项目周期#
- 1人团队,总计约2.5个月。
- 需求分析与技术选型1周
- 数据准备与预处理2周
- 模型开发与训练4周
- 系统集成与后端对接2周
- 部署上线1周
功能介绍#
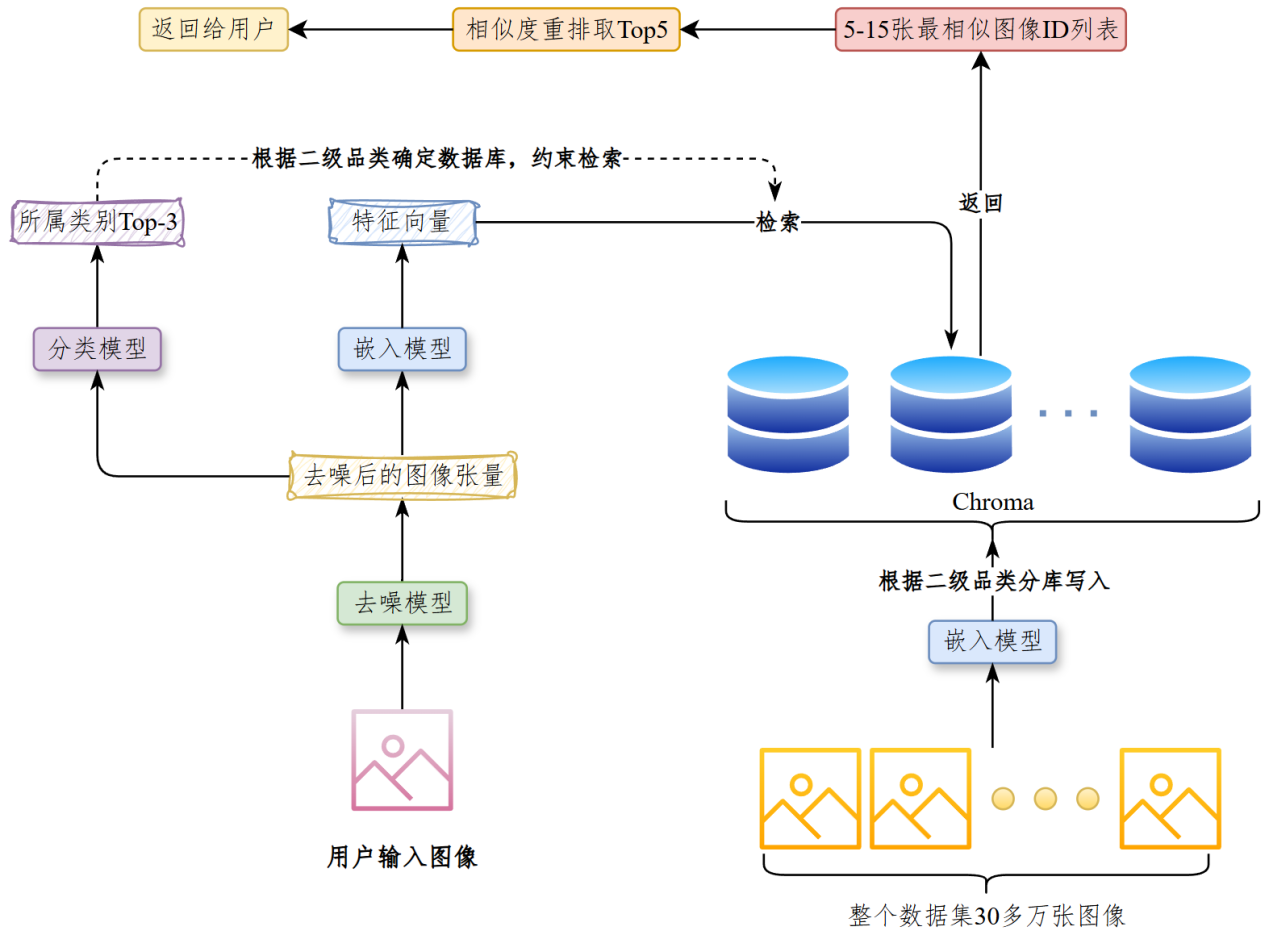
根据用户输入的图片搜索相似的商品。
实现流程#
对图片去噪->提取图片的特征表示->使用特征进行相似度检索
(为保证结果的准确性,又根据图片预测所属品类,用品类在相似度检索前约束其结果)
技术细节#
Q去噪#
使用CNN自编码器-1(展开模型架构,训练过程(数据量、集群算力、训练时长、超参数、模型内部参数、数据预处理))
输入带噪点图片,使用自编码器处理,输出完整图片。
Q提取待检索图片的特征表示#
使用CNN自编码器-2(展开模型架构,训练过程(数据量、集群算力、训练时长、超参数、模型内部参数、数据预处理))。
存储图片计算后的向量(使用向量数据库(底层检索算法(可选))),存储模型权重。
Q计算用户输入的图片的特征表示#
使用CNN自编码器-2-编码器(展开模型架构,训练过程(数据量、集群算力、训练时长、超参数、模型内部参数、数据预处理))。
Q相似度检索#
向量数据库提供的检索算法。
根据向量数据库记录的唯一索引定位相似图片。
Q分类#
基于CNN,添加线性层,并进行分类(为什么不用前面训好的自编码器?内部结构和层数不一样,出于资源考虑。单独做了下实验,发现单独重新训练效果更好)。
训练过程(数据量、集群算力、训练时长、超参数、模型内部参数、数据预处理)。
Q配合发布接口#
需要提供代码调用文档,配合后端同事发布接口。
