项目周期#
- 2人团队,总计约3个月。
- 需求分析与架构设计2周
- 数据管道搭建与调试3周
- 实体抽取模块开发与测试4周
- 索引构建与应用层开发1周
- 部署与测试2周
功能介绍#
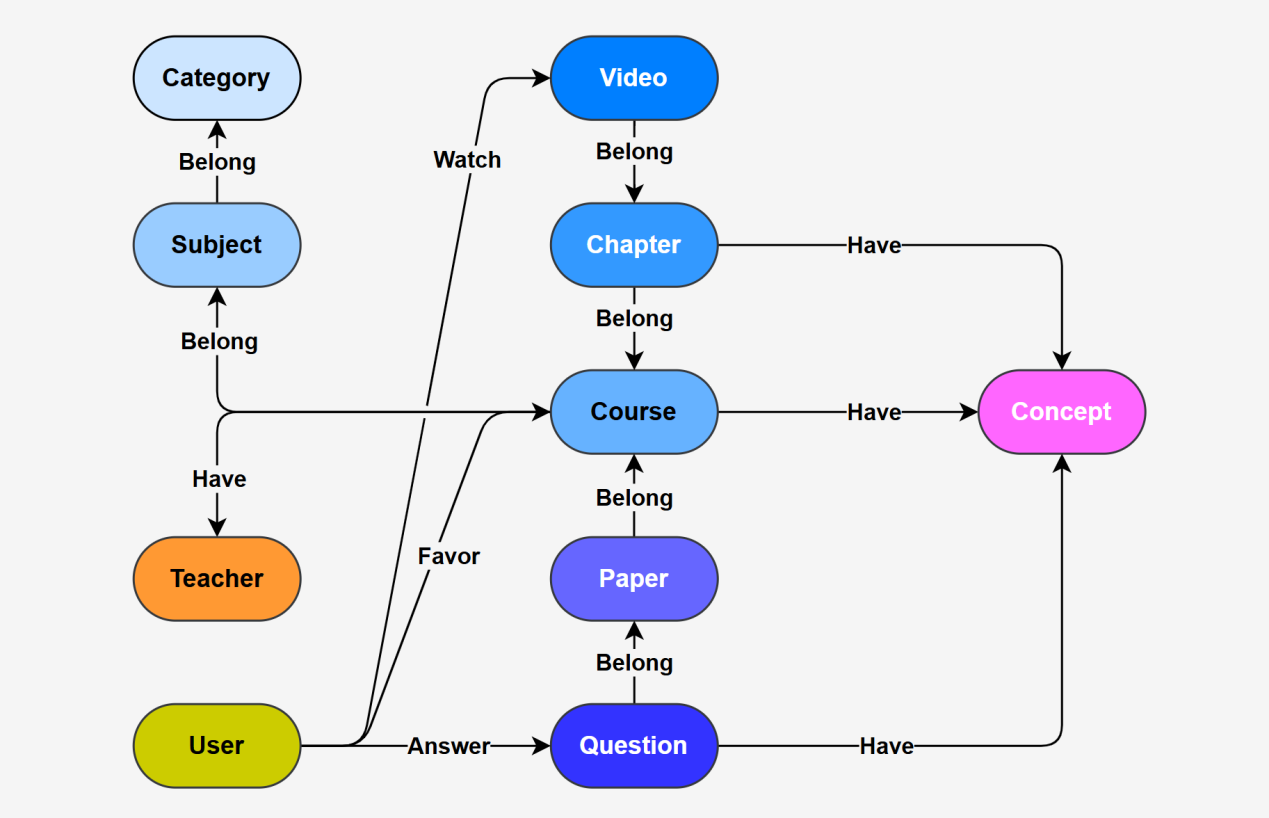
在线教育平台知识图谱基于Neo4j图数据库构建,包含分类、学科、课程、章节、视频、试卷、试题以及各种知识点,同时记录了用户部分行为用于后续构建用户画像。
数据的主要来源是业务数据库中的结构化数据,以及部分非结构化数据,实现了图谱与业务数据库数据的实时同步。
为方便上层应用,为图谱中的数据构建了全文索引和向量索引,以支持全文检索和语义检索。
完整架构如下图所示:
实现流程#
Q数据建模#
业务数据库#
业务数据库中的数据模型如下图所示:
模型原文件如下:
图数据库#
