项目周期#
- 总计近2个月:
- 基础架构与环境配置:1周
- 元数据知识库构建:3周
- 问数智能体搭建:2周
- 测试、优化与文档:2周
技术栈#
- 后端框架:FastAPI
- 数据库:MySQL(业务数据)
- 向量存储:Qdrant
- 全文检索:Elasticsearch
- Agent框架:LangGraph(状态图编排)
功能介绍#
掌柜问数是一个基于自然语言处理与数据分析技术的智能数据服务系统,面向数据仓库应用场景,旨在帮助用户通过对话方式高效获取数据仓库中的数据洞察。用户无需掌握复杂的查询语法,即可用自然语言提出问题,系统自动完成对数据仓库数据的理解、计算分析与结果可视化,大幅提升数据使用效率,降低数据分析门槛,助力业务决策智能化。

项目架构#
Q概述#
本项目以数据仓库的元数据为核心,使用 MySQL 存储结构化元数据信息,结合 Qdrant 构建语义向量索引、Elasticsearch 构建全文索引,形成统一的元数据知识库。查询过程中,系统首先根据用户自然语言问题进行多路召回,筛选相关表、字段及指标定义,再将元数据信息与用户问题共同输入大模型生成 SQL,最终完成自动查询与结果返回,确保生成结果的准确性与可控性。
完整的项目架构如下图所示:
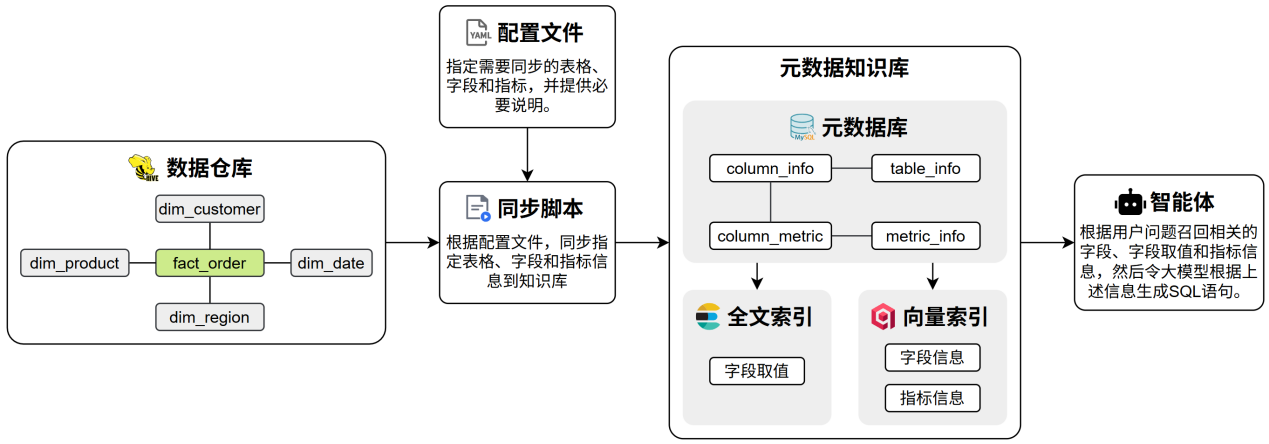
Q元数据知识库#
元数据知识库作为数据仓库的语义基础设施,用于集中管理和高效检索表结构、字段定义、字段取值示例及复杂指标说明等元数据信息,支撑后续的SQL 生成。