总结#
智图寻宝项目的功能是:根据用户输入的图片检索相似商品。
实现流程主要包含三个步骤:图片去噪->分类->相似度检索
首先,我们基于CNN构建了自编码器用于去噪。自编码器由编码器和解码器构成。#
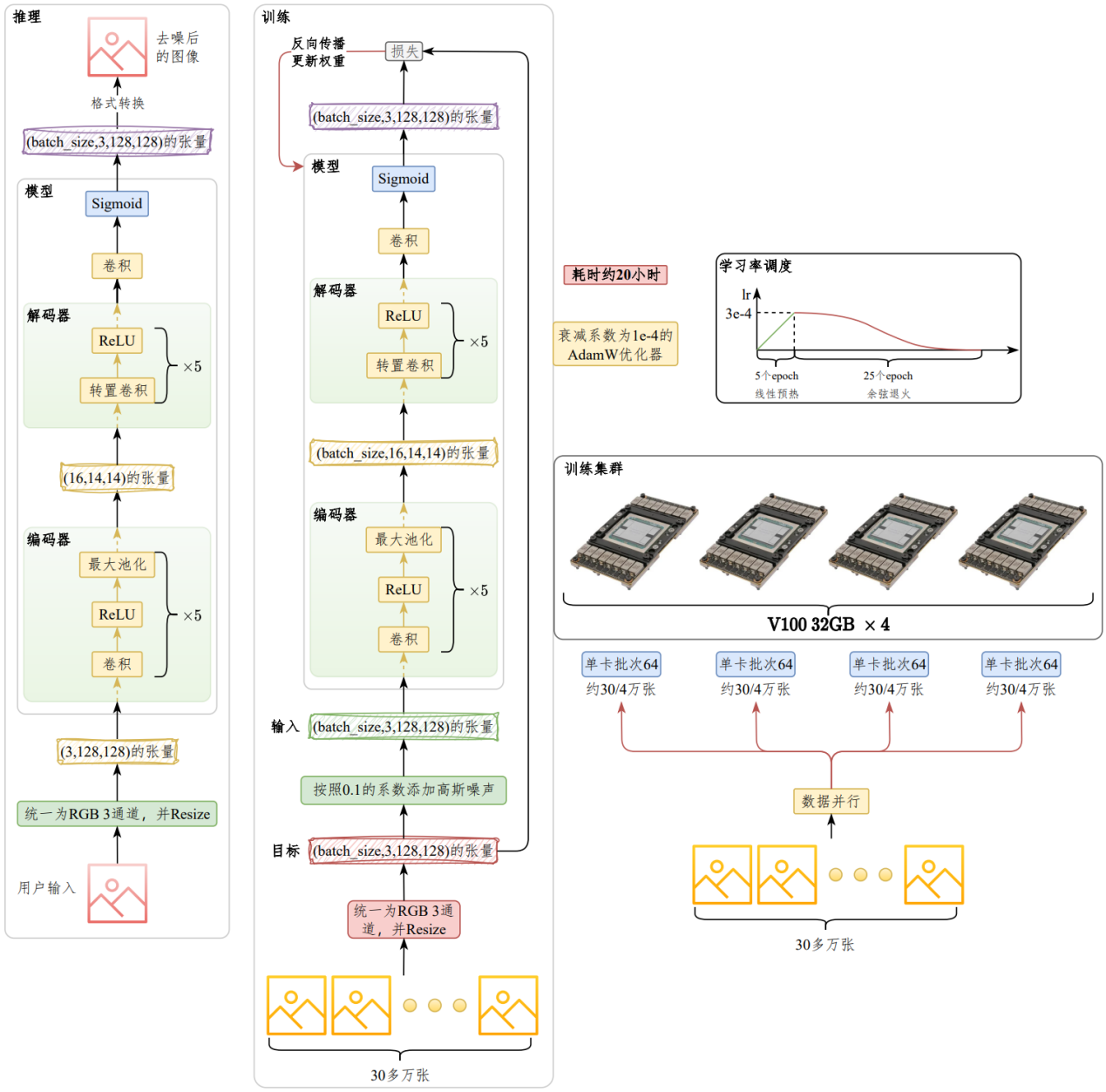
训练之前,我们首先对图像进行预处理,统一为RGB 3通道格式,统一尺寸为128*128,并转换为Pytorch张量,每个像素值由0~255之间的整数映射为0~1之间的浮点数。按照0.1的噪声系数(系数乘以噪声)向原图像添加高斯噪声,将其作为输入,原始图像作为输出。#
编码器采用5个卷积层,每个卷积层之后通过ReLU激活函数引入非线性,使得网络可以学习复杂的函数映射。此外,每个卷积层之后紧跟一个最大池化层,通过5组卷积+池化层对图像信息进行压缩,将输入图像由3通道转换为16通道。并将图像尺寸由128*128压缩为16*16。#
解码器首先由5个转置卷积层堆叠而成,每个转置卷积层之后同样应用ReLU激活函数,最后经过一个普通卷积层,并应用Sigmoid激活函数得到最终输出,确保像素值在0~1之间。输出尺寸和编码器输入完全一致,都是3通道,尺寸128*128。#
将添加了高斯噪声的图像作为输入,原始图像作为目标进行训练。单卡训练批次大小为64,在30多万多张图片上训练30个轮次,采用衰减系数为1e-4的AdamW优化器,首先在5个轮次上将学习率从0线性预热至3e-4,然后通过余弦退火在后续25个epoch上衰减至0。#
训练在【4张V100 32GB】上进行,采用DDP策略,耗时【约20小时】#
