项目周期与分工#
- 3人团队,6周
- 需求分析&设计:1周
- 数据采集模块:1周
- 知识库核心开发:2周
- RAG问答&前端:1周
- 测试&优化&上线:1周
Q第一阶段:需求分析与架构设计(Week 1)#

Q第二阶段:数据采集模块开发(Week 2)#

Q第三阶段:知识库核心模块开发(Week 3-4)#

Q第四阶段:RAG问答与前端开发(Week 5)#

Q第五阶段:测试与上线(Week 6)#
Q团队分工建议#
项目概述#
Q项目背景#
业务场景:#
为企业提供一战式智能知识库解决方案,实现技术支持文档的智能检索与问答,帮助用户快速获取精准答案。
核心价值:#
- 智能问答:基于RAG技术,将用户自然语言问题转化为精准的知识库检索,并生成结构化答案
- 多路召回:融合向量检索和关键词检索,显著提升召回率和检索准确性
- 知识管理:支持文档上传、自动切分、向量化存储,构建企业专属知识库
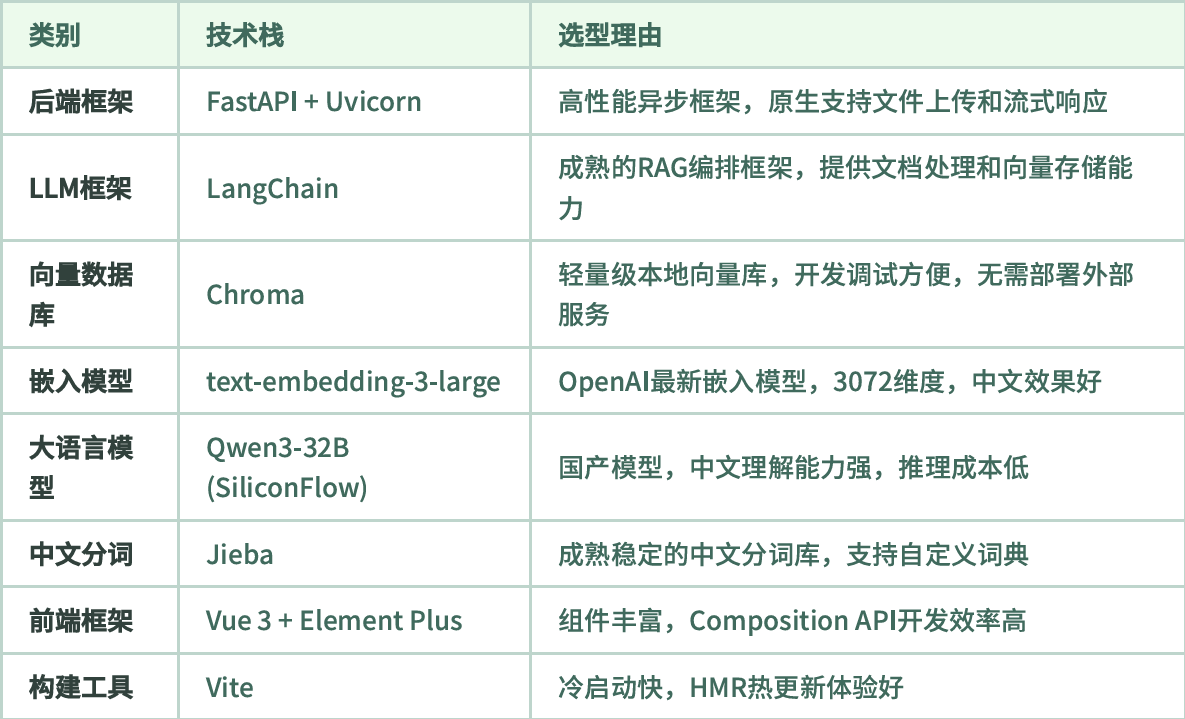
Q技术选型#
整体架构设计#
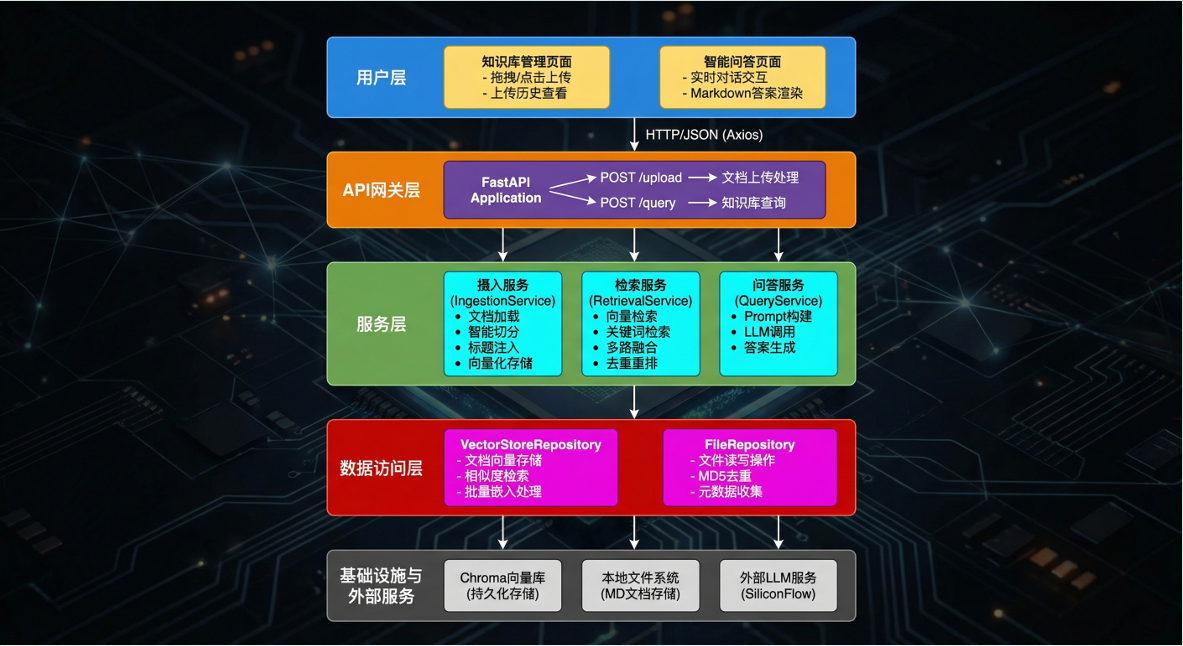
Q系统架构图#
QRAG核心流程图#
核心模块详解#
Q数据采集模块(Crawler)#
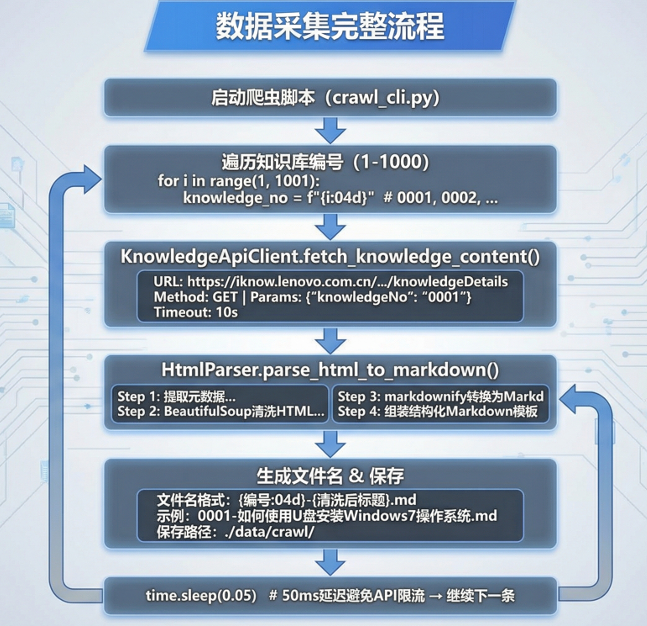
数据采集是知识库系统的基础,整个流程分为五个阶段。
第一阶段:#
- 首先启动我们的爬虫脚本(crawl_cli.py)
- 遍历我们的知识库编号(1-1000)
- 格式化编号0001,0002……
第二阶段(API调用获取数据):#
- 向知识库API发送GET请求
- 传入konwledgeNo参数
- 设置10s保护
- 获取原始HTML内容
第三阶段(HTML转Markdown):#
- 提取元数据(标题/摘要/关键词)
- BeautifulSoup清洗HTML(移除script/style)
- markdownify转换为markdown
- 组装结构化markdown模板
第四阶段(文件保存):#
- 生成文件名(文件名格式: {编号:04d}-{清洗后标题}.md)
- 保存到./data/crawl/
第五阶段(速率控制):#
设置50ms延迟避免API限流→继续下一条
Q文档摄入模块#
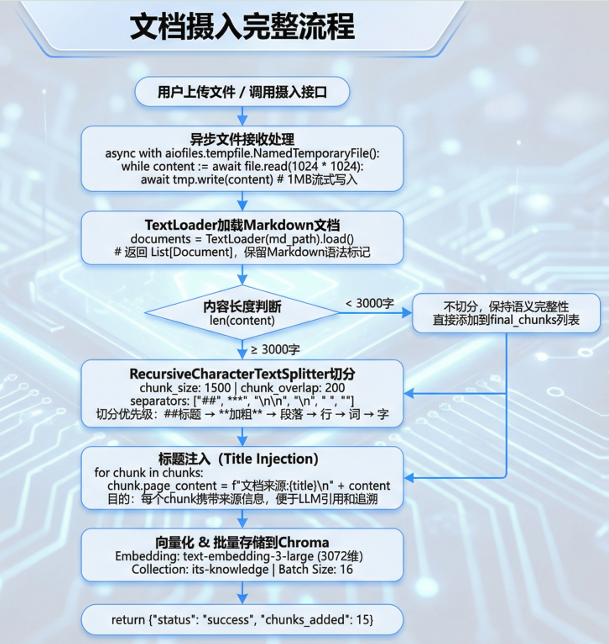
文档摄入是将原始文档转化为可检索向量的核心环节,整个流程分为六个阶段。
第一阶段(异步文件接收):#
- 当前用户通过前端上传文件或者调用/upload接口时,FastAPI使用aiofiles库进行异步文件处理;
- 采用1MB缓冲的流式读写方式,避免大文件一次性加载到内存导致OOM问题;
- 文件首先写入临时目录,处理完成后再移动到正式目录。
第二阶段(加载Markdown文档):#
使用LangChain的TextLoade加Markdown文档,该加载器会保留Markdown的语法 标记(如 ## 标题、 ** 加粗),返回Document对象列表,每个对象包含page_content (⽂本内容)和metadata(元数据)两个属性。
第三阶段(动态切分策略):#
系统会判断⽂档⻓度:如果内容少于3000字符,认为是⼩⽂档,直接保持完整不切分,避免过度碎⽚化导致语义割裂;如果内容超过3000字符,则使⽤RecursiveCharacter-TextSplitter 进⾏递归切分,设置每块1500字符、重叠200字符,分隔符按语义优先级排列。
第四阶段(标题注入机制):#
对于每个切分后的chunk,在内容开头添加文档来源:{原文档标题}前缀;这样做的⽬的是让每个chunk都携带来源信息,即使被切分后也能追溯到原⽂档,便于LLM在回答时正确引⽤来源。
第五阶段(向量化和批量存储):#
调⽤OpenAI的text embedding 3 large 模型将⽂本转换为3072 维向量;为避免单次API调⽤超限,采⽤batch_size=16的分批处理策略;最终将向量存储到 Chroma数据库的 its knowledge 集合中。
第六阶段:返回摄入结果,包含添加的chunk数量供前端展示。
Q检索服务模块#
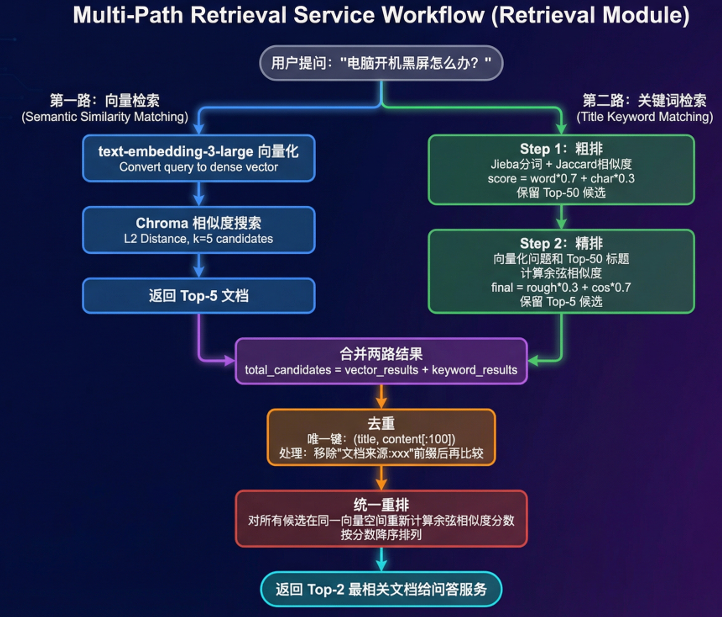
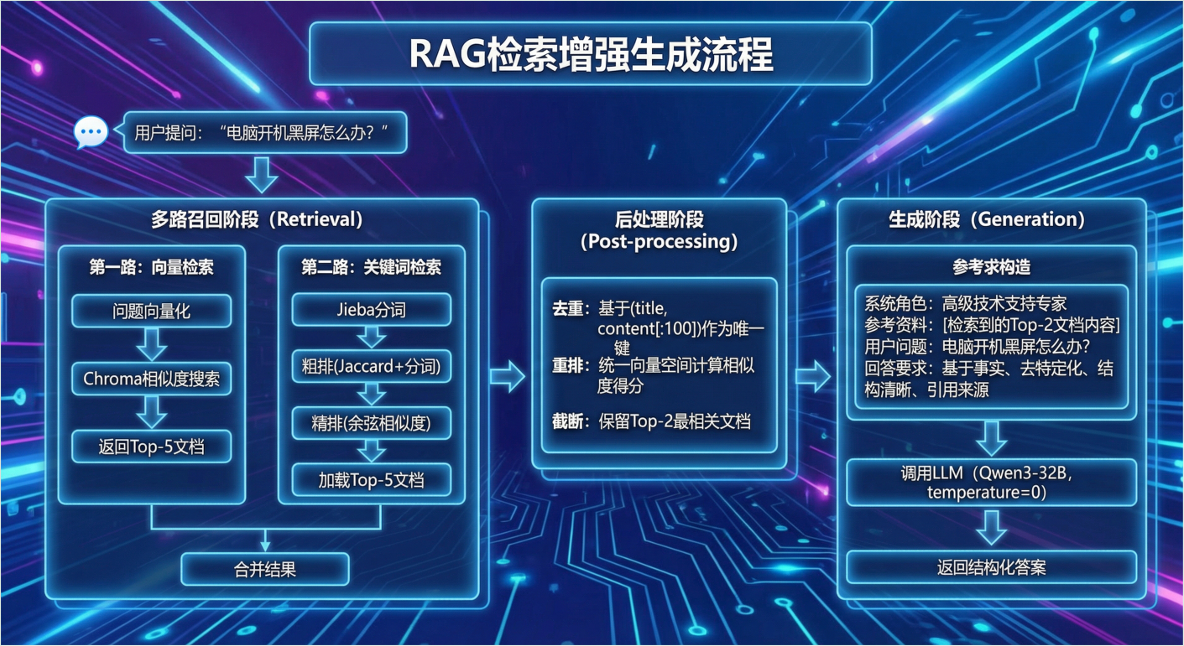
检索服务模块时RAG系统的核心,采用多路召回策略提高检索质量,整个流程分为5个阶段。
第一阶段(并行的双路检索):#
- 第一路是向量检索,将用户问题勇敢text-embedding-3-large模型转换为3072维向量,然后在Chroma向量数据库中执行显示路检索,返回L2距离最小的Top-5文档;这一路的优势是能捕获语义相似性,比如“电脑无法开机”和“计算机启动失败”虽然泳池不同但语义相近。
- 第二路是关键词检索,不依赖向量而是直接匹配标题中的关键词;这一路的优势是对精确匹配场景(如型号、代码错误)效果更好。
第二阶段(关键词的两阶段排序):#
粗排阶段#
- 使⽤Jieba对⽤⼾问题和所有⽂档标题进⾏中⽂分词,计算Jaccard相似度;
- 公式是分词交集大小/分词并集大小 ,同时加⼊字符级别的相似度作为补充,最终分数按7:3加权;
- 粗排从全量⽂档中快速筛选出Top-50候选,⼤幅缩⼩精排的计算范围。
精排阶段#
将问题和Top-50标题都向量化,计算余弦相似度,与粗排分数按3:7加权得到最终分数,保留Top-5。
第三阶段(合并去重):#
将两路检索的结果合并,可能存在同⼀⽂档被两路都召回的情况;使⽤(标题, 内容前100字符) 作为唯⼀键进⾏去重,注意需要先移除"⽂档来源:xxx前缀再⽐较,确保不同chunk能被正确识别为同⼀⽂档的⽚段。
第四阶段(统一重排序):#
因为两路检索使⽤了不同的打分机制(L2距离vs余弦相似度),需要在同⼀向量空间重新计算分数;对每个去重后的候选⽂档,取内容前500字符进⾏向量化,与问题向量计 算余弦相似度作为最终得分。
第五阶段(生成回复):#
按分数降序排列后,返回Top-2⽂档给问答服务,这两个⽂档将作为LLM⽣成答案的上下⽂。
Q问答服务模块(Query)#
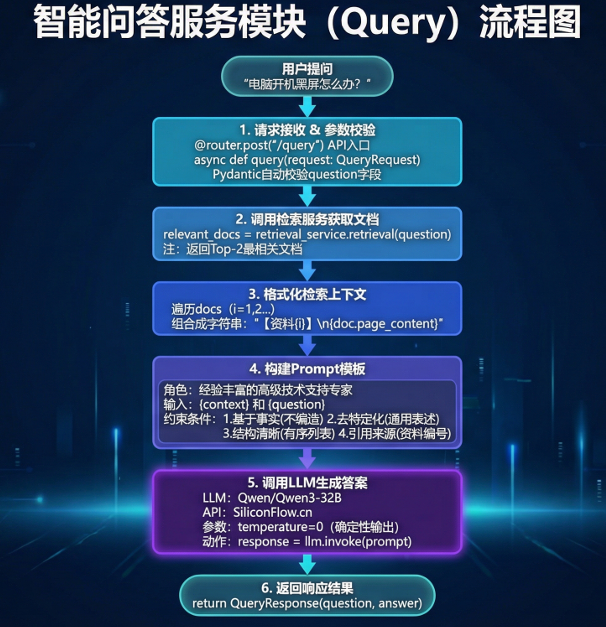
问答服务是将检索结果转化为⾃然语⾔答案的关键环节,整个流程分为五个阶段。
第一阶段(请求接收和参数校验):#
前端通过axios发送POST请求到 /query 接⼝,请求体包含question 字段;FastAPI使⽤Pydantic的QueryRequest 模型自动进⾏参数校验,确保question 字段存在且为字符串类型,校验失败会⾃动返回422错误码和详细的错误信息。
第二阶段(调用检索服务):#
实例化 RetrievalService 并调⽤其retrieval() ⽅法,传⼊用户问题;检索服务会执⾏多路召回、去重、重排等⼀系列操作,最终返回Top-2最相关的⽂档列表;这两个文档将作为LLM生成答案的上下⽂参考。
第三阶段(格式化检索上下文):#
将检索到的⽂档列表转换为结构化的⽂本;每个⽂档添加【资料 1】 、【资料2】的编号前缀,便LLM在回答时引⽤;多个文档之间用双换行分隔,保持清晰的层次结构。
第四阶段(Prompt工程):#
这是影响答案质量的关键环节。Prompt,模板包括四个部分:
- 首先是系统角色设定,将LLM定位为"经验丰富的⾼级技术支持专家";
- 其次是参考资料区,注⼊格式化后的检索上下⽂;
- 然后是用户问题区;
- 最后是回答要求,明确指导LLM的⾏为⸺基于事实回答不编造、 去特定化处理移除品牌型号、使⽤有序列表保持结构清晰、引⽤来源便于溯源验证。
第五阶段(调用LLM生成答案):#
使⽤LangChain封装的ChatOpenAI 客户端,配置SiliconFlow的API地址和千问3-32B模型;关键参数是temperature=0,设置为0意味着确定性输出,相同的输⼊会得到相同的输出,避免随机性导致的不⼀致问题;LLM返回的答案是Markdown格式,最后将问题和答案封装成QueryResponse返回给前端渲染。
Q前端交互模块#
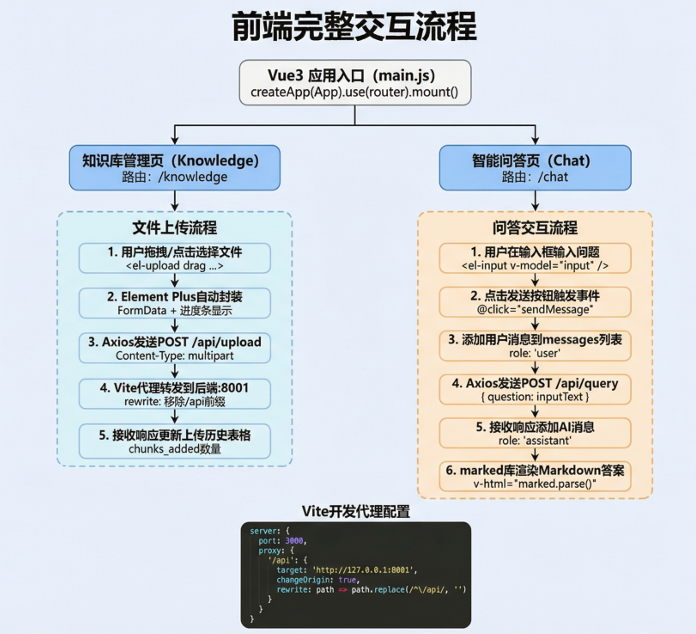
前端交互模块提供⽤⼾友好的界⾯,整个流程分为两条主线:知识库管理和智能问答。
知识库管理流程:#
第⼀阶段,用户在知识库管理⻚⾯可以通过拖拽⽂件到上传区域,或点击选择⽂件的⽅式上传Markdown⽂档;Element Plus的el-upload 组件配置了drag属性⽀持拖拽上传。#
第二阶段,组件⾃动将⽂件封装成 FormData 格式,并显示上传进度条给用户实时反馈。#
第三阶段,Axios发送POST请求到/api/upload接⼝,Content-Type设置为multipart/form data 。#
第四阶段,Vite开发服务器的proxy配置拦截 /api 前缀的请求,转发到后端8001端口,同时移除 /api 前缀确保路径正确。#
第五阶段,接收后端响应后触发on success 回调,将上传结果(⽂件名、chunks_added数量、状态)添加到上传历史表格中展示。#
智能问答流程:#
第⼀阶段,用户在Chat⻚⾯的输⼊框中输⼊自然语言问题,输⼊框使⽤v-model双向绑定到inputText响应式变量。#
第二阶段,点击发送按钮触发sendMessage方法。#
第三阶段,⾸先将用户消息添加到消息列表,设置 role: 'user' 标识为用户消息,界面立即显示用户发送的内容。#
第四阶段,调⽤封装好的queryKnowledge API函数发送POST请求,传⼊问题字符串,等待后端处理和LLM⽣成答案。#
第五阶段,接收到后端响应后,将AI回复添加到消息列表,设置role: 'assistant' 标识为AI消息。#
第六阶段,使⽤marked库将Markdown格式的答案渲染为HTML,通过v-html指令插⼊到消息⽓泡中,支持有序列表、代码块语法⾼亮、链接可点击等丰富的格式展示。#
跨境问题解决:#
开发环境下前端运行在3000端口,后端运⾏在8001端口,直接请求会触发浏览器的CORS限制;通过Vite的proxy配置将 /api 前缀的请求代理到后端,实现同源请求绕过跨域限制;生产环境可使⽤Nginx做反向代理实现相同效果。
技术细节与痛点分析#
Q核心技术细节#
异步文件处理优化#

Chroma向量检索距离理解#

中文分词与相似度计算#

Q痛点问题与解决方案#
中文嵌入效果不理想问题#
文档切分导致语义丢失问题#
检索结果重复问题#
LLM答案过于具体化问题#
前后端联调跨域问题#
Q性能优化点#
项目总结#
Q项目亮点#
- 多路召回策略:创新性地融合向量检索和关键词检索,显著提升召回率
- 智能⽂档切分:动态策略+标题注⼊,平衡语义完整性和检索精度
- 两阶段排序:粗排快速过滤 + 精排精准排序,兼顾效率和效果
- 企业级架构:清晰的分层设计,符合生产环境开发规范
Q技术收获#
Q可优化方向#
- 支持更多文档格式(PDF,Word,Excel)
- 添加对话历史管理,支持多轮对话
- 引入用户反馈机制,持续优化检索效果
- 支持知识库版本管理和增量更新
面试高频问题回答#
Q项目介绍类#
简单介绍以下这个项目#
这是⼀个基于RAG技术的企业级智能知识库问答系统。系统从企业知识库采集数据,通过⽂档切分、向量化存储到Chroma数据库。用户提问时,采⽤多路召回策略(向量检索+关键词检索)找到 相关⽂档,然后通过LLM⽣成准确的答案。前端使⽤Vue3+Element Plus,后端使⽤ FastAPI + LangChain。
为什么选择这个技术栈?#
- FastAPI:⾼性能异步框架,适合IO密集型的LLM调用场景
- LangChain:成熟的LLM应⽤框架,提供⽂档处理、向量存储、链式调⽤等功能
- Chroma:轻量级本地向量数据库,开发调试方便,无需部署外部服务
- Vue3:响应式组合式API,更好的TypeScript⽀持和性能
Q技术深度类#
解释以下RAG的工作原理?#
RAG(Retrieval-Augmented Generation)检索增强⽣成,核心思想是:
- Retrieval(检索):将用户问题转换为向量,在向量数据库中检索相似⽂档
- Augmented(增强):将检索到的文档作为上下⽂,与用户问题⼀起构建Prompt
- Generation(⽣成):LLM基于增强后的Prompt生成答案优势:解决LLM知识过时、幻觉等问题,让回答基于实际⽂档内容。
为什么要采用多路召回而不是单纯的向量检索?#
单纯向量检索存在以下问题:
- 中⽂嵌⼊模型对某些专业术语理解不够准确
- 语义相似但关键词不同的文档可能排名靠后
- 对于精确匹配场景(如型号、错误代码)召回率不高
多路召回策略: 第⼀路向量检索:捕获语义相似性 第二路关键词检索:捕获精确匹配 融合后去重、重排,提⾼整体召回率和准确率
文档切分时为什么要设置overlap?#
overlap(重叠区间)的作用:
- 防止边界处语义断裂:如果一个概念刚好在切分边界,没有overlap会导致语义信息不完整。
- 提高检索命中率:边界词汇在相邻chunk中都出现,增加被检索到的概率
- 典型设置:chunk_size=1500,overlap=200,重叠率约13%
Chroma返回的时什么分数?如何理解?#
Chroma 的similarity_search_with_score返回的是L2距离(欧几里得距离),不是余弦相似度。
- L2距离越小,相似度越高
- 如需转换为0-1的相似度分数:
- 在重排阶段需要注意这个区别,与自己计算的余弦相似度分数进行归一化
Q问题解决类#
项目中遇到的最大的挑战是什么?#
最大挑战是提升检索准确率。
问题表现:#
早期只⽤向量检索,对于包含专业术语的问题召回率不高。
解决过程:#
分析Case发现关键词匹配能捕获向量检索遗漏的⽂档#
设计两阶段关键词检索:粗排(Jaccard)→ 精排(向量余弦)#
融合两路结果,去重后统⼀重排#
召回率从65%提升到85%#
如何保证LLM回答的准确性?#
多层保障机制:
- 检索质量:多路召回+重排,确保检索到最相关的⽂档
- Prompt设计:明确要求"基于事实回答,不编造信息"
- temperature=0:使⽤确定性输出,避免随机性导致的错误
- 引⽤来源:要求LLM引⽤参考资料编号,便于溯源验证
Q扩展思考类#
如果要部署到生产环境,需要做哪些改进?#
回答要点:
- 向量数据库:Chroma换成Milvus/Pinecone,支持分布式和高并发
- 缓存层:添加Redis缓存热点问答,减少重复计算
- 异步队列:大文件上传适用Celery异步处理
- 监控告警:接入Prometheus + Grafana监控API性能
- 负载均衡:多实例部署,使用Nginx负载均衡
如何评估RAG系统的效果?#
主要评估指标:
- 召回率(Recall):检索到相关文档的比例
- 准确率(Precision):检索结果中相关文档的比例
- MRR(Mean Reciprocal Rank):第一个相关结果的排名倒数
- Answer Quality:人工评估答案的准确性、完整性、可读性
- 响应时间:端到端延迟,包括检索+生成
面试口述版项目总结#
Q30s版#
我开发了⼀个基于RAG技术的企业级智能知识库问答系统。系统采⽤多路召回策略(向量检索+关键词检索)提升检索准确率,使⽤两阶段排序(粗排+精排)优化结果质量。后端使⽤ FastAPI + LangChain + Chroma,前端使⽤ Vue 3 + Element Plus。我主要负责检索服务和文档处理模块的 设计与实现。
Q2分钟版#
项⽬背景#
这是⼀个企业级智能知识库问答系统,⽬标是让⽤⼾通过自然语言提问,快速从海量技术⽂档中获取精准答案。传统关键词搜索无法理解语义,我们通过RAG技术解决这个问题。
技术架构#
系统分为四个核⼼模块:
- 数据采集:爬⾍从企业知识库采集⽂档,转换为Markdown格式
- 文档摄⼊:智能切分⽂档,向量化后存储到Chroma数据库
- 检索服务:多路召回 + 两阶段排序,提升检索质量
- 问答服务:构建Prompt调⽤LLM⽣成结构化答案
后端使⽤ FastAPI 框架,集成LangChain处理⽂档和向量存储。⼤模型使⽤千问3-32B,通过 SiliconFlow API调⽤。前端使⽤ Vue 3,⽀持⽂档上传和实时问答。
我的职责#
我主要负责检索服务的设计与实现,包括多路召回策略、两阶段排序算法、去重与重排逻辑。同时设计了标题注⼊机制解决⽂档切分后的语义丢失问题。
技术亮点#
项⽬有⼏个技术亮点:
- 多路召回策略,将召回率从65%提升到85%+;
- 标题注⼊机制,让每个chunk保留来源信息;
- Prompt⼯程优化,实现基于事实回答和去特定化处理。
Q5分钟版#
项目背景与目标#
这是⼀个企业级的智能知识库问答系统,服务于企业的技术支持场景。传统的关键词搜索无法理解用户的真实意图,⽐如用户问"电脑开不了机",可能搜不到"计算机启动失败"的⽂档。我们的⽬标是通过RAG技术,让系统理解语义,精准匹配问题和答案。
整体架构设计#
系统采⽤前后端分离架构,分为三层:
展示层:Vue 3 + Element Plus,实现⽂档上传和智能问答界⾯#
服务层:FastAPI 应⽤,提供上传和问答两个核⼼接口#
数据层:Chroma向量数据库存储⽂档向量,⽀持相似度检索#
核⼼是RAG流程:用户提问 → 检索相关⽂档 → 构建Prompt → LLM⽣成答案。
核心技术实现#
- 多路召回:单纯向量检索对中⽂专业术语理解不够准确,我设计了双路召回策略。第⼀路向量检索捕获语义相似性,第二路关键词检索捕获精确匹配。两路结果合并后去重、重排,召回率从65%提 升到85%+。
- 两阶段排序:关键词检索路使⽤两阶段排序。粗排阶段⽤Jieba分词 + Jaccard相似度快速筛选 Top-50候选;精排阶段将候选向量化,计算余弦相似度得到最终排名。这样既保证效率又保证准确性。
- 标题注⼊:⽂档切分后各个chunk会丢失上下⽂信息。我设计了标题注⼊机制,在每个chunk开头添加"⽂档来源:{标题}"前缀,让LLM能正确引⽤来源。
- Prompt⼯程:设计了四项回答要求⸺基于事实回答不编造、去特定化处理移除品牌型号、使用有序列表保持结构清晰、引⽤来源便于验证。
遇到的挑战与解决方案#
最⼤的挑战是提升检索准确率。早期只用向量检索,对于包含专业术语的问题召回率不⾼。分析 Case后发现,关键词匹配能捕获向量检索遗漏的⽂档。于是设计了多路召回 + 两阶段排序的方案,效果显著提升。
另⼀个挑战是文档切分导致语义丢失。用户问XX问题怎么解决",检索到的chunk可能只包含解决方案,没有问题描述,LLM⽆法判断是否匹配。通过标题注⼊机制解决,每个chunk都携带来源信息。
项目成果与收获#
项目实现了完整的RAG问答功能,⽀持⽂档上传、智能检索、结构化回答。技术上,深⼊理解了 RAG架构、向量检索原理、⽂档处理策略。⼯程上,锻炼了从需求分析到架构设计再到编码实现的 全流程能⼒。
如果有机会优化,我会考虑引⼊Reranker模型进⼀步提升精排效果,以及添加用户反馈机制持续优化检索策略。
QSTAR法则回答模板#
问题:请介绍一个你解决过的技术难题#
S(Situation)-情境:#
在开发知识库问答系统时,早期只使用向量检索,对于包含专业术语的问题召回率只有65%左右。
T(Task)-任务:#
我需要提升检索的召回率和准确率,确保用户能找到真正相关的文档
A(Action)-行动:#
我设计了多路召回 + 两阶段排序的方案:
- 第一路向量检索:用embedding模型捕获语义相似性
- 第二路用关键词检索:使用Jieba分词 + Jaccard相似度捕获精确匹配
- 粗排快速过滤Top-50,精排用向量余弦相似度精准排序
- 两路结果合并后去重、统一重排,返回Top-2给LLM
同时设计了标题注入机制,让每个chunk保留来源信息。
R(Reslut)-结果:#
- 方案上线后,召回率从65%提升到85%+
- 用户反馈答案相关性明显提高,LLM也能正确引用来源了
Q常见追问#
技术亮点速记#
Q多回路召回策略#
- 向量检索(语义匹配)+关键词检索(精确匹配)
- 两路结果合并、去重、统一排序
- 召回率从65%提升到85%+
Q两阶段排序#
- 粗排:Jieba分词 + Jaccard相似度,快速过滤
- 精排:向量余弦相似度,精准排序
- 兼顾效率与准确性
Q智能文档切分#
- 动态策略:<3000字不切分,≧3000字递归字符切分
- Chunk_size=1500,overlap=200
- 分隔符优先级:##标题 > **加粗** > 段落 > 行
Q标题注入机制#
- 每个chunk添加“文档来源:{标题}”前缀
- 解决切分后语义丢失、来源追溯问题
QPrompt工程优化#
- 基于事实回答、不编遭信息
- 去特定化处理,移除具体品牌型号
- 结构化输出,使用有序列表
- 引用来源,便于溯源验证
Q异步文件处理#
- aiofiles流式读写,1MB缓冲
- 避免大文件OOM问题