大模型基础#
Q什么是大模型?它与传统深度学习模型的区别在哪里?#
大模型是指参数规模巨大(通常十亿到千亿级)、训练数据庞大、能力强大的深度神经网络。相比传统模型,它的参数量、训练数据量和跨任务泛化能力都显著更高。
Q什么是生成式大模型?#
生成式大模型(一般简称大模型LLMs)是指能用于创作新内容,例如文本、图片、音频以及视频的一类深度学习模型。相比普通深度学习模型,主要有两点不同:
模型参数量更大,都在Billion级别。
可通过条件或上下文引导,生成内容。
Q自回归大语言模型的训练目标是什么?#
根据已有词预测下一个词,训练目标为最大化最大似然函数:
等价于最小化损失函数
Q大模型(LLMs)的缺点?#
- 计算资源消耗巨大
- 数据需求量大
- 可能产生偏见或错误(幻觉)
- 推理延迟和部署难度
- 可解释性差
Q为什么Transformer架构适合用于大语言模型?#
Transformer的自注意力机制可以高效建模长距离依赖关系,支持并行训练,易于扩展规模,适合海量数据和参数的训练。
模型架构-LayerNorm#
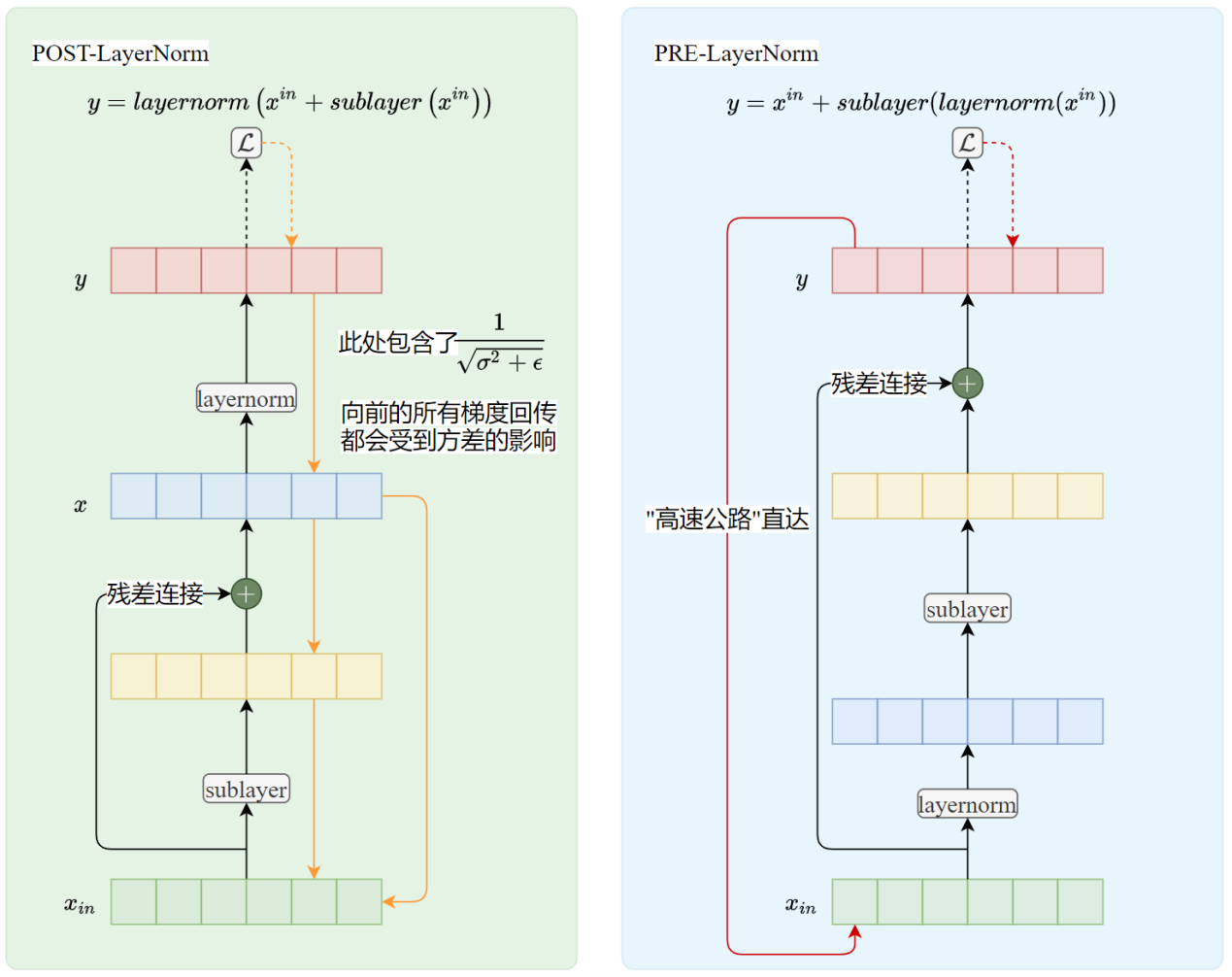
QPre-LayerNorm vs Post-LayerNorm#
在GPT-1和原版Transformer中使用的都是Post-LayerNorm,即后归一化。GPT-2转而使用Pre-LayerNorm,这是为了解决训练深层Transformer模型时的梯度不稳定和收敛困难问题。
Post-LN的问题#
在深层Transformer中(层数很多时),原始的Post-LN结构会导致梯度在反向传播时变得非常不稳定,尤其是在靠近输入侧的层。
Pre-LN的解决方案#
将归一化移至传入子层之前。
Pre-LN的效果#
梯度更稳定,信息流动更高效,使用 Pre-LN 的模型通常在相同训练步数下能达到比 Post-LN 模型更低的损失或更高的性能。
模型架构-激活函数相关#
Q补充:其他常用ReLU变体#
Leaky ReLU#
公式: (α为固定小常数,如0.01)
特点:负区间保留微小梯度,避免神经元失活。
GELU(高斯误差线性单元,Transformer核心)#