推理时,输入用户提供的图片,输出去噪后的图片。#
然后,我们基于输入图片识别其品类。#
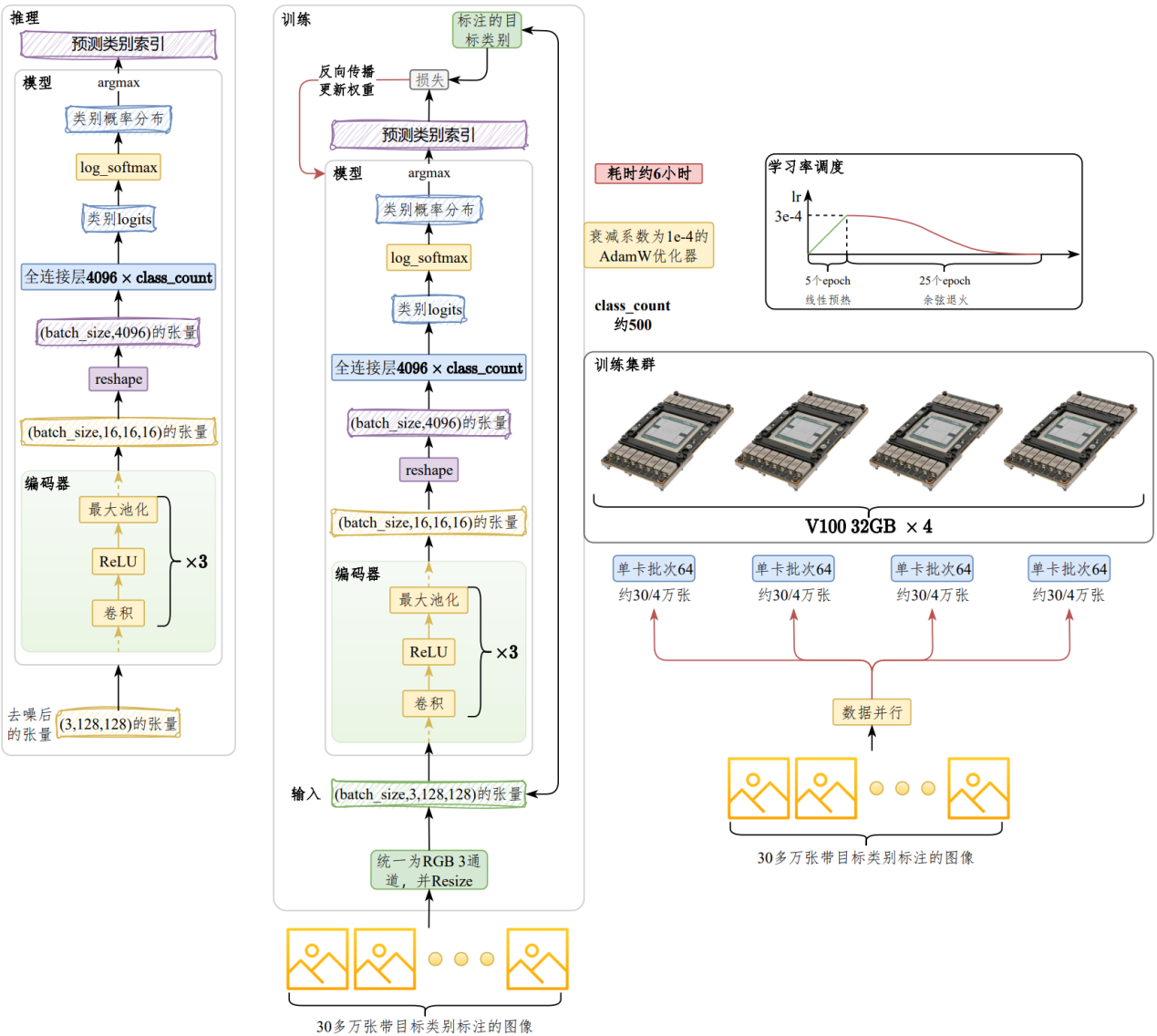
我们通过公司业务库获取了30多万多张图像的商品类别标注数据,类别为三级品类,总数在500左右(在所选公司APP上数一下品类)。#
训练之前同样先进行预处理,将图像统一为RGB 3通道格式,尺寸为128*128,转换为Tensor。将原始图像作为输入,商品类别作为输出,构建训练集和验证集。#
我们先进行了相似度检索任务编码器的训练,它已经可以输出图像的高维表征,尝试在此基础上添加线性层用于类别预测,训练过程中冻结除最终线性层外的其它层,但效果不尽人意。所以重新构建了独立的CNN深度神经网络,性能略优于前者,但由于网络架构更简单,推理成本更低,响应更快,确定为最终方案。#
模型包含3组 “卷积层+ReLU激活函数+最大池化层”。将通道数由3转换为16,图像尺寸由128*128转换为16*16,然后通过reshape将数据展平为4096维的向量,最后通过一个全连接层将向量映射为【类别数】维向量,最终应用softmax计算类别概率,预测所属类别。#
将原始图像作为输入,类别标签作为目标进行训练。单卡训练批次大小为64,在30多万张图片上训练30个轮次,采用衰减系数为1e-4的AdamW优化器,首先在5个轮次上将学习率从0线性预热至3e-4,然后通过余弦退火在后续25个epoch上衰减至0。#
训练在【4张V100 32GB】上进行,采用DDP策略,耗时【约6小时】#
