Function Call相关#
Q为什么需要函数调用?#
LLM的能力是有边界的:如无法操作数据库、无法使用搜索引擎,在实际开发中,我们又需要大模型具备边界之外的能力,因此引入了函数调用(Function Call)机制。
Q函数调用的定义和流程#
定义#
函数调用(Function Call)是大语言模型的一种能力:模型不仅返回文本,还能按照约定的格式返回需要调用的外部函数/工具的名称和参数信息。
流程#
将用户请求转化为结构化的函数名和参数,由程序执行具体逻辑,再把结果返回给用户。
用户输入请求并提供可用函数说明。#
模型判断是直接回复文本还是输出特定格式的函数调用请求。#
程序接收调用请求,执行对应函数并将返回结果发送给模型。#
模型结合函数执行结果,生成最终答复或继续调用工具。#
Q函数调用的目的#
让模型与外部世界交互,调用工具来获取其自身无法直接获取的信息或执行特定操作,从而增强模型的能力,突破模型本身知识和能力的限制,完成更复杂、更准确的任务。
Agent相关#
Q什么是大模型Agent#
大模型Agent(智能体)是一个将大语言模型(LLM)作为“大脑”的自主系统。它能够通过自然语言理解任务,进行复杂推理、制定计划并结合记忆功能、利用工具来执行任务,并能多次迭代,最终实现用户设定的目标。
Q结合Langchain说明大模型Agent由哪些部分组成#
计划(Planning)#
计划模块是Agent的“大脑”,具备思维链、自我反思能力,负责任务分解、策略制定和决策推理。在LangChain中,计划能力主要通过Prompt Engineering + LLM推理和反思机制(Reflection)实现
记忆(Memory)#
包括短期和长期记忆,用于存储上下文和历史信息。
- 短期记忆:主要依赖于对话缓冲区(Conversation Buffer)+窗口缓冲区(Conversation Buffer Window)
- 长期记忆:向量存储(Vector Stores)+摘要记忆(Conversation Summary Memory)+混合记忆(Combined Memory)
工具(Tools)#
智能体可以调用的外部API、函数或服务。
Langchain提供了一系列内置工具,常见的有#
- DuckDuckGoSearchRun:网络搜索工具。
- RequestsToolKit:HTTP请求工具集。
并支持用户通过@tool装饰器或StructuredTool的from_function()注册自定义工具。#
行动(Action)#
执行模型决策,输出指令或与环境交互。
LangChain的Agen会解析LLM输出中的action和action_input,自动调用对应工具。
工具执行后返回observation,再送回LLM决策下一步,形成“Thought → Action → Observation”循环。
QLangchain Agent类型#
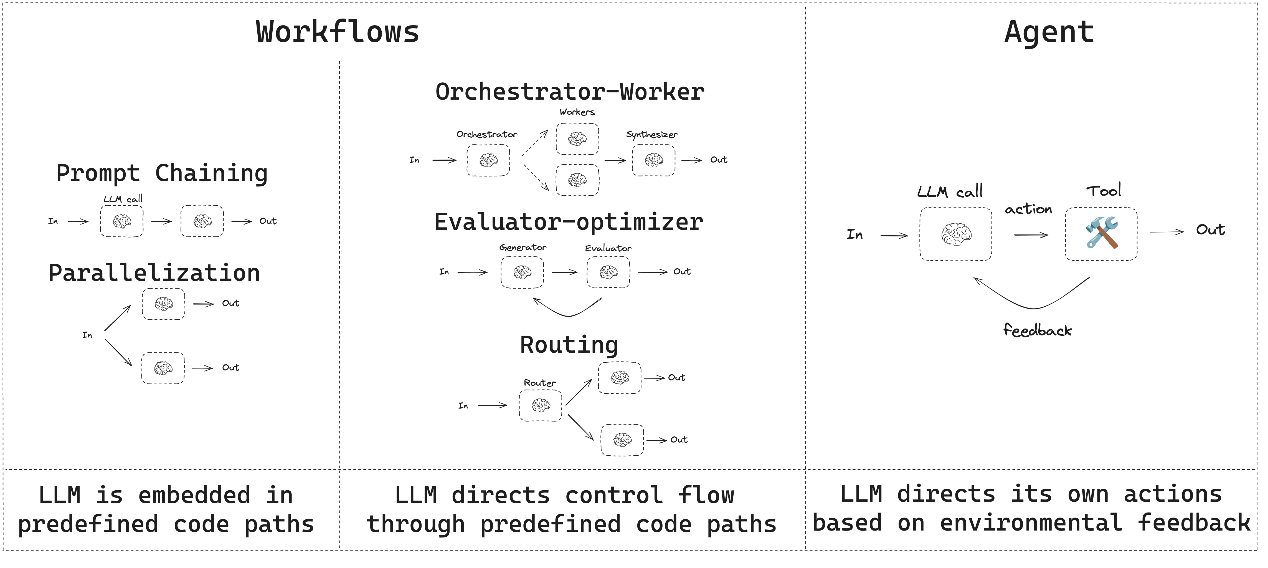
两种工具调用方式:#
Function Call Agent:这类Agent基于结构化函数调用直接生成工具调用参数,效率更高,适合工具明确的场景。
ReAct Agent:基于文本推理的链式思考(Reasoning + Acting),具备反思和自我纠错能力。取第一个单词的前两个字母和第二个单词的前三个字母,合称ReAct。
推理(Reasoning):分析当前状态,决定下一步行动。#
行动(Acting):调用工具并返回结果。#
通过自然语言描述决策过程,适合需要明确推理步骤的场景。
Zero-shot ReAct Agent(上图最右边那类:大模型基于环境反馈自己决策)#
特点:
- 不需要示例,直接根据工具描述推理并执行动作。
- 使用ReAct框架。
- 每次调用LLM决定下一步使用哪个推理工具。
适用场景:通用任务,如问答、调用工具、多步推理等。
Conversational Agent(中间那类:大模型根据预定义的代码路径控制流程)#
特点:
- 专为对话场景设计,能记住历史消息。
- 可结合工具使用,适合聊天机器人、客服助手。
适用场景:需要连续对话且可能调用工具的场景。