图数据库中的数据模型与业务数据库基本保持一致,如下图所示。
Q数据同步#
为保证数据的时效性,搭建了一条数据的实时同步通道,如下图所示。
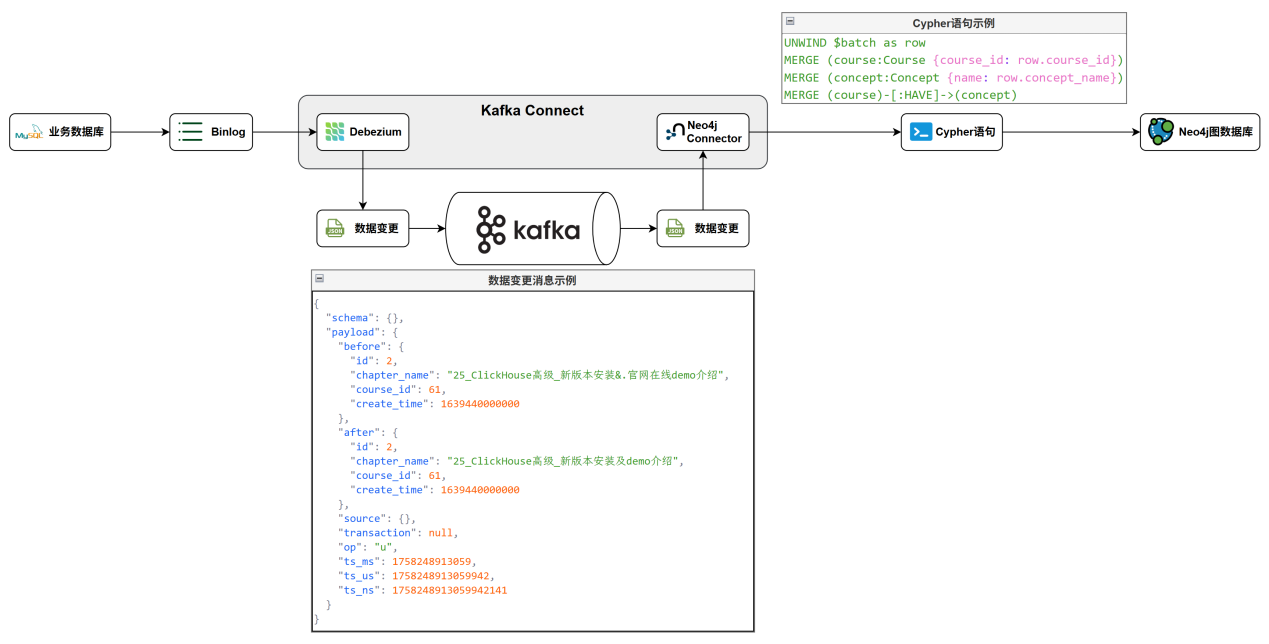
上述流程涉及到的组件有:
Kafka——消息队列,用于承载和传输Mysql的数据库变更事件。
Debezium——监听 MySQL Binlog,实时捕获数据库的插入、更新、删除操作,并将变更数据写入 Kafka。
Neo4j Kafka Connector——从 Kafka 消费变更数据并转换为 Cypher 语句,将变更数据实时写入 Neo4j 图数据库。
Q实体抽取#
因为有些课程、章节在录入时,部分相关知识点并未录入,而是直接包含在了课程描述、章节标题中,所以我们就需要从课程描述、章节标题中将这些知识点抽取出来,以填补缺失的知识点。
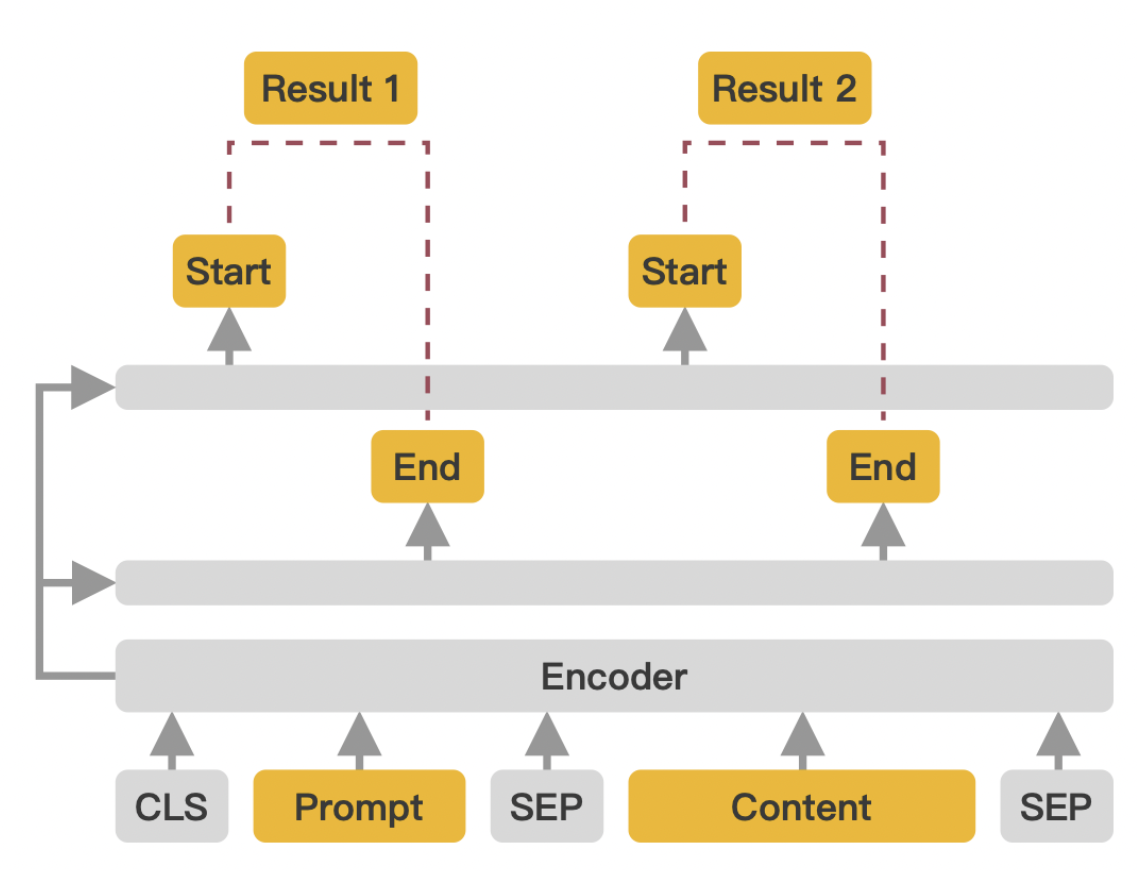
知识点抽取使用的模型是百度开源的通用抽取模型——UIE,其基于ERNIE模型,并在ERNIE模型的基础上增加了两个线性层,一个用于预测实体的起始位置,一个用于预测结束位置。
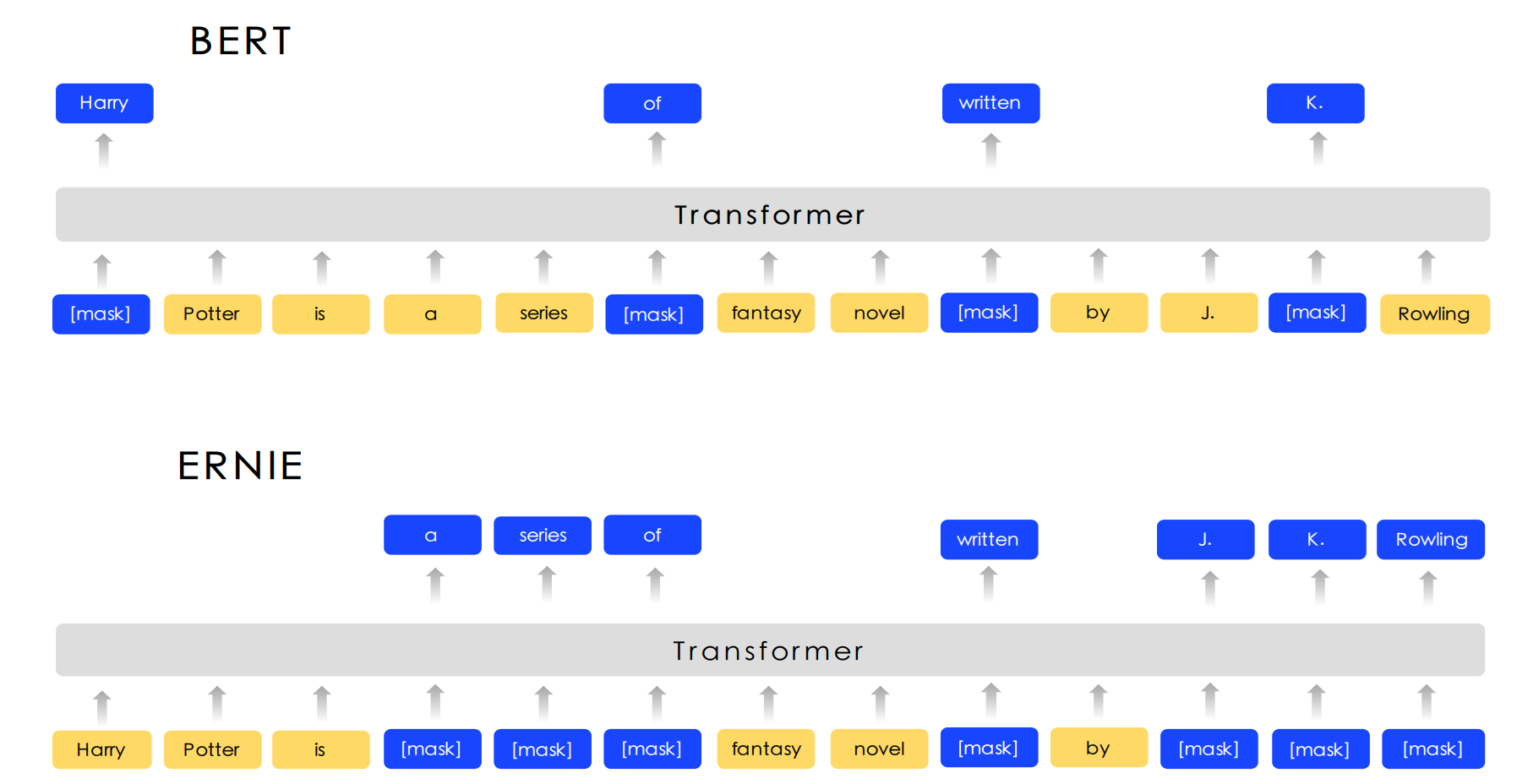
ERNIE和BERT的结构类似,都是编码器模型。不同的是预训练方式,BERT在训练时是随机掩盖若干个独立的token,然后令模型预测这些token,而ERNIE在训练时不是掩盖单个Token,而是掩盖整个实体,这样模型就能学到更丰富的实体知识,所以其在实体抽取任务上更有优势。
Q创建索引#
为方便上层应用查询,创建了全文索引和向量索引。
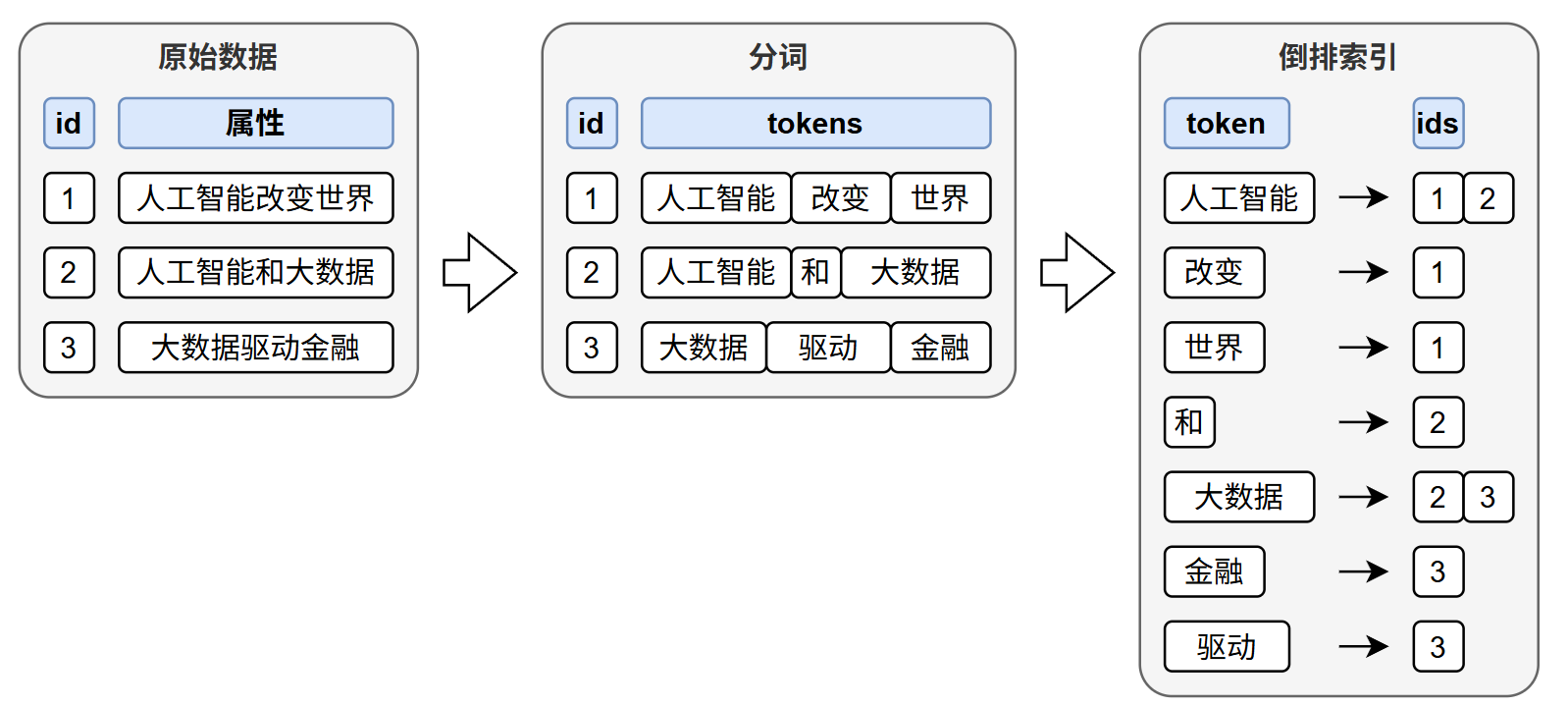
全文索引#
全文索引的基本原理如下图所示:
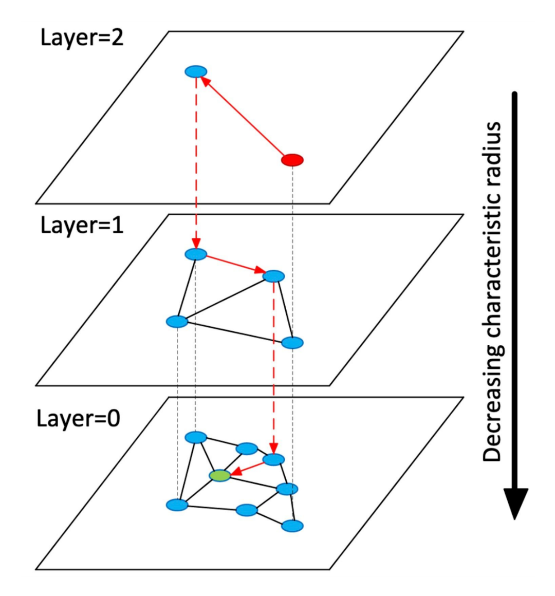
向量索引#
Neo4j底层的向量索引算法为HNSW(Hierarchical Navigable Small World),其原理图如下所示:
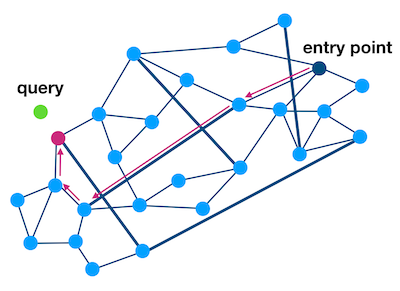
HNSW算法借鉴了如下算法:
NSW(Navigable Small World)
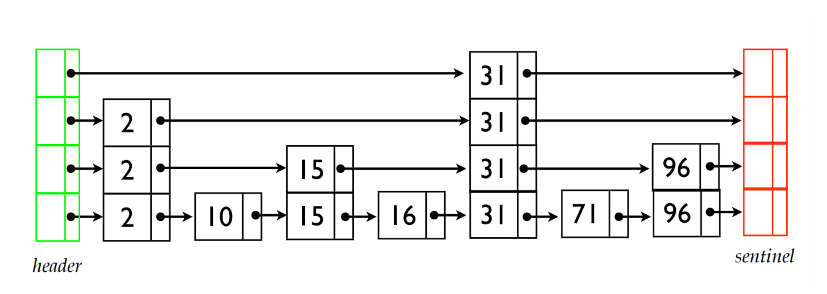
Skip List
技术细节#
Q实体抽取模型#
实体抽取采用百度开源的UIE模型,UIE支持零样本预测,但在我们实际的这个场景中,直接使用的效果不太理想,因此又对齐进行了微调。微调细节如下图所示:
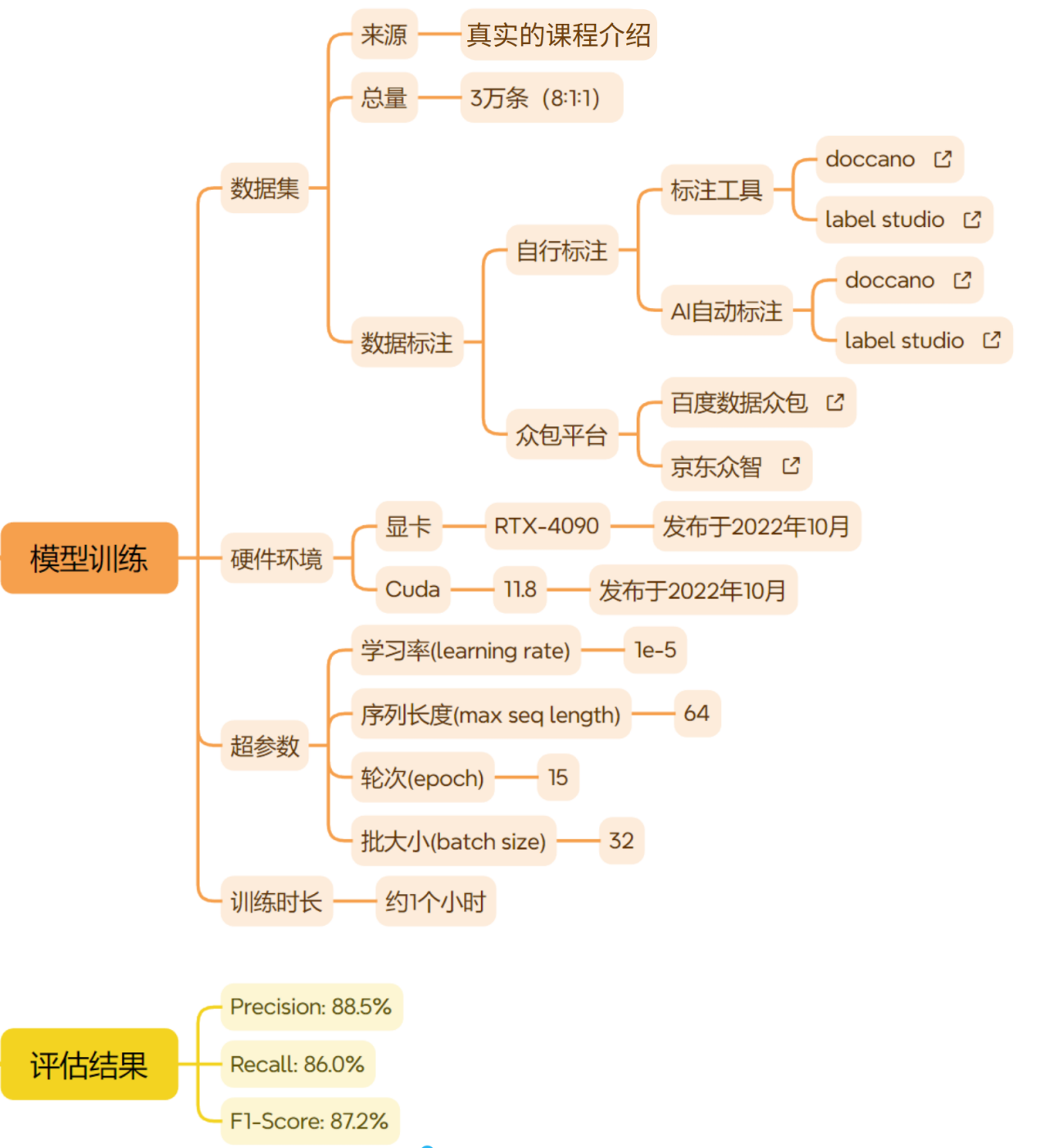
QEmbedding模型#
采用BAAI/bge-small-zh-v1.5,向量维度为512。
总结#
我们搭建这在线教育知识图谱的初衷主要是为上层的AI应用提供数据支撑,比如智能客服、推荐系统等等。
这个图谱主要的数据来源是业务数据库中课程相关的表格,包括学科、课程、章节、视频、试卷等,这些大都是结构化的数据,除此之外,还有一些非结构化的数据,例如课程描述,章节标题,我们需要从这些数据中将知识点抽取出来,以构建知识体系网络。
下面我先介绍一下数据通道,我们的业务数据库是Mysql,图谱用的是Neo4j,为了保证图谱数据的时效性,我们设计并搭建了一条实时的数据同步通道。