推理时,将经过去噪的图像作为输入,根据输出的类别标签,通过类别字典获取商品所属的三级品类。#
最后,我们基于CNN构建了另外的自编码器用于生成图像的特征表示。#
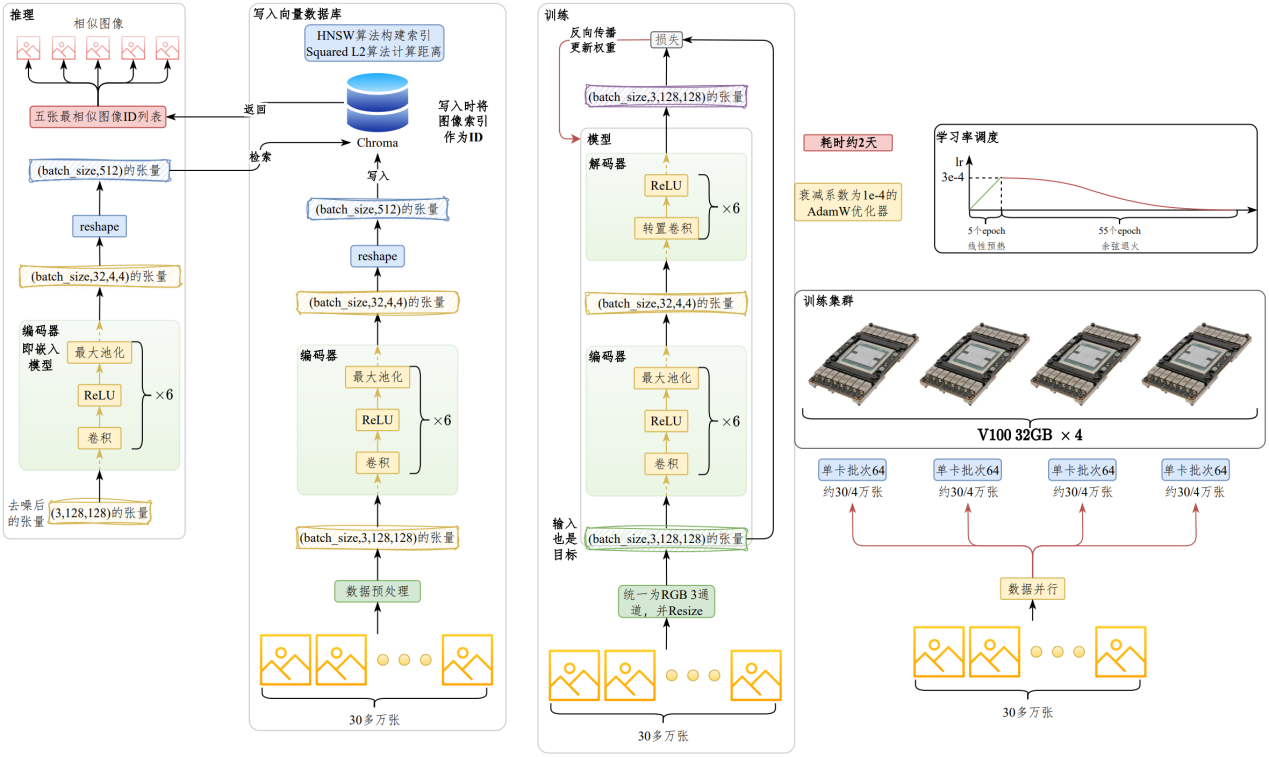
训练之前同样先进行预处理,统一为RGB 3通道格式,尺寸为128*128,转换为Tensor。将原始图像作为输入和输出构建训练集和验证集。#
编码器由6组 “卷积层+ReLU激活函数+最大池化层” 堆叠而成。将通道数由3转换为32,图像尺寸由128*128转换为4*4。#
解码器由6组 “转置卷积层+ReLU激活函数” 堆叠而成,将编码器生成的特征表示重建为原图像尺寸。#
将原图像作为输入和目标进行训练,单卡批次大小为64,在30多万多张图片上训练了60个轮次,采用衰减系数为1e-4的AdamW优化器,首先在5个轮次上将学习率从0线性预热至3e-4,然后通过余弦退火在后续55个epoch上衰减至0。#
训练在【4张V100 32GB】上进行,采用DDP策略,耗时【约2天】
训练过程中保存验证集上损失最小的编码器文件,训练完成后基于最佳模型将整个数据集的图像数据映射为(32,4,4)形状的张量,然后通过reshape函数将数据转换为512维的向量,存入Chroma。数据集中的每张图像都有唯一索引,写入Chroma时,我们将唯一索引作为图像的ID。采用Chroma提供的HNSW算法构建索引,以及默认的平方L2算法计算相似度。#
为了提升检索效率,我们根据商品所属的二级品类分库,即二级品类相同的商品图像的特征表示写入同一个向量数据库,最终构建了70多个向量数据库。