完整的元数据统一存储于 MySQL 数据库中,并对其中部分关键信息构建向量索引和全文索引,以提升语义召回与关键词召回的效果。
元数据库#
元数据库共有如下四张表,用于存储完整的元数据信息,包括数据仓库的表格信息、字段信息和指标信息。

各表具体内容示例如下:
向量索引#
向量索引主要用于对column_info(字段信息)和metric_info(指标信息)进行语义召回。
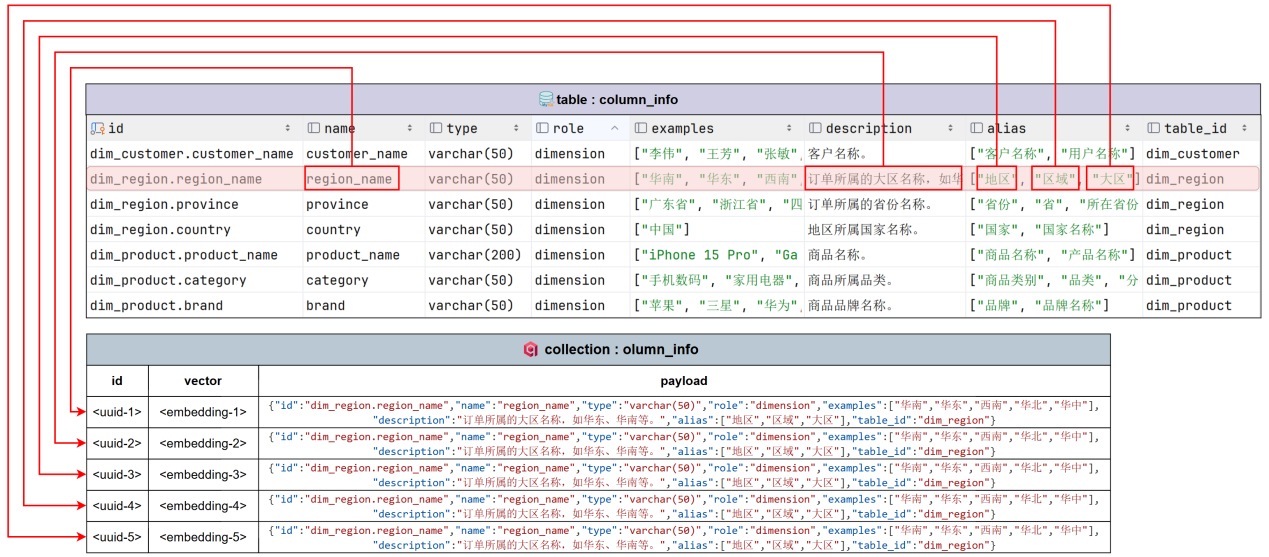
- column_info
column_info中,需要建立向量索引的字段如下图所示:

具体示例如下图所示:
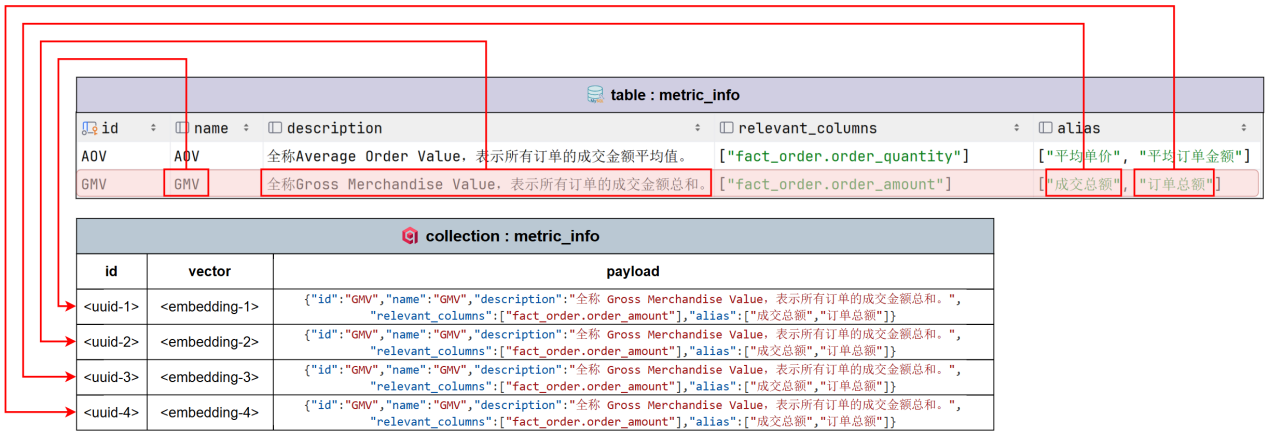
- metric_info
metric_info中,需要建立向量索引的字段如下图所示:

具体示例如下图所示:
全文索引#
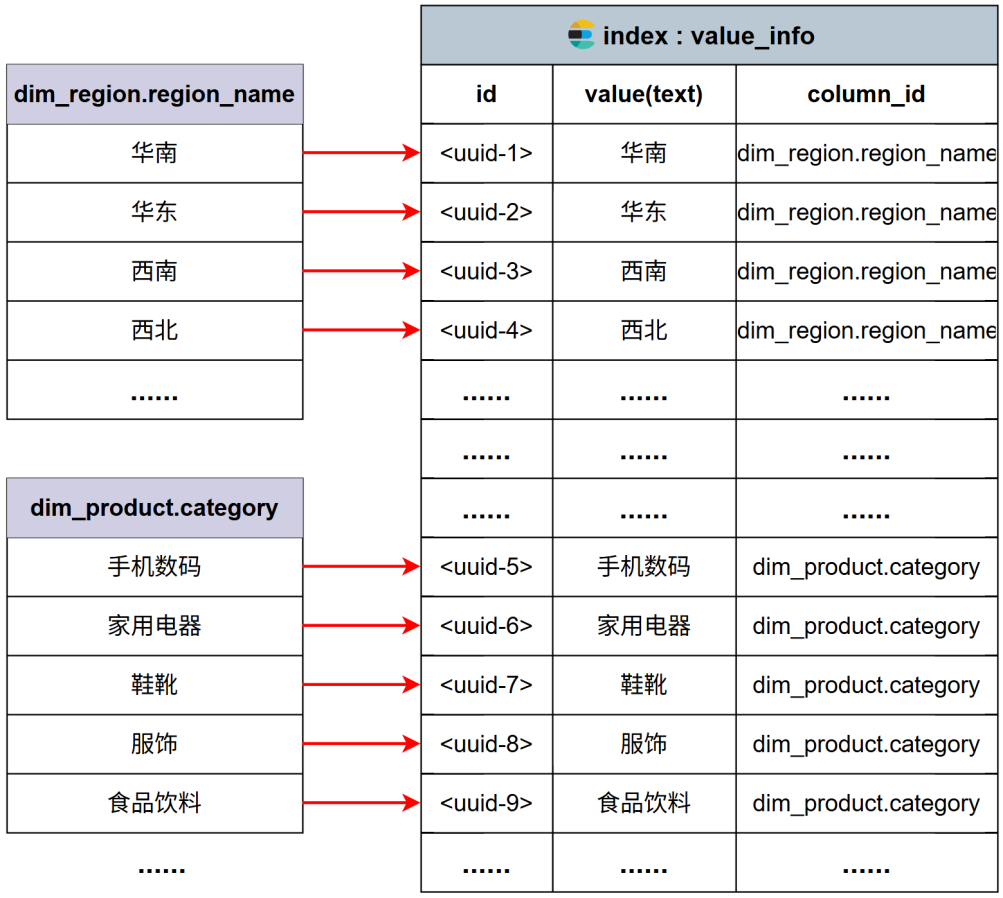
全文索引主要用于对字段取值进行检索与匹配,建立全文索引的主要是数据仓库中的各种维度表中的维度字段,具体字段如下图所示:
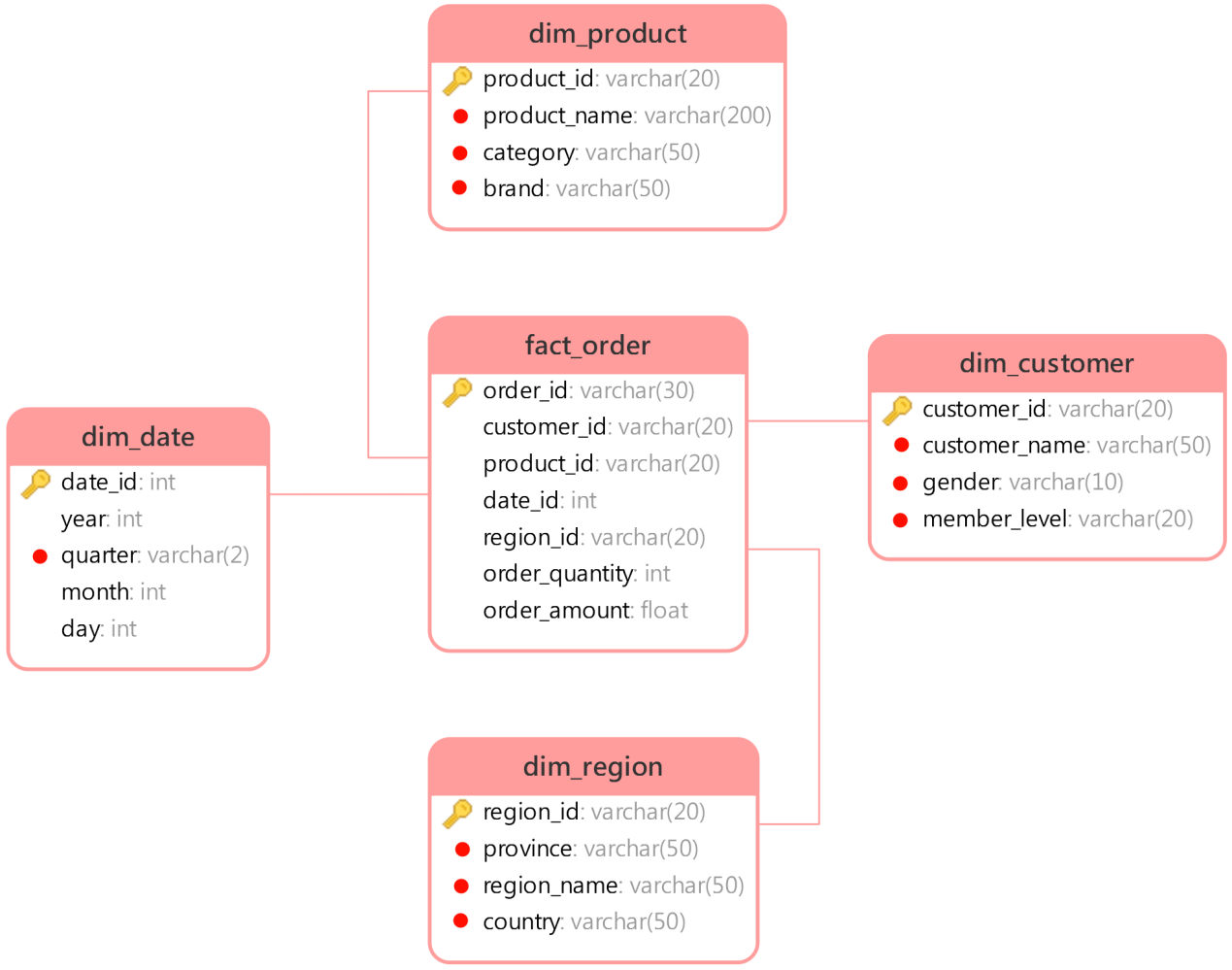
具体示例如下图所示:
Q问数智能体#
问数智能体主要基于Langgraph进行开发,具体结构如下图所示:
项目串讲#
这个问数智能体项目,本质上其实就是 NL2SQL。
也就是把用户用自然语言提的问题,交给大模型自动生成 SQL 查询语句。