首先使用Debezium监听MySql的Binlog,从而获取变更数据,Debezium会将变更数据写入Kafka消息队列中。然后我们又使用了Neo4j官方提供的一个Kafka Connector,它可以实时消费Kafka中的变更数据,只要有新的变更数据,它就会执行我们指定的Cypher语句,将变更数据写入Neo4j,从而完成Neo4j与MySql数据的实时同步。
然后我再重点介绍一下同步过程中的实体抽取,这个实体抽取主要是从课程描述和章节标题中抽取知识点,这里我们使用了百度开源的一个通用信息抽取模型,叫做UIE,这个模型以百度自家的ERNIE预训练模型作为基础。ERNIE和BERT的结构类似,都是编码器模型。但它们的预训练方式不一样:BERT在训练时是随机掩盖若干个独立的token,然后令模型预测这些token,而ERNIE在训练时不是掩盖单个Token,而是掩盖整个实体,这样模型就能学到更丰富的实体知识,所以其在实体抽取任务上更有优势。
然后在UIE在ERNIE的基础之上,又使用了两个线性层,一个线性层用于预测实体的起始位置,另一个线性层用于预测结束位置。在推理时,根据起始位置和结束位置就能截取到实体信息了。
UIE是支持零样本预测,但在我们实际的这个场景中,直接使用的效果不太理想。所以我们人工标注了大约3万条数据,对模型进行了微调。调优之后,F1值达到了88%,基本满足了我们业务上的要求。
最后,数据进入Neo4j之后,为了支持上层复杂查询,我们给图谱建立了两种索引:一个是全文索引,主要用于关键词检索;另一个是向量索引,用于语义相似度查询,当然,建立向量索引需要先有向量,这里我们使用的Embedding模型是BGE,这是一个开箱即用的高质量Embedding模型,不需要微调就能有很好的效果。
以上就是这个图谱项目的全部内容。