推理时,将去噪后的图像输入编码器,再通过reshape得到512维的特征向量,然后在Chroma中根据检索5条相似度最高的数据,返回其ID,根据ID确定相似图像后返回给调用者。#
在相似度检索之前,我们首先预测商品所属类别Top-3,根据二级品类确定向量数据库,然后分别在这些向量数据库中检索Top-5的相似商品,最终将所有的相似商品根据相似度重排,取Top-5作为最终结果。
配置和训练时长对应关系参考#
模型训练时的集群配置及耗时对应关系如上所示,如果要更换集群规模,根据算力等比例调整训练时长即可。
总结-项目串讲#
智图寻宝项目的目标是根据用户输入的图像检索相似商品。
实现流程主要包含三个步骤:图片去噪->分类->相似度检索
Q去噪#
串讲#
图片去噪模块基于去噪自编码器实现。自编码器是一种无监督学习的神经网络模型,由编码器和解码器构成,核心思想是通过编码器将输入图像映射到低维特征空间,然后再通过解码器从低维表示重新构建出尽可能接近原始输入的数据。去噪自编码器是自编码器的变种,其原理是给输入图像添加噪声,训练模型从被污染的数据中重建原始图像。
我们基于去噪自编码器在30多万张电商图像上进行去噪模型的训练。
编码器部分由5个卷积+池化层的组合构成,解码器部分由五个转置卷积层加一个普通卷积层构成。
训练之前首先经过图像预处理统一尺寸,转换为张量,再添加随机噪声作为输入,未添加噪声的张量作为目标。
训练采用了AdamW优化器,并使用了线性预热和余弦退火的学习率调度策略。
训练在4张V100 32GB构成的集群上进行,采用数据并行策略。
推理时接收用户输入的图片,输出去噪后的图像。
重要参数#
