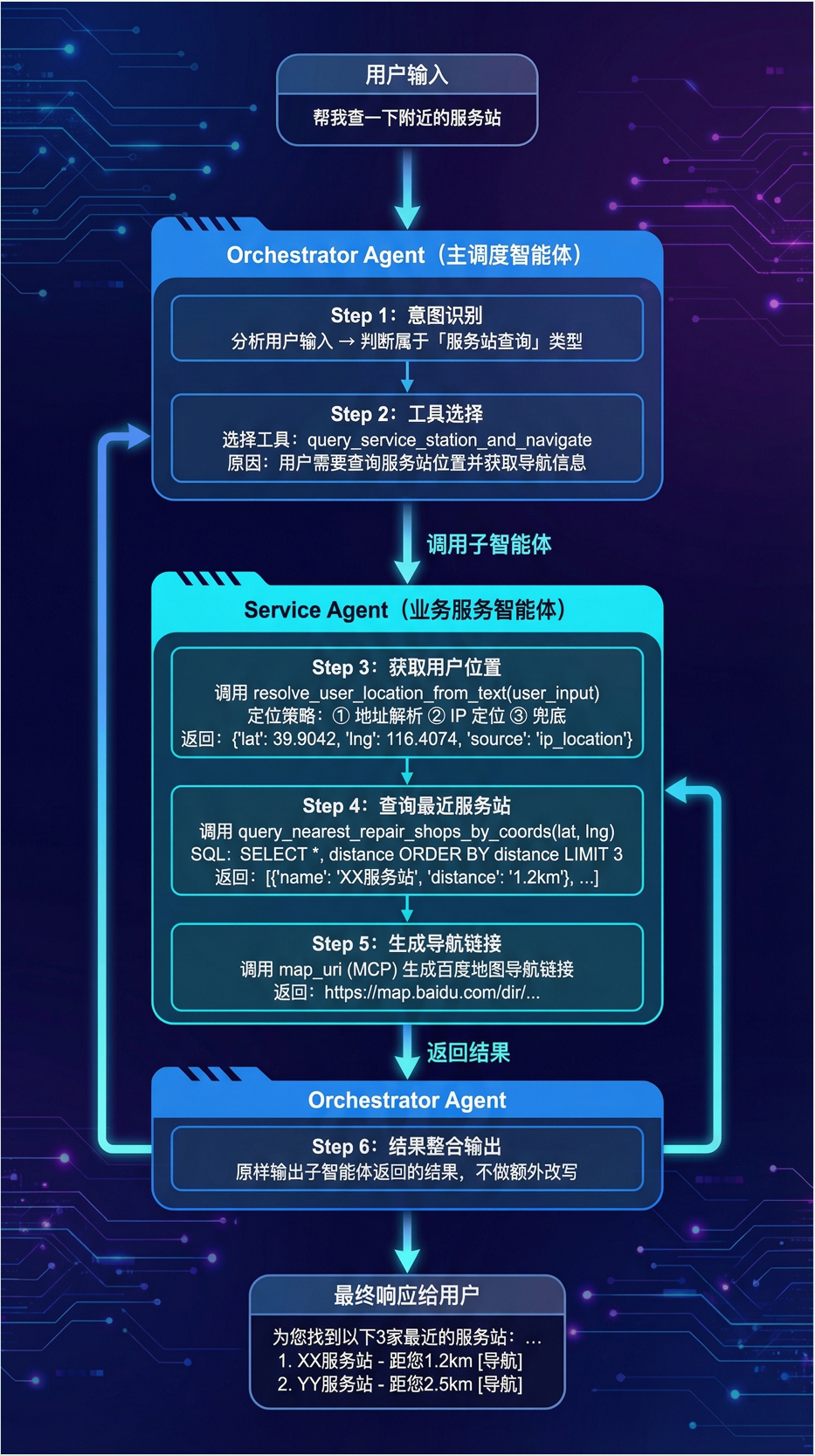
Q数据流向图#
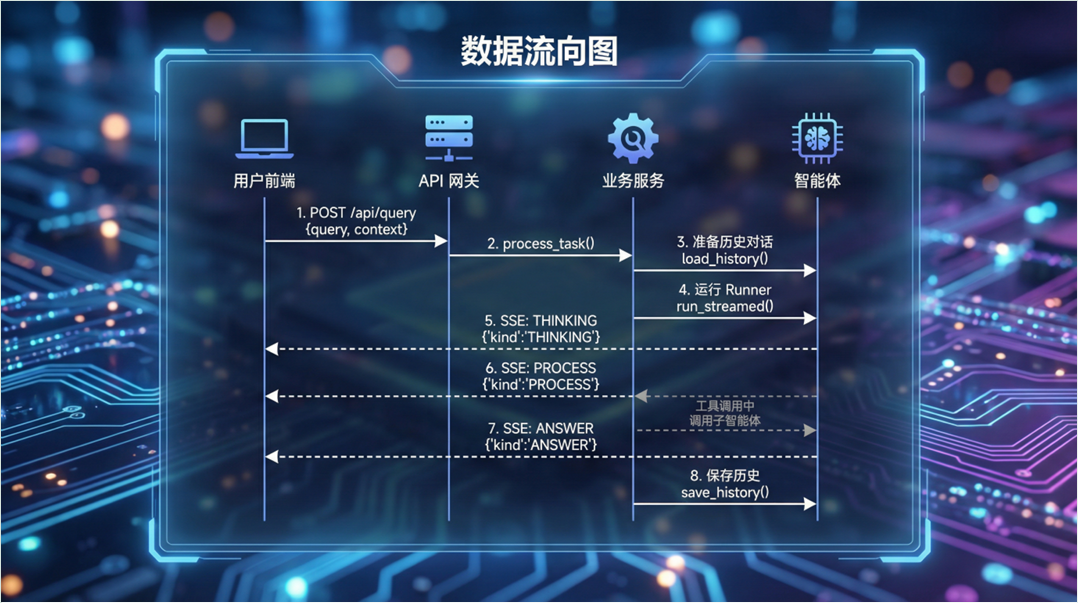
核心模块实现#
Q多智能体编排模块#
架构设计#

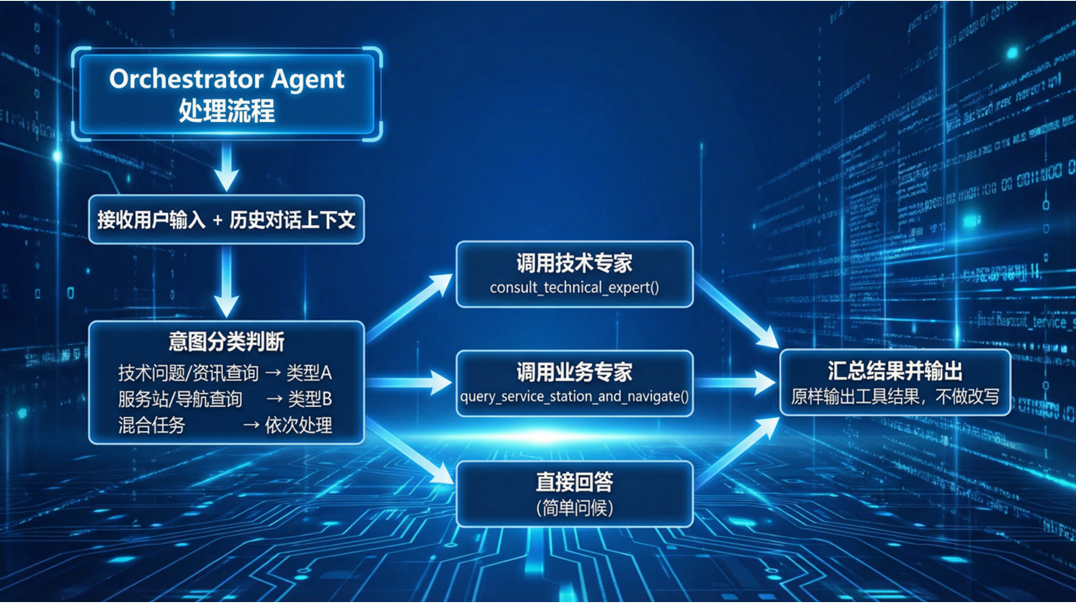
主调度智能体实现流程#
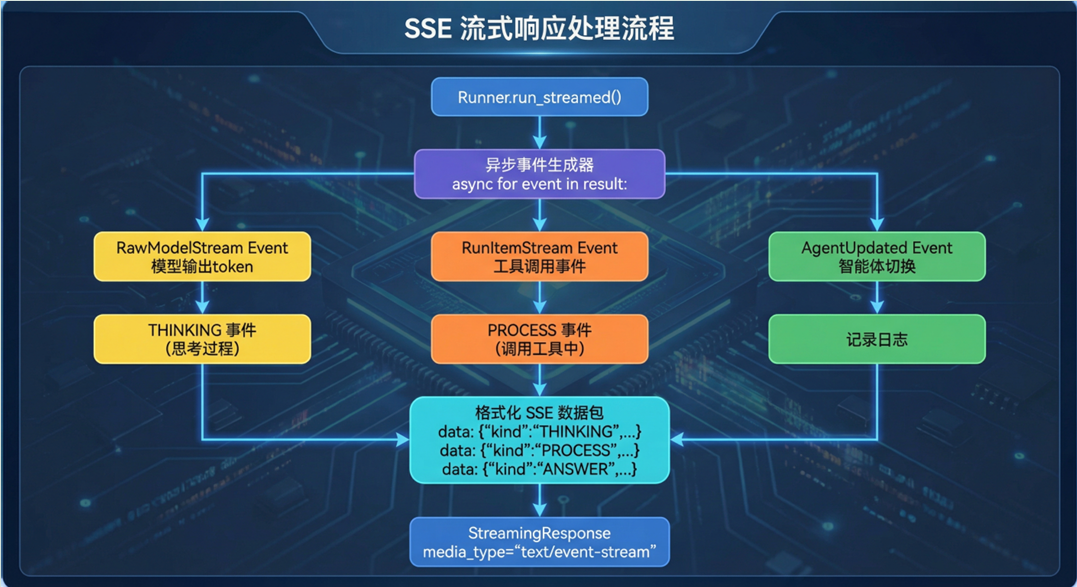
Q流式响应模块流程#
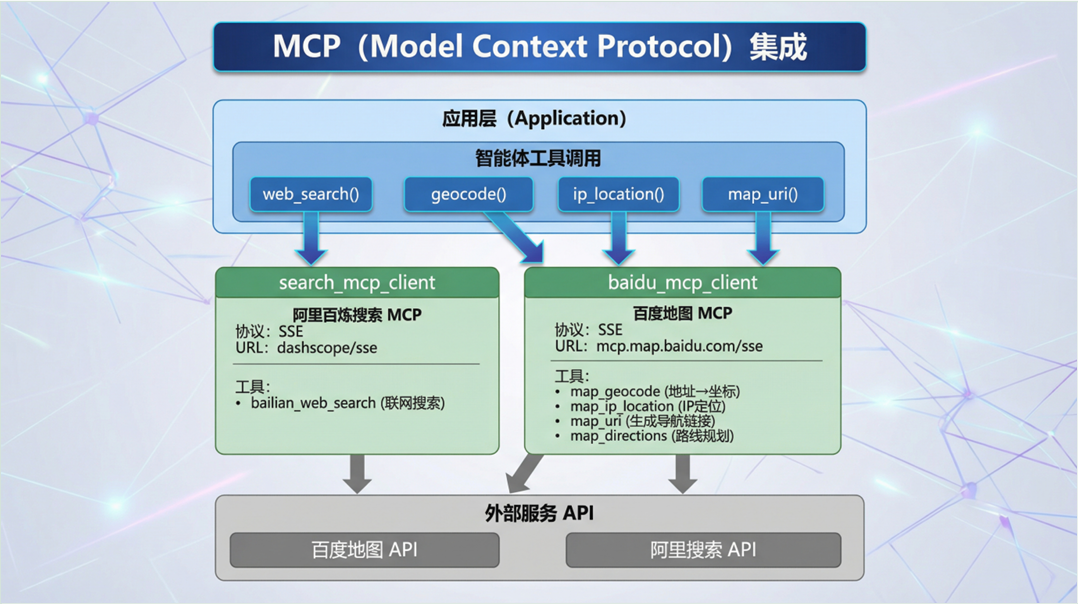
QMCP服务架构图#
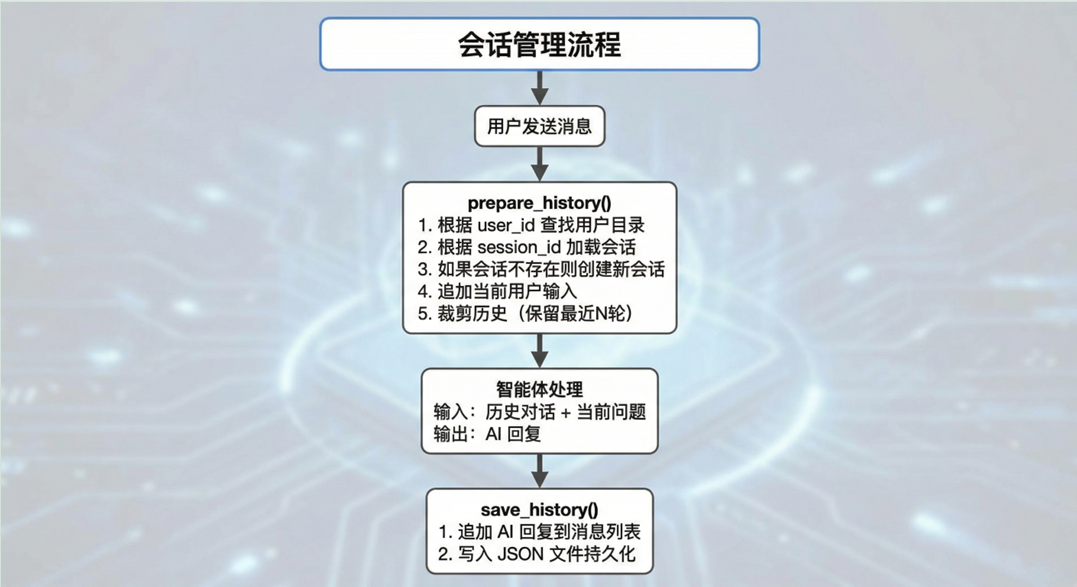
Q会话管理模块#
会话存储架构#

会话管理流程#
技术细节与痛点(常问!!!)#
Q核心技术点#
多智能体协作机制#
技术要点:#
- 分层设计:主调度+专家的两级架构,职责分离
- 工具转换:使用@function_tool装饰器将子智能体包装为工具
- 上下文传递:通过工具参数传递用户原始输入
- 异步执行:子智能体内部使用Runner.run()独立运行
设计优势:#
优势1:可扩展性强#
新增领域专家只需:
- 创建新的Agent定义
- 在工厂中注册为@function_tool
- 在主调度提示词中添加工具说明
优势2:故障隔离#
- 某个子智能体异常不会影响其他智能体
- 主调度可以捕获异常并返回友好提示
优势3:独立优化#
每个子只能体可以独立调优:
- 使用不同模型
- 使用不同的提示词
- 使用不同的工具集
SSE流式响应实现#
技术要点:#
- AsyncGenerator:Python异步生成器实现流式产出
- 事件分类:THINKING / PROCESS / ANSWER 三类事件
- 前端解析:ReadableStream + TextDecoder 逐块读取
- 状态管理:前端维护消息列表状态,实时更新 UI
数据格式:#

MCP协议集成#
技术要点:#
- 协议标准:Model Context Protocol 是标准化的⼯具集成协议
- 传输方式:使⽤ SSE (Server-Sent Events) 作为传输层
- 工具发现:MCP 服务⾃动暴露可⽤⼯具列表
- 生命周期:应⽤启动时连接,关闭时清理
集成模式:#

Q痛点问题与解决方案#
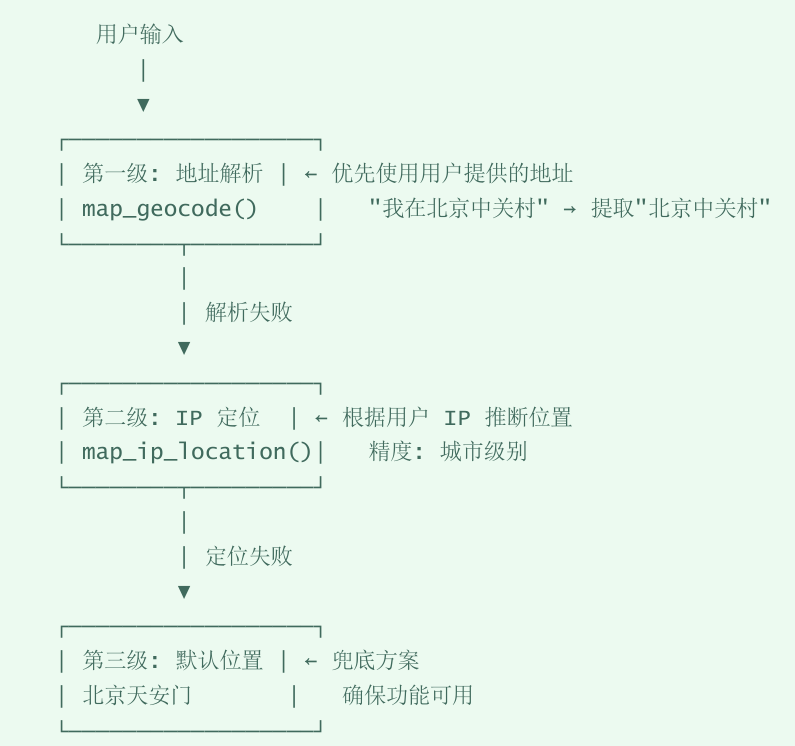
用户定位不准确问题#
问题描述:#
用户可能不提供具体地址,或提供的地址无法解析,导致服务站推荐不准确。
解决方案#
三级定位降级策略
智能体意图误判问题#
问题描述:#
用户输入模糊时,主调度智能体可能选择错误的子智能体处理。
解决方案#
提示词工程优化
核心原则:#
- 任务完整性原则:
只处理用户当前消息中“明确提到”的任务,禁止推测用户可能的隐含需求。
- 工具选择规则:
禁止事项:#
- 不要主动添加用户未提及的任务
- 不要对工具返回结果进行二次改写
- 不要在明确需求时推荐导航
并发请求数据库连接耗尽#
问题描述:#
高并发场景下频繁创建数据库连接导致性能下降或者连接耗尽。
解决方案#
连接池管理:
功能:#
连接池管理-创建和管理数据库连接的池子
连接复用-重复现有连接,避免频繁创建/销毁连接的开销
资源控制-限制并发连接数,防止数据库过载
线程安全-提供线程安全的连接获取机制
技术实现:#
单例模式:使用类变量_pool确保全局只有一个连接池实例
懒加载:只有在首次调用get_pool()时才创建连接池
使用DBUtils库:依赖dbutils.pooled_db.PooledDB实现连接池
PyMySQL驱动:使用PyMySQL作为MySQL数据库驱动程序
使用示例:

前端消息状态管理复杂#
问题描述:#
流式响应场景下,需要处理多种消息类型(思考、过程、答案),状态管理容易混乱。