公式: , Φ(x)是标准正态分布的累积分布函数
近似式:
特点:融合随机正则,平滑非线性,0均值;bert/GPT等Transformer架构的标配激活函数。
Swish#
公式: (β为常数/可学习参数 ,β=1时为默认版也叫SwiGLU)
特点:处处平滑,性能优于ReLU;β→∞时近似ReLU,β=0时为0.5x。
Q为什么大模型的FFN层倾向于使用SwiGLU而不是ReLU?#
梯度与稳定性:ReLU的硬截断(负值为零)可能导致“神经元死亡”。而SwiGLU/GELU具有平滑非线性和非单调特性,能提供全域非零梯度,更利于深层网络训练。
稀疏性:ReLU是强制稀疏(负值直接归零),可能导致信息损失。SwiGLU通过门控(Sigmoid)实现动态稀疏,能保留部分负值信息,平衡表达与效率。
模型架构-位置编码#
Q常见位置编码#
正余弦位置编码#
原理:核心在于使用不同频率的正弦和余弦波组合,为序列中每个位置生成一个独一无二(确定性)、且蕴含相对位置关系的向量
公式:
- pos:词在序列中的位置(从0开始)
- i:位置编码向量的维度索引(从0到d_model/2 - 1)
- d_model:模型的嵌入维度
缺点:
长度外推能力实际表现不加(核心缺陷);(原因:处理未见过的位置时,点积注意力会变得不稳定,导致模型混乱)
相对位置建模“间接”且“低效”;
与模型参数割裂,是静态信息。
可学习的位置编码#
原理:将序列中每个位置都关联一个可训练的向量参数,并与词嵌入相加后一同送入模型学习。本质就是将位置信心换成可学习模型参数(矩阵),随机初始化,训练更新。
优点:就是灵活,自适应能从数据中学到最优的位置表达;
缺点:就是无法处理超长序列,缺乏相对位置的明确引导。
RoPE#
原理:不将位置信息作为静态的“附加物”加在词向量上,而是将其视为一种“旋转操作”,动态地对词向量本身进行变换。
公式:
RoPE将词嵌入的每个维度视为一对复数坐标。对于位置m的词向量,在维度 i上的变换为:
- :位置m处的词向量(或其对应的查询q、键k向量)。
- :预设的频率基数(一般是10000-500000),,控制不同维度的旋转速度。
这个旋转矩阵的作用是:将向量在二维平面上,旋转一个由位置m决定的.
效果:经过旋转后,同一个词在不同位置会有不同的向量表示,这编码了绝对位置。
模型架构-自注意力模块#
Q传统Attention存在哪些问题?#
计算时间长#
显存占用大#
QAttention优化方向#
改进多头机制:如MQA、GQA。#
控制注意力感受野:如稀疏注意力机制。#
QMHA、MQA和GQA/MLA#
传统的多头注意力机制#
Multi-Head Attention,简称MHA。
每个头有独立的Q、K、V。资源开销大。
多查询注意力机制#
Multi-Query Attention,简称MQA。
所有查询共用同一组K、V。
主要目的是为了优化推理阶段K、V占用内存过多的问题,但所有查询公用一组K、V会导致模型表达能力下降。
分组查询注意力机制#
Grouped-Query Attention,简称GQA。
介于MHA和MQA之间,将查询头分为g组,每组内的所有查询头共用一组K、V,在节约内存的同时,又一定程度上减轻了表达能力的削弱,是一种折中的方案。
MLA#
原理:MLA是基于GQA思想的一种具体的高效的实现。完全继承了GQA的分组共享思想,并增加了潜在的KV缓存,原理是将序列中所有位置的KV状态压缩融合成一组固定的潜在向量,无需随序列长度线性增长。
优点:在GQA的基础上彻底解决了长序列的KV缓存内存瓶颈。
QLLMs采用的注意力机制变体#
模型架构-稠密模型和MOE模型#
Q稠密模型#
在稠密模型中,每个输入样本都会激活(用到)模型的所有参数。
Q混合专家模型#
在前馈网络部分引入多个专家和一个门控网络。对于每一个token,动态选择一小部分最相关的“专家”来处理该输入,而其他专家保持非活跃状态。这是一种稀疏激活的机制。
训练-学习率调度策略#
Q为什么在大模型训练中需要预热(Warmup)#
一开始模型参数是随机初始化的,如果直接使用一个较大学习率,参数更新会过大,容易出现梯度爆炸或者训练崩溃。
Q学习率退火(Annealing)对模型收敛和泛化的作用是什么#
在训练的中后期,当模型的损失逐渐接近某个极小值区域时,如果学习率还很大,参数会在最优点附近来回震荡,甚至跳出去,导致无法真正收敛。
退火通过逐步降低学习率,让参数更新的步伐越来越小。
QWarmup和Annealing通常如何配合使用#
Warmup和Annealing一般是配套使用的,训练过程可以分为三个阶段:“先预热 → 中间稳定 → 后期退火”
预热阶段#
刚开始训练,学习率从0逐步升到峰值,确保训练能平稳启动。
稳定阶段#
维持在峰值学习率一段时间,让模型快速学习到主要的特征和模式。
退火阶段#
随着训练进入中后期,逐步降低学习率,让参数在接近最优解时收敛得更细致,提升最终性能和泛化能力。
训练-SFT#
Q什么是监督微调?它与预训练有什么区别?#
训练数据#
预训练数据:海量、无标注,SFT数据:少量、高质量、有标注。
损失函数#
预训练阶段计算所有token的损失,SFT不计算Prompt部分的损失
训练目标#
预训练:获得通用语言理解和生成能力,SFT:获得特定任务执行能力、指令遵循能力和对话能力。
训练-RLHF#
Q请详细描述Instruct-GPT RLHF的整体流程及各阶段作用#
监督微调(SFT)阶段#
使用高质量指令-响应对对预训练模型进行微调
目标:获得基础对话能力。
奖励模型(Reward Model, RM)训练阶段#
