分布式训练技术#
Q分布式训练及显存优化技术有哪些#
数据并行(Data Parallelism,DP)#
流水线并行(Pipeline Parallelism,PP)#
张量并行(Tensor Parallelism,TP)#
3D并行(DP、PP、TP混合)#
ZeRO(零冗余优化器)#
专家并行#
Q什么是数据并行?#
数据并行就是把同一个模型复制到多个设备上,每个设备处理不同的数据子集,各设备独立计算前向和反向传播,然后通过通信(如AllReduce)把梯度聚合,最后同步更新模型参数。
一句话总结:模型相同,数据切分,梯度同步。
Q数据并行(中的梯度聚合)如何提升通信效率#
Ring AllReduce:https://www.jianshu.com/p/8c0e7edbefb9
Q介绍RingAllReduce#
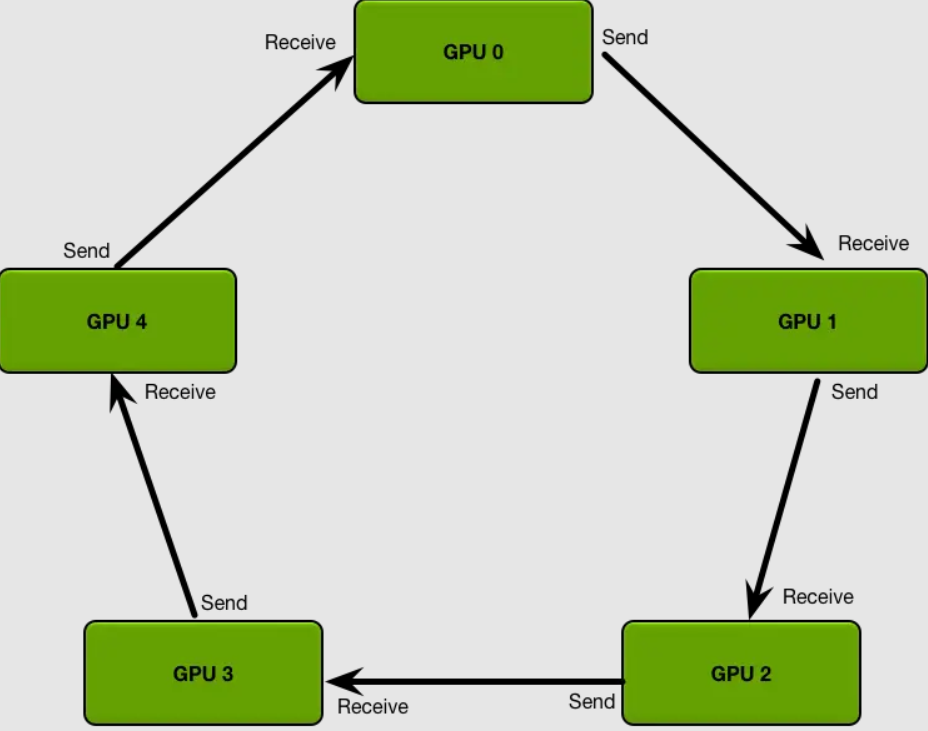
RingAllReduce是一种高效的分布式通信算法,用于数据并行训练中同步梯度。它将每个节点的梯度拆分为N份,节点按环形结构依次发送和接收梯度块,经过N‑1轮通信完成全局求和(Reduce-Scatter),再经过N‑1轮广播(All-Gather)让每个节点获得完整的全局梯度。
RingAllReduce将通信压力均衡到所有节点,避免了瓶颈的出现。
Q数据并行中计算与通信如何协同#
每个GPU计算自己批次的梯度,然后通过Ring-AllReduce同步:
每个GPU先计算本地梯度 → 通过AllReduce汇总并同步所有GPU梯度 → 每个GPU用汇总梯度更新本地模型。
Q什么是流水线并行#
把模型分段(Stage),每段交给不同的GPU,数据串行经过不同的模型分段。
Q流水线并行优缺点#
- 优点:降低显存压力;提高计算资源利用率 ;适合超大模型
- 缺点:通信/同步复杂,流水线气泡(Pipeline Bubble),难以负载均衡
Q什么是张量并行#
张量并行的做法是将模型单层内部的张量计算拆分到多个设备上并行执行,每个设备仅持有部分权重和中间结果。其目标仍是突破单设备显存和计算能力的限制,使超大模型的单层也能在多设备上协同完成。
Q张量并行优缺点#
- 优点:减少单卡显存占用,可训练更大模型;加速前向和反向计算。
- 缺点:跨设备通信频繁,带宽成为瓶颈;实现和调试复杂;扩展性受层结构限制。
Q什么是 3D并行#
同时结合数据并行、张量并行和流水线并行的分布式训练策略。
Q什么是专家并行?#
专家并行的做法是将 Mixture-of-Experts(MoE)模型中的多个专家(Expert)分配到不同的设备上,每个设备仅存储和计算部分专家。
MoE 结构天然适合并行化:每个专家本质上是一个独立的前馈网络(FFN),彼此之间没有共享参数或依赖关系,因此可直接将不同专家切分并分布到多个设备上。
Q什么是DeepSpeed ZeRO#
DeepSpeed ZeRO(Zero Redundancy Optimizer,零冗余优化器)是一种显存优化技术,目的是解决数据并行多个实例冗余存储的问题。
分三个阶段(三种优化级别)
ZeRO-Stage 1:拆分优化器状态。#
ZeRO-Stage 2:拆分优化器状态和梯度。#
ZeRO-Stage 3:拆分优化器状态、梯度和模型参数。#
这里的拆分是指存储到不同的DP实例。
Q什么是DeepSpeed Offload?优缺点?#
DeepSpeed Offload(卸载)是一种显存优化策略,将部分计算或数据从GPU移到CPU或NVMe(硬盘)上,以减轻GPU显存压力。
主要类型:
卸载权重。#
卸载优化器状态。#
卸载梯度。#
可以训练显存远大于GPU容量的模型,但带来额外的通信开销。
AMP混合精度训练#
Q什么是AMP#
AMP(Automatic Mixed Precision)是一种自动混合精度训练技术。
在训练时部分计算用半精度(FP16)进行,关键计算保持单精度(FP32),既保证数值稳定性,又减少显存占用并加速计算。
Q混合精度训练的优缺点#
- 优点:显存占用降低、训练速度加快。
- 缺点:数据溢出(通常是下溢)、舍入误差。
Q如何避免AMP的下溢和舍入误差#
- 损失缩放:在反向传播前乘以缩放因子,反向传播后除以相同因子再更新权重。
- FP32主权重副本:维护FP32精度的主权重副本用于权重更新。
显存相关#
Q如何估计训练推理阶段的显存占用(全参微调)?#
显存占用公式(以FP16/混合精度为例):
总显存 ≈ 模型参数显存 + 梯度显存 + 优化器状态显存 + 激活值显存 + 临时缓冲区
各个部分显存占用估算:
模型参数:对于参数为Φ的模型#
- FP32存储:4Φ字节
- FP16/BF16存储:2Φ字节
梯度:通常与参数保持同等精度#
- FP32存储:4Φ字节
- FP16/BF16存储:2Φ字节
优化器状态:#
- Adam优化器:为每个参数存储一阶矩和二阶矩-8Φ字节
- SGD优化器(或者只有一阶矩(动量)):4Φ
激活值:最复杂,变化最大的的部分,与批次大小,序列长度,模型结构(注意力头数,隐藏层大小)强相关。#
- 粗略估算(Transform为例):一个前向传播的激活值大概是2 * batch_size * seq_len * hidden_dim
不同优化手段对应的提升
PEFT#
Q什么是PEFT#
PEFT(Parameter Efficient Fine-Tuning,参数高效微调)是一种只更新少量参数(模型小部分或少量额外参数)微调大模型的高效微调方式。
Q为什么需要PEFT#
全参数微调成本太高,PEFT大量节省资源。
QPEFT优缺点#
- 优点:大幅减少资源占用;更新参数少,训练效率高;多任务灵活。
- 缺点:比全量微调性能略低;适用范围有限;依赖基础模型。
PEFT-LoRA及变种#
Q介绍一下LoRA#
LoRA(Low-Rank Adaptation,低秩矩阵适配)是一种PEFT方法,
核心思想是:只在部分权重上添加低秩矩阵,学习任务特定的变化,而保留原模型权重不动。
QLoRA的矩阵怎么初始化?为什么?#
A采用随机正态分布初始化,B初始化为零。
B初始化为零确保训练稳定:训练起点与原始模型一致。#
A随机初始化确保高效学习:每个LoRA神经元在训练初期可以接收到不同的梯度信号。#
QLoRA可以作用于哪个参数矩阵#
原论文可以作用于四个权重矩阵。
主流实践可作用于七个权重矩阵。如果没有用SwiGLU则没有。
QRank如何选取#
Rank(秩)的选取没有绝对标准,是一个需要权衡和实验的超参数。
核心原则是“从小开始,逐步增加”。
低Rank:参数少训练快,过拟合风险低,但模型容量和表达能力可能不足。#
高Rank:参数多容量大,可能逼近全量微调的性能,但成本高,过拟合风险增加。#
Qalpha参数如何选取#
alpha/r的比值用于控制BA对权重的影响幅度。
alpha通常设置为r的倍数,常见选择是alpha = 2r。关键不是alpha或r单独的值,而是它们的比值。一般通过网格搜索调整alpha/r(如1、2、4),找到使验证集性能最优的组合。
QLoRA高效微调如何避免过拟合#
减小r或增加数据集大小可以帮助减少过拟合。还可以尝试增加优化器的权重衰减率或 LoRA层的dropout值。
QLoRA权重是否可以合并,优缺点#
可以。
优点#
推理速度快:没有额外延迟。#
显存占用低:不需要存储额外的LoRA矩阵。#
缺点#
失去灵活性:合并后无法再单独调整LoRA参数或切换不同任务微调。#
不利于多任务管理:如果想用同一基础模型切换多个LoRA微调任务,必须保存多份合并权重。#
QLoRA微调有哪些超参数#
- r
- alpha
- AB矩阵初始化方式
Q简要介绍Q-LoRA#
Q-LoRA是一种基于LoRA的参数高效微调(PEFT)技术,通过引入4-bit NF4量化、双重量化和分页优化器,显著降低了大模型微调的显存需求。它将基础模型权重量化为4-bit NF4格式,在冻结的量化模型上训练低秩适配矩阵(LoRA),并通过双重量化压缩量化常数、利用分页优化器应对显存峰值,从而实现在有限资源下高效微调大模型。
QNF4量化核心原理是什么?如何实现NF4量化?#
NF4量化的核心原理是:利用神经网络权重的统计先验(近似正态分布),通过分位数量化的方法,为非均匀分布的权重分配非均匀的量化电平,使得有限的4比特空间能更精确地表示出现概率更高的数值区域(0附近),从而在极低的比特宽度下实现极高的精度保留率。
实现步骤:#
准备理论NF4值集: 基于标准正态分布的分位数预计算16个最优量化值,确保包含精确零值。#
分块归一化: 将权重张量分割为小块,每块独立计算缩放因子以隔离异常值影响。#
聚类量化: 将每块归一化后的值映射到最近的理论NF4值,记录4比特索引。#
压缩存储: 将每两个4比特索引打包为一个字节,与缩放因子一同存储。#
动态反量化: 推理时根据索引查表获取NF4值,乘以缩放因子恢复为浮点数进行计算。#
微调技术选择#
Q该选什么微调方法,全参数微调/Lora?#
资源紧张或数据较少用LoRA,数据量大、资源充足或需极致性能用全参数微调。
数据集#
QSFT(有监督微调)的数据集常见格式?#
Alpaca(指令)示例:


ShareGPT(多轮对话)示例:


Q数据集哪里找#
开源数据:Huggingface、ModelScope、GitHub等。
私有数据:根据不同业务场景,一般有企业内部文档,客户反馈数据,专有数据库等。
Q什么是温度超参数(Temperature)?它有什么作用?#
定义#
温度是一个用于调节语言模型输出概率分布的超参数,主要应用于softmax层之前,控制生成文本的随机性与确定性。
作用#
温度越高,输出的token不确定性越大,类比丹炉的温度越高,反应越剧烈,产物越随机。#
温度越低,输出的token不确定性越小,类比丹炉的温度越低,反应越缓慢,产物更加确定。#
KV Cache#
Q介绍一下KV Cache#
KV-Cache(Key-Value Cache)是Transformer模型推理阶段的优化机制。
核心思想
推理时,Transformer预测每个token都需要用到所有历史token的K和V,KV-Cache 将这些K和V缓存起来,生成时直接复用,不必重新计算。
QKV Cache优缺点#
优点#
不必重复计算注意力,推理更快。
缺点#
缓存占用随序列长度的增长而增大,会带来额外的显存开销。