Q分类#
串讲#
分类基于卷积和线性层的组合实现,在30多万张标注了类别的电商图片上进行训练。
模型由3组卷积+池化层加一个全连接层组成。
训练之前首先将输入图像处理RGB 3通道格式,尺寸为128*128,然后转换为张量作为输入。标注的类别作为目标。
训练采用了AdamW优化器,并使用了线性预热和余弦退火的学习率调度策略。
训练在4张V100 32GB构成的集群上进行,采用数据并行策略。
推理时,将去噪后的图像输入模型,经过全连接层得到商品所属类别的概率分布,取概率最大的三个品类用于约束相似度检索的结果。
重要参数#
Q相似度检索#
串讲#
相似度检索基于原始自编码器实现,在30多万张电商图片上进行训练。
编码器部分由6个卷积+池化层堆叠而成,解码器部分由6个转置卷积堆叠而成。
训练之前首先将输入图像处理RGB 3通道格式,尺寸为128*128,然后转换为张量,作为输入和目标。
训练采用了AdamW优化器,并使用了线性预热和余弦退火的学习率调度策略。
训练在4张V100 32GB构成的集群上进行,采用数据并行策略。
训练完成后将数据集中的所有图像通过编码器+reshape转换为512维向量,按照商品所属的二级品类存入Chroma。采用了后者默认的HNSW算法构建索引,用平方L2算法计算向量距离。写入Chroma时将每张图像的索引作为ID。
推理时,将去噪后的图像输入编码器,得到512维的特征向量。然后根据类别判定Top3确定二级品类,进而确定向量数据库,在选定的所有库中根据相似度检索获取相似图像Top5,最后将所有库返回的图像根据相似度重排,取Top5返还给调用者。