基于上一步的模型替换最终线性层(输出标量分数),使用人类偏好数据训练RM。
强化学习优化阶段#
基于可训练的SFT模型和参数冻结的SFT模型。
目标是最大化RM打分的同时,尽可能接近冻结SFT的分布
Q什么是DPO#
直接偏好优化(Direct Preference Optimization,DPO)是Rafael Rafailov等人在《Direct Preference Optimization:Your Language Model is Secretly a Reward Model》中提出的一种非传统强化学习算法。
不同于传统的RLHF方法,DPO无需奖励模型,其训练数据包含成对的“好回答”和“差回答”,训练目标是在确保模型稳定的前提下,拉开“好回答”和“差回答”之间的差距。
DPO的损失函数如下
训练-蒸馏#
Q什么是知识蒸馏(Knowledge Distillation),核心思想是什么#
知识蒸馏是一种通过将大模型(教师模型)的知识迁移到小模型(学生模型)的方法,让小模型在保持轻量化的同时接近大模型性能。
Q什么是强-弱蒸馏(Teacher-Student Distillation)#
强-弱蒸馏是知识蒸馏的一种,核心思想完全相同。
QQwen3强弱蒸馏的流程#
蒸馏分为两个阶段:
离策略蒸馏#
将教师模型通过思考和非思考两种模式生成的输出结果与查询进行整合,对学生模型进行监督微调。损失函数分为学生模型预测思维链(如果有的话)+教师模型响应的交叉熵损失。
同策略蒸馏#
学生模型和教师对于相同的查询生成概率分布,这一阶段的损失函数是学生模型和教师模型的KL散度。
大模型结构演进#
主线:从循环序列模型 → 奠基性的Transformer → 任务特化的编码器/解码器 → 走向统一的自回归解码器,并通过稀疏化、新架构和多模态融合持续突破效率与能力边界。
Q前Transformer时代:序列瓶颈#
- 核心:RNN/LSTM/GRU循环处理,顺序计算。
- 问题:无法并行,难以学习长程依赖,严重限制了模型规模和能力。
Q2. 革命基石:Transformer (2017)#
- 核心创新:自注意力机制 + 完全并行化。
- 意义:一举解决并行与长程依赖问题,成为所有现代大模型的基础组件。
Q3. 分道扬镳:两大预训练范式 (2018)#
- BERT (编码器):双向理解。擅长文本理解类任务(如分类、问答)。
- GPT (解码器):自回归生成。擅长文本生成,并逐步展现出通过提示学习的潜力。
Q4. 王者之路:规模化与Decode-only统一 (2020-)#
- 核心事件:GPT-3 出现。(卷参数量)
- 关键结论:将解码器模型规模扩大至极高水平(千亿参数),配合海量数据,能涌现出强大的通用能力和上下文学习。
- 结果:纯解码器架构因其强大的生成通用性,成为大语言模型的绝对主流。
- 核心优化:旋转位置编码(ROPE),SwiGLU,预归一化。
Q5. 当下趋势:效率与能力突破#
- 混合专家(MOE):在总参数量巨大的同时,只激活部分参数进行计算,实现更经济的超大规模模型(如Mixtral)。
- 超越Transformer:为克服Transformer处理长文本的计算瓶颈,出现更高效的架构(如Mamba),追求线性复杂度和更优的推理性能。
- 多模态统一:将图像、音频等信号转换为类似文本的“词元”,输入给单一Transformer模型处理,迈向通用多模态AI(如GPT-4V)。