项目周期#
- 1人团队,总计约3周。
- 环境搭建与SFT阶段1周
- 奖励模型训练与调试1周
- PPO强化学习阶段6天
- 评估与分析2天
功能介绍#
本项目目标是微调Qwen2.5-3B,使其能够生成符合人类偏好的文本。具体应用场景是:
新上线的商品因为缺少评论,不利于用户搜索和购买。所以需要生成一些正向评论。
输入一个与商品相关的提示词(如“这本书...”),模型输出一段正向情感的商品评论。
通过人类偏好建模(RLHF),避免生成负向或不合适的评论,使评论更契合业务需求(例如在电商网站中展示积极评论,用于用户引导、推荐场景)。
实现流程#
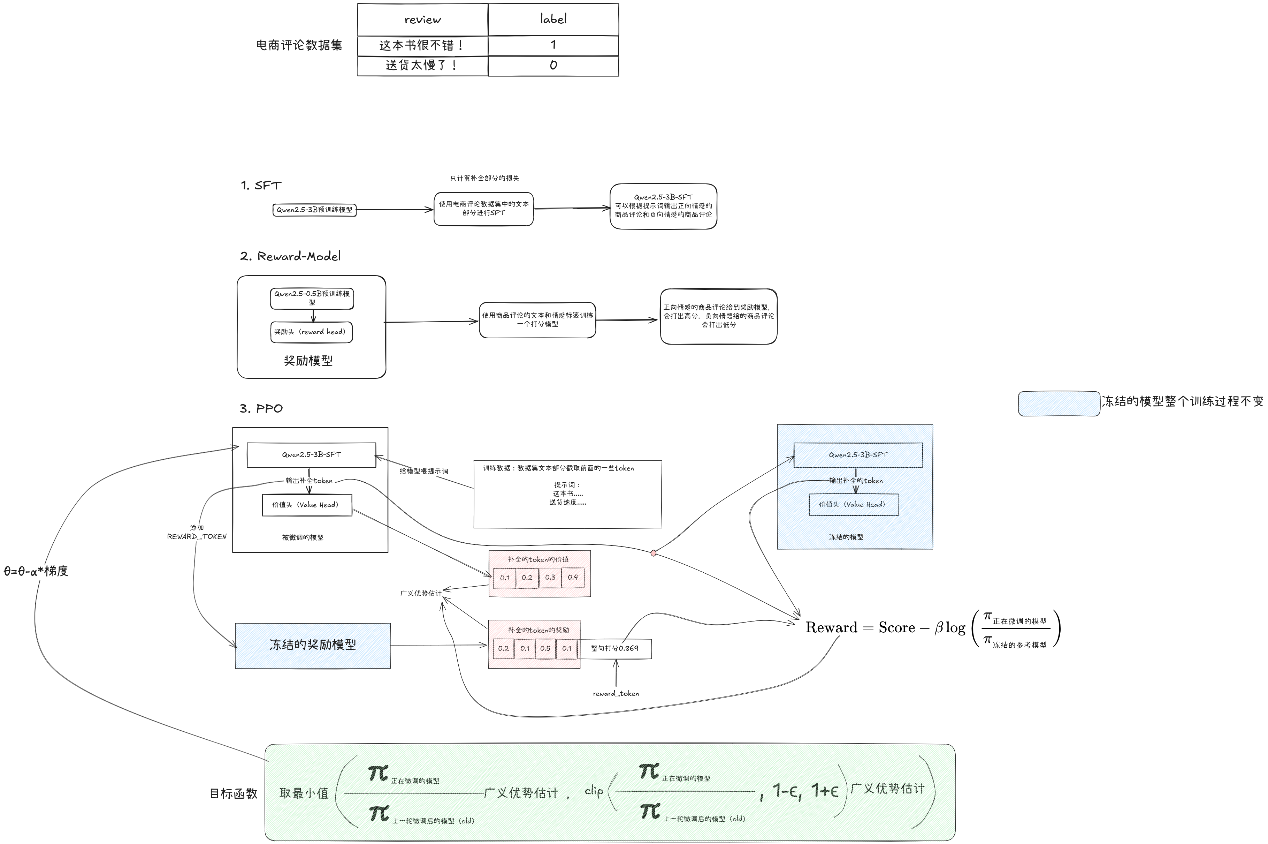
Q监督微调(SFT)#
使用电商评论数据集的文本部分对Qwen2.5-3B进行监督微调,得到Qwen2.5-3B-SFT,使模型具备商品评论生成能力。但此时输出既包含正向评论,也包含负向评论。
Q奖励模型训练(Reward Model)#
使用电商评论数据集的文本+标签训练奖励模型。模型结构为Qwen2.5-0.5B+reward head:
正向评论打高分
负向评论打低分
QPPO微调(PPO-RLHF)#
使用PPO算法微调Qwen2.5-3B-SFT,使其输出更偏向正向评论。流程如下:#
输入商品评论提示词,Qwen2.5-3B-SFT生成评论#
奖励模型打分(高分→提升生成概率,低分→降低概率)#
Qwen2.5-3B-SFT增加value head作为价值函数网络#
结合奖励与价值估计,使用广义优势估计(GAE)计算优势#
采用PPO-Clip裁剪目标优化策略,保证更新稳定#
引入KL散度惩罚,避免策略偏离初始的sft模型太远#
技术细节#
Q监督微调(SFT)#
模型结构:Qwen2.5-3B(3B参数)
数据集:电商评论数据集的文本部分(约10万条电商文本)
目标:让Qwen2.5-3B具备生成商品评论的能力
超参数
- 批次大小:32
- 学习率:2e-5
- 训练轮数:1 epoch
- 优化器:AdamW(weight decay=0.1)
- 学习率调度:5%预热+余弦退火
- 训练环境:单机A800 80G,耗时约3小时
Q奖励模型(Reward Model)#
模型结构:Qwen2.5-0.5B+reward head(线性层二分类)#
数据集:电商评论数据集文本+标签#
目标:学习区分正向与负向评论,并给出奖励值#
损失函数:二元交叉熵#
超参数#
- 批次大小:32
- 学习率:1e-5
- 训练轮数:3epoch
训练环境:单机V100 32G,耗时约0.3小时#
Q策略优化(PPO-RLHF)#
模型结构:Qwen2.5-3B-SFT+value head#
输入输出:#
- 输入:商品评论提示词
- 输出:带正向情感的商品评论
奖励函数:#
- r=reward model打分
加入KL惩罚#
优势函数:广义优势估计(GAE),=0.99,=0.95#
优化目标:PPO-Clip(=0.2)#
超参数#
- 批次大小:64
- 学习率:1e-5
- PPO更新步数:4
- KL系数:0.1
- =0.99,=0.95
- 剪切范围=0.2
训练环境:2张A800 80G,耗时约12小时#
总结#
PPO项目的业务目标是:让Qwen2.5-3B-SFT输出正向情感的商品评论。
实现流程为#
使用电商评论数据集对Qwen2.5-3B做SFT,使其会写商品评论#
使用电商评论数据集中的文本+标签训练奖励模型,学会区分正负情感#
使用PPO-RLHF微调SFT模型,使其在KL约束下更倾向输出正向评论#
核心亮点#
业务价值:模型生成的评论更加积极正面,符合平台对“正向内容”的需求#
方法价值:完整复刻了InstructGPT的RLHF流程(SFT→RM→PPO),并应用于情感控制任务#
技术细节#
SFT提供基本写评论能力#
奖励模型提供情感方向监督#
PPO在KL约束下对齐输出,保证稳定与安全#
最终效果#
在商品评论提示词下,模型生成的评论整体呈现正向、积极、乐观的风格,避免了负面表达。
串讲#
本项目的需求是:让Qwen2.5-3B能够生成符合人类偏好的文本。在我们的业务场景里,就是希望模型在输出商品评论时,更偏向正向情感。
为此,我们完整复刻了OpenAI Instruct GPT的RLHF流程,分成三个阶段:监督微调、奖励模型训练和PPO微调。
首先是监督微调阶段。我们用电商评论数据集里的文本对Qwen2.5-3B进行SFT训练,得到的Qwen2.5-3B-SFT模型学会了写商品评论。不过这个阶段的模型输出既有正向评论,也会生成负向评论。
接下来是奖励模型。我们在Qwen2.5-0.5B后面加了一个reward head,使用电商评论数据集的文本加标签进行训练。正向评论给高分,负向评论给低分,这样奖励模型就能对评论情感进行打分。
最后是PPO微调。我们把SFT模型作为actor,并在它后面加一个value head作为critic。训练时输入商品相关提示词,模型生成评论交给奖励模型打分,打分高的评论会增加其生成概率,打分低的会降低概率。同时我们引入KL散度惩罚,避免模型偏离原始SFT太远;在计算优势时采用广义优势估计GAE;在优化时使用PPO-Clip裁剪目标,保证更新稳定。经过这一阶段,模型基本学会了在给定商品提示词时,输出正向的、积极的商品评论。
整体来看,项目实现了从“会写评论”到“写积极评论”的转变,技术路径是 SFT提供写评论能力,奖励模型提供情感偏好信号,PPO在约束下对齐人类偏好。最终效果是:模型生成的评论不仅流畅连贯,而且情感更偏正向,符合业务需求。