解决方案#
消息类型分离与状态管理:
首先枚举消息类型:

然后定义状态变量:

THINKING类型消息处理:

ANSWER类型消息处理:

MCP服务连接不稳定的问题#
问题描述:#
外部MCP服务(百度地图、搜索引擎)可能出现网络波动或服务不可用。
解决方案#
优雅降级和错误处理:
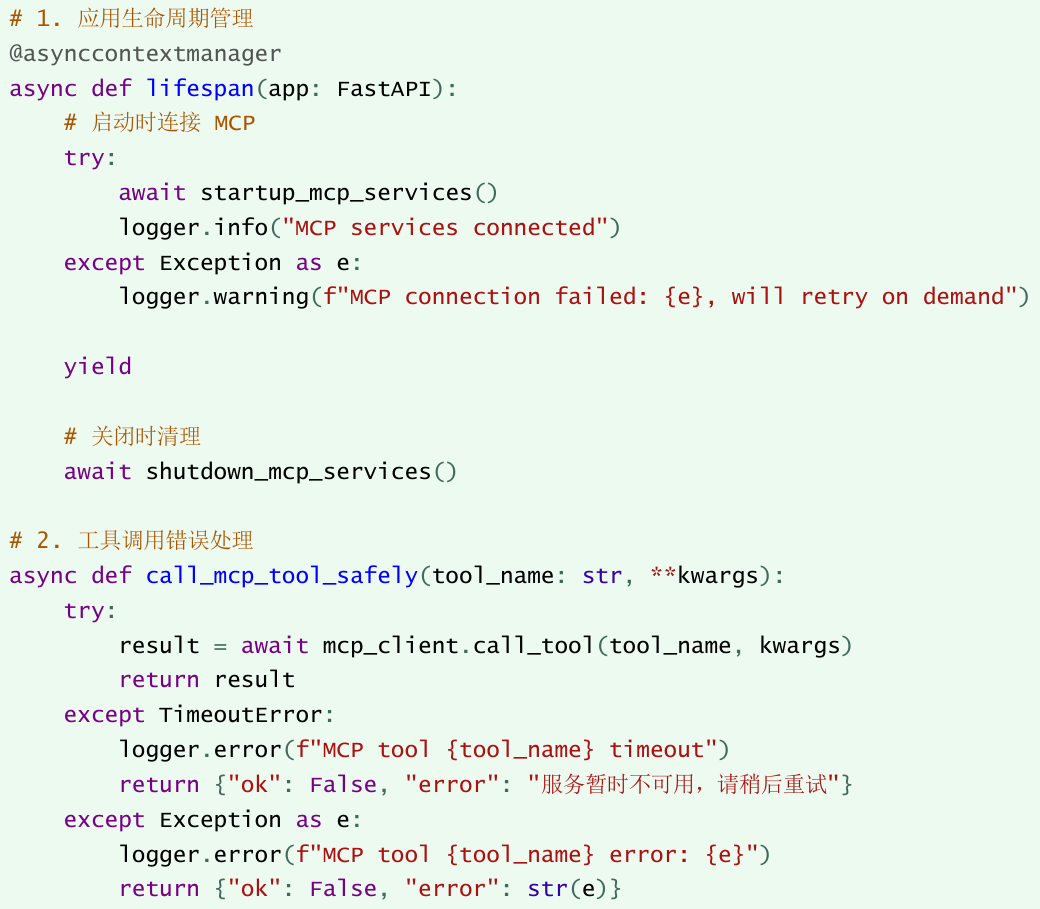
Q性能优化实践#
历史对话裁剪#

距离计算优化#
Haversine 公式

项目总结#
Q项目亮点#

Q技术收获#
OpenAI Agents SDK使用#
- 多智能体编排与协作
- @function_tool工具定义
- Runner流式执行机制
MCP协议实践#
- MCPServerSse客户端使用
- 工具自动发现与调用
- 生命周期管理
FastAPI开发经验#
- Pydantic数据验证
- AsyncGenerator流式响应
- CORS跨域配置
系统设计思维#
- 分层架构设计
- 容错和降级策略
- 提示词工程优化
Q可优化方向#
面试高频问题与回答#
Q项目介绍类#
问题1:简单介绍一下这个项目#
回答要点:这是⼀个基于多智能体架构的智能客服系统,主要服务于企业的线下服务⽹络。系统采⽤主调度 +专家的两级智能体架构,⽀持技术问题咨询、实时资讯查询、服务站定位与导航三⼤核⼼功能。技术上,后端使⽤FastAPI + OpenAI Agents SDK,通过MCP协议 集成百度地图和搜索引擎,前端使⽤ Vue 3,实现了流式响应的对话体验。 我在项⽬中主要负责多智能体框架设计和后端核⼼功能开发。
为什么选择多智能体架构而不是单一大模型?#
选择多智能体主要基于以下几点考虑:
职责分离:不同领域的问题由专门的智能体处理,便于独立优化提示词和工具
可扩展性:新增业务领域只需添加新的专家智能体,不影响现有功能
成本优化:主调度只做意图识别和路由,可以使用较小的模型;专家智能体根据任务的复杂度选择合适的模型
Q技术深度类#
SSE流式响应是如何实现的?和WebSocket有什么区别?#
实现方式:#
- 后端使用FastAPI的StreamingResponse,配合Python的AsyncGenerator生成SSE数据流。
- 前端使用fetch+ReadableStream 逐块读取,解析data:前缀的JSON数据
与WebSocket的区别#
对于AI对话这种只需要服务端推送的场景,SSE更简单且足够使用。
MCP(模型上下文工程)协议是什么?你是如何集成的?#
MCP(Model Context Protocol)是由Anthropic提出的标准化工具集成协议,用于让AI模型调用外部工具。
集成方式:#
使用MCPServerSse客户端连接MCP服务(如百度地图)
MCP服务会自动暴露可用工具列表(如geocode、ip_location)
在智能体定义时通过mcp_servers参数注册
智能体运行时可以像调用本地函数一样调用MCP工具
优势:#
标准化协议、工具自动发现、跨平台兼容。
数据库连接池是如何工作的?为什么要用连接池?#
为什么要用连接池?#
- 数据库连接创建开销大(TCP三次握手、认证等)
- 高并发时频繁创建/销毁连接会导致性能下降
- 数据库有最大连接数限制
工作原理:#
- 应用启动时预创建一定数量的连接(mincached)
- 请求到来时从池中获取空闲连接
- 请求结束后将连接归还到池中(而非真正关闭)
- 连接池维护最大连接数(maxconnections),超出时排队等待
我们的配置:使用DBUtils的PooledDB,最大5个连接,初始两个空闲连接。
Q问题解决类#
遇到过什么技术难点?如何解决的?#
回答示例一:用户定位问题#
问题:#
用户不一定会提供具体地址,导致无法准确推荐附近服务站。
解决方案:#
设计了三级定位降级策略
- 优先从用户输入中提取地址进行地理编码
- 如果没有地址,使用IP定位获取大致位置
- 如果IP定位也失败,使用默认位置(北京)作为兜底
这样保证了功能的可用性,同时尽可能提高定位精度。
回答示例二:流式消息状态管理#
问题:#
SSE返回的消息分为思考、过程、答案三种类型,需要分别渲染,状态管理容易混乱。
解决方案:#
- 定义统一的消息枚举类型
- 维护[当前正在接受的消息]的引用变量
- 根据SSE事件类型判断是追加内容还是创建新消息
- 消息发送完成后重置状态
如何保证系统的高可用?#
外部服务降级:MCP服务不可用时有兜底方案(如默认位置)
连接池管理:数据库使用连接池,避免连接耗尽
错误重试:智能体调用失败时支持自动重试
日志监控:多级日志(info/error/debug)便于问题定位
上下文裁剪:历史对话子保留最近N轮,避免token超限
Q设计思考类#
如果让你重新设计这个系统,你会做出哪些改进?#
回答要点:
引入向量数据库:使用Milvus/Faiss存储知识库文档,提升语义检索精度
对话摘要:长对话使用LLM生成摘要,而非简单裁剪
分布式部署:使用Kubernetes实现水平扩展
可观测性:集成OpenTelemetry实现分布式追踪
A/B测试框架:对比不同提示词和模型的效果
多智能体之间是如何通信的?#
本项目采用的是函数调用的通信方式:#
子智能体被包装为@function_tool装饰的函数
主调度智能体通过工具调用的方式调用子智能体
子智能体执行完成后,结果作为工具调用的返回值传回
这种方式的优点是:#
实现简单,不需要消息队列
同步调用,易于追踪调试
与OpenAI Function Calling原生兼容
如果是更加复杂的场景(如多智能体并行,异步协作),可能需要引入消息队列(如Redis/RabbitMQ)
Q项目延申类#
这个项目支持多少并发?如何进一步提升?#
当前瓶颈分析:#
数据库连接池5个连接
LLM API调用延迟较高(通常1-10秒)
单实例部署
提升方案:#
水平扩展:部署多个FastAPI实例,使用Nginx负载均衡
异步优化:确保所有I/O操作都是异步的
流控限速:保护LLM API,防止超限
连接池扩容:根据并发数量调整数据库连接池大小
面试口述版项目总结#
Q30秒版#
我参与开发了⼀个基于多智能体架构的智能客服系统。系统采⽤「主调度+专家」的两级架构,⽀持技术咨询、实时资讯和服务站导航三⼤功能。后端使⽤ FastAPI + OpenAI Agents SDK,通过 MCP 协议集成百度地图,前端使⽤ Vue 3 实现流式对话体验。我主要负责多智能体框架设计和后端核⼼开发。
Q2分钟版#
项目背景#
这是⼀个企业级智能客服系统,⽬标是为企业的线下服务⽹络提供智能化⽀持。用户可以通过对话 ⽅式咨询技术问题、查询实时资讯,以及定位附近的服务站并获取导航。
技术架构#
系统采⽤多智能体架构,分为三层:
主调度智能体:负责意图识别和任务路由
技术专家智能体:处理技术问题和资讯查询
业务专家智能体:处理服务站查询和导航
后端使⽤ FastAPI 框架,集成 OpenAI Agents SDK 实现智能体编排。通过 MCP 协议对接百度地图 和搜索引擎。前端使⽤ Vue 3,实现了 SSE 流式响应,⽤⼾能实时看到 AI 的思考过程。
我的职责#
我主要负责多智能体框架的设计与实现,包括智能体间的⼯具调⽤机制、SSE 流式响应的前后端实 现,以及⽤⼾定位的三级降级策略设计。
技术亮点#
项⽬有⼏个技术亮点:⼀是多智能体的⼯具化设计,⼦智能体被封装为可调⽤的⼯具;⼆是三级定 位策略保证了服务的可⽤性;三是完整的会话管理⽀持多轮对话。
Q5分钟版#
项⽬背景与⽬标#
这是⼀个企业级的智能客服系统,服务于企业的线下服务站⽹络。传统客服系统响应慢、⼈⼯成本 ⾼,我们的⽬标是通过 AI 技术实现 7x24 ⼩时的智能服务,覆盖三个核⼼场景:技术问题咨询、实 时信息查询、以及服务站定位导航。
整体架构设计#
系统采⽤前后端分离架构,分为四层:
展示层:Vue 3 + Element Plus,实现聊天界⾯和会话管理#
网关层:FastAPI 应⽤,提供 RESTful API 和 SSE 流式接⼝#
业务层:多智能体服务,包含主调度和两个专家智能体#
基础设施层:AI 模型、MCP 服务、MySQL 数据库、⽇志系统#
核⼼是多智能体协作机制:主调度智能体接收⽤⼾请求后,根据意图选择合适的⼦智能体处理。⼦智能体通过 @function_tool 装饰器包装为⼯具,这样主调度可以像调⽤函数⼀样调⽤它们。
核⼼技术实现#
流式响应:使⽤ FastAPI 的 StreamingResponse 配合 Python AsyncGenerator,将 AI 的思考过 程、⼯具调⽤、最终答案分类型推送给前端。前端通过 ReadableStream 逐块解析,实时更新 UI。
MCP 集成:MCP 是 Model Context Protocol,⼀种标准化的⼯具集成协议。我们⽤它对接百度地图服务,智能体可以调⽤地理编码、IP 定位、⽣成导航链接等能⼒。
定位策略:⽤⼾查询服务站时可能不提供具体地址,我设计了三级降级⽅案:优先解析⽤户输⼊中的地址,其次使⽤ IP 定位,最后兜底到默认位置。这样既保证了准确性,⼜确保功能可⽤。
遇到的挑战与解决⽅案#
最⼤的挑战是智能体意图误判。⽐如⽤户说「帮我看看」,可能是技术问题也可能是服务站查询。我们通过提⽰词⼯程优化,明确定义了每种意图的关键词特征,并设计了「只响应明确需求,不推 测隐含意图」的原则。
另⼀个挑战是前端状态管理。SSE 返回的消息有三种类型,需要分别渲染。我设计了消息类型枚举 和「当前消息引⽤」机制,确保追加内容时不会创建重复消息。
项⽬成果与收获#
项⽬最终实现了完整的智能客服功能,⽀持多轮对话和会话持久化。技术上,我深⼊理解了多智能 体架构设计、SSE 流式通信、MCP 协议集成。⼯程上,锻炼了从需求分析到架构设计再到编码实现 的全流程能⼒。
如果有机会重构,我会考虑引⼊向量数据库提升知识检索精度,以及添加 A/B 测试框架对⽐不同提⽰词的效果。
QSTAR法则回答模板#
问题:请介绍一个你解决过的技术难题#
S(Situation)-情境:#
在开发智能客服系统时,用户查询附近服务站经常定位不准
T(Task)-任务:#
我们需要设计一个可靠的定位方案,在各种情况下都能给出合理的位置
A(Action)-行动:#
我设计了三级降级策略:
- 优先解析用户输入中的地址(如‘我在中关村’)
- 如果没有地址,使用IP定位获取城市级位置
- 如果IP定位失败,使用默认位置(北京)作为兜底
同时我在返回结果中标注了数据来源,让用户知道结果的可信度
R(Result)-结果:#
方案上线后,服务站查询成功率从75%提升到99%,用户反馈定位准确性也明显提高。
Q常见追问#
技术亮点速记#
Q多智能体架构#
- 主调度+专家的两级设计
- 子智能体包装为@function_tool
- 职责分离、可扩展、故障隔离
QSSE流式响应#
- FastAPI StreamingResponse + AsyncGenerator
- 前端 ReadableStream + TextDecoder
- 三类事件: THINKING / PROCESS / ANSWER
QMCP协议集成#
- Anthropic 提出的标准化工具协议
- MCPServerSse 连接百度地图、搜索引擎
- 工具自动发现、跨平台兼容
Q三级定位策略#
- 地址解析 → IP 定位 → 默认位置
- 保证功能可用性的降级方案
Q数据库连接池#
- DBUtils PooledDB
- 避免频繁创建/销毁连接
- 最大 5 连接,初始 2 连接