要让模型把 SQL 写对,必须提前告诉它两类非常关键的信息:
数据仓库里有哪些表、字段
一些复杂的业务指标到底是怎么计算的
否则模型根本不知道该查哪张表、用哪些字段、指标怎么算。
但问题是:
数据仓库里的表和指标非常多,不可能一股脑全部丢给模型。
给太多信息,模型反而会被干扰,SQL 更容易写错。
所以这个项目真正的难点其实是:
如何从海量的表信息和指标信息中,精准筛选出“对当前问题最有帮助”的那一小部分,再交给大模型。
这里我们借鉴了 RAG 的思想,为整个数据仓库专门设计了一套 元数据知识库。
这个知识库里,存的不是业务数据,而是:表信息、字段信息和指标信息
为了方便检索,我们同时给它建立了:
向量索引(做语义召回)
全文索引(做文本召回)
在查询的时候,系统会先根据用户的自然语言问题做多路召回,筛选出相关的表、字段和指标定义,然后把这些元数据信息和用户问题一起交给大模型生成 SQL。这样就能保证模型是在“充分理解数据仓库结构”的前提下写 SQL,准确率会高很多。
下面我重点讲一下这个元数据知识库是怎么设计的。
完整的元数据是存储在 MySQL 里的,主要分三块:表信息、字段信息、指标信息。
表信息包括:
表名
表的角色(事实表还是维度表)
表的业务描述
字段信息包括:
字段名
字段别名
字段类型
字段角色(维度、度量、主键、外键)
字段的业务描述
以及一些字段取值示例
指标信息包括:
指标名
指标别名
指标的业务描述
以及这个指标依赖哪些字段
接着,我们对字段信息和指标信息都建立了向量索引,索引的内容主要是名称、别名和业务描述,方便通过语义去召回。
除此之外,还有一个很关键的点:
我们对常用维度字段的取值也建立了索引。
因为有些查询,是必须用到具体维度值的,比如:
“统计一下华北地区的销售总额”,SQL 里就一定要出现“华北地区”这个具体的值。
这里我们用的是全文索引,而不是向量索引。
因为字段取值更偏向文本匹配,而不是语义匹配。
以上,就是整个元数据知识库的设计。
接下来我讲一下查询流程,这个流程是用 langgraph 来编排的。
当用户提问后,第一步我们会先做关键词提取,主要是去掉一些无用词,比如停用词、语气词,让后续检索更精准。
然后根据这些关键词,分别去召回:
字段信息
指标信息
字段取值
召回之后,会做一次信息整合,大概的逻辑是:
如果召回了某个指标,就把这个指标相关的字段也补充进来
如果召回了某个字段取值,就把它加入到对应字段的示例里
最后再按“表”把字段分组整理
整理好之后,我们没有直接交给大模型,而是又做了一次精筛。
这一步是用大模型来做判断:哪些信息是真正有用的。
经过这一步之后,就得到了生成 SQL 所需的最小充分上下文。
然后才把:用户问题 + 精筛后的表信息 + 指标信息,一起交给大模型去生成 SQL。
SQL 生成之后,我们还会通过 EXPLAIN 做一次校验,如果语法有问题,会把报错信息再交给大模型做自动修正
确认没问题之后,才真正执行 SQL
以上,就是整个智能问数从提问到最终生成并执行 SQL的完整流程。