Self-ask with Search Agent(图中Evaluator-optimizer 或 Router)#
特点:
- 自动提出中间问题并调用搜索工具。
- 适合需要多步检索的任务。
适用场景:复杂事实查询、多源信息检索。
Plan-and-execute Agent(图中Prompt Chaining + Routing)#
特点:
- 先规划整个任务步骤,再逐步执行。
- 适合复杂、多步、可分解的任务。
适用场景:项目拆解、多工具协作任务。
Langchain Agent核心其实就是一个循环:
输入 → LLM 选择工具 → 执行工具 → 观察结果 → 判断是否继续 → 输出
Q什么是AgentExecutor#
AgentExecutor是执行Agent的调度器,是其运行控制器。
它负责接收输入、驱动Agent进行推理决策、调用相应工具、处理观测结果,并管理整个执行流程。
在 LangChain 中,Agent 无法直接运行,必须通过 AgentExecutor 来驱动和执行。
Q大模型Agent实现思路#
设置秘钥→初始化LLM→初始化工具并封装为工具实例(可以省略)→创建Agent和AgentExecutor→执行查询
Q如何给LLM注入领域知识#
Langchain的记忆模块:从相关记忆对象中获取领域知识(短期记忆)#
RAG:从包含领域知识的向量数据库中检索相关信息(长期记忆)。#
领域知识微调LLM(永久记忆)。#
Agent记忆管理#
Q记忆的本质是什么?#
记忆的本质不是数据存储,而是上下文维护;核心问题是如何在有限的token窗口内保持对话的连贯性,所以有记忆的分级策略:长短期记忆的平衡。
QLangChain中有哪些记忆类型?#
ConversationBufferMemory#
- 优点:简单直接,保留完整历史
- 缺点:token消耗快,成本高
- 适用:短对话、调试场景
ConversationBufferWindowMemory(滑动窗口)#
如何确定合适的窗口大小?#
- 分析对话结构:任务型对话k小(3-5),开放式对话k大(8-10)
- 平衡token成本:k值 = (总token限额 - 当前prompt) / 每轮平均token
- 实际测试调整:从k=3开始,根据任务完成率逐步优化
处理长对话的取舍策略?#
关键保留,次要丢弃:优先保留用户指令、系统响应、实体信息,过滤寒暄和确认语句。
ConversationSummaryMemory(摘要记忆)#
摘要生成的质量如何控制?#
- 结构优化:按[事实|意图|决策]分段摘要,避免信息混合
- 关键保留:强制保留数字、日期、命名实体
- 定期完整化:每5轮保存一次完整对话快照
信息丢失问题如何解决?#
可以采用分级存储策略:
- 核心信息:直接存储(如用户需求)
- 次要信息:摘要存储
- 背景信息:向量化存储(需时可检索)
Token效率和信息完整性权衡?#
- 80/20原则:用20%的token存储80%的关键信息。
- 动态调整:重要对话(如需求确认)保存全文,日常对话保存摘要。
ConversationKnowledgeGraphMemory(知识图谱)#
如何构建和维护对话中的实体关系?#
三层构建:
- 抽取层:NER提取实体,关系分类器提取关系
- 融合层:新实体与图谱合并(相同实体合并,冲突实体版本管理)
- 修剪层:定期清理低频实体和过时关系
在复杂对话优势如何体现(同样是GraphRAG的优势)?#
- 多跳推理:能回答"上次提到的A公司的产品价格是多少?"
- 矛盾检测:能发现"之前说喜欢咖啡,现在说从不喝咖啡"的矛盾
- 个性化:构建用户偏好图谱,实现精准推荐
Q超长对话处理#
三级缓存架构:
L0(热数据):最近3轮完整对话(BufferWindowMemory)#
L1(温数据):前10轮关键摘要(SummaryMemory)#
L2(冷数据):全会话向量索引(VectorStoreRetrieverMemory)#
动态降级机制:对话超过20轮,自动启动摘要压缩。
QToken优化策略#
三阶段压缩:
实时压缩:去除重复、停用词#
摘要压缩:每5轮生成一次增量摘要#
语义压缩:向量化表示,仅存储嵌入#
选择性召回:仅提取与当前query相关的历史片段
Q上下文一致性#
实体图谱+状态机: