项目周期#
1人团队,总计约3周。
需求分析与技术选型2天
数据准备与预处理3天
模型训练与评估3天
摘要生成模块开发5天
部署与测试3天
功能介绍#
日报/周报/月报/季报摘要总结一键生成。
员工可直接修改生成的摘要。

实现流程#
在摘要任务上微调BART模型。
使用模型生成员工汇报的摘要。
员工可修改生成的摘要,收集修改后的摘要用于继续训练模型。
夜间自动使用前一天修正后的摘要重新训练模型,热更新到线上。
技术细节#
Q数据来源#
起步阶段:#
开源摘要数据集:17万条数据,8:1:1划分训练集、验证集、测试集。
后续:#
收集前一天修正后的摘要用于训练模型。
Q摘要模型训练#
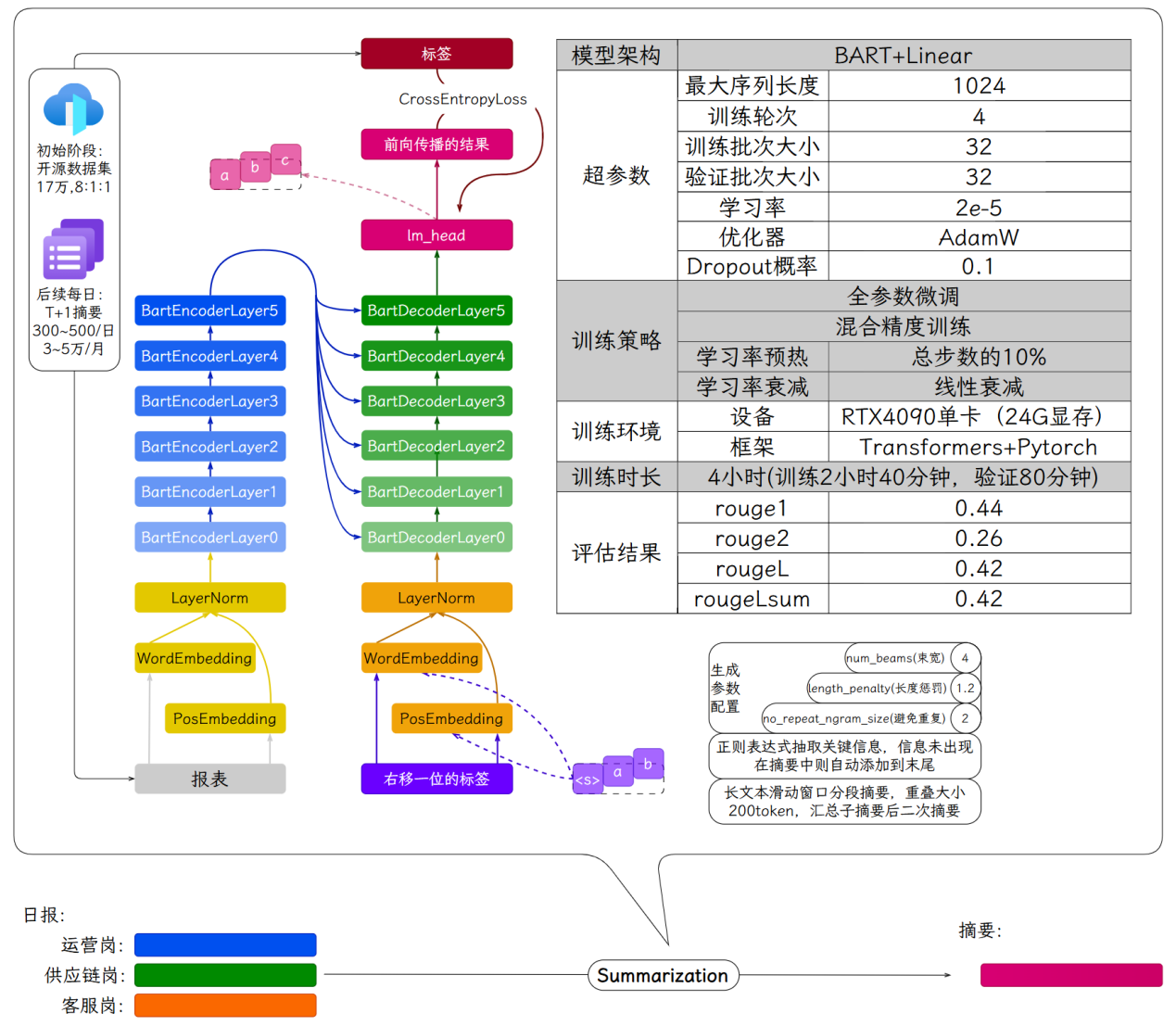
Q摘要生成#
生成参数#
num_beams束宽:4
length_penalty长度惩罚:1.2
no_repeat_ngram_size避免n元重复:2
关键信息强制保留#
用正则抽取金额、百分比、日期等关键信息,若未出现在摘要,则强制追加到摘要末尾。
处理超出长度上限的文本#
按段落或句子分段,每段有200 token重叠。为每段生成摘要拼接成最终摘要,或对段摘要二次生成摘要。
配合发布接口#
使用FastAPI将模型封装为RESTful API。
总结#
这个项目实现了一键生成日报、周报、月报、季报摘要的功能,还支持员工直接修改生成的摘要以优化模型性能。
项目主要包括摘要生成模型训练和摘要生成流程两部分。
首先,基于 bart-base-chinese 预训练模型,采用 BART+Linear 架构(BartForConditionalGeneration),训练了一个摘要生成模型。
训练数据初期来源于17万条开源摘要数据集。数据预处理后,在V100 32GB单卡上进行训练。训练4轮。最终模型评估rougeL 大约0.4左右。
摘要生成流程中,我们是使用束搜索(num_beams=4,length_penalty=1.2,no_repeat_ngram_size=2)生成摘要。
对于一些关键信息,比如金额、百分比、日期等,使用正则表达式进行抽取,如果摘要中不存在则添加到末尾,确保其出现在摘要中。
对于超长文本,采用分段处理(每段200 token重叠),生成段摘要后拼接或二次生成最终摘要。
后续也是通过收集员工修正后的摘要持续优化模型。每天收集员工修改后的摘要,用于夜间自动重新训练模型并热更新到线上。