项目周期#
- 2人团队,总计约3个月。
- 需求分析与技术选型1周
- 数据准备与预处理3周
- 模型开发与训练4周
- 系统集成与后端对接3周
- 部署上线2周
功能介绍#
Q项目背景#
用户在电商平台搜索商品时,传统的检索方式主要依赖倒排索引,这种方式实现简单,但是无法理解语义,仅做字面匹配,对同义词、语境、用户意图等不敏感,用户拼写错误时难以找到结果。
以查询:“小清新那种夏天穿的鞋子,不要太高,走路舒服”为例,传统倒排索引系统会先对查询进行分词(如“小清新 / 夏天 / 穿 / 鞋子 / 太高 / 走路 / 舒服”),然后逐个匹配关键词。
① 可能重点匹配“鞋子”,这一关键词将导致召回结果非常宽泛,例如:“高跟鞋”、“篮球鞋”、“登山鞋”。
② “小清新”这样的修饰词不常出现在商品标题或描述里,往往无法命中。
③ “不要太高”是否定语义,但倒排索引只会当作“高”来匹配,结果反而可能出现“高跟鞋”。
④ “走路舒服”属于主观描述,如果商品详情没有明确包含“舒服”,则无法匹配。
用户可能会搜到:
① “夏季新款高跟鞋”(错误匹配,“高”被误认为正向条件)
② “运动鞋 夏天款”(部分符合,但缺少“小清新”风格语义)
③ “小清新连衣裙”(因为有“小清新”关键字被召回,但不是鞋子)
而如果用语义搜索(向量检索),模型会将整句话编码为语义向量,能够搜到与整体语义最相近的商品。
基于上述背景,我们开发了基于语义搜索的文搜图模块,对于上文提到的查询,问搜图模块效果如下。

Q项目简介#
对于用户输入的文本查询,根据语义搜索相似商品。
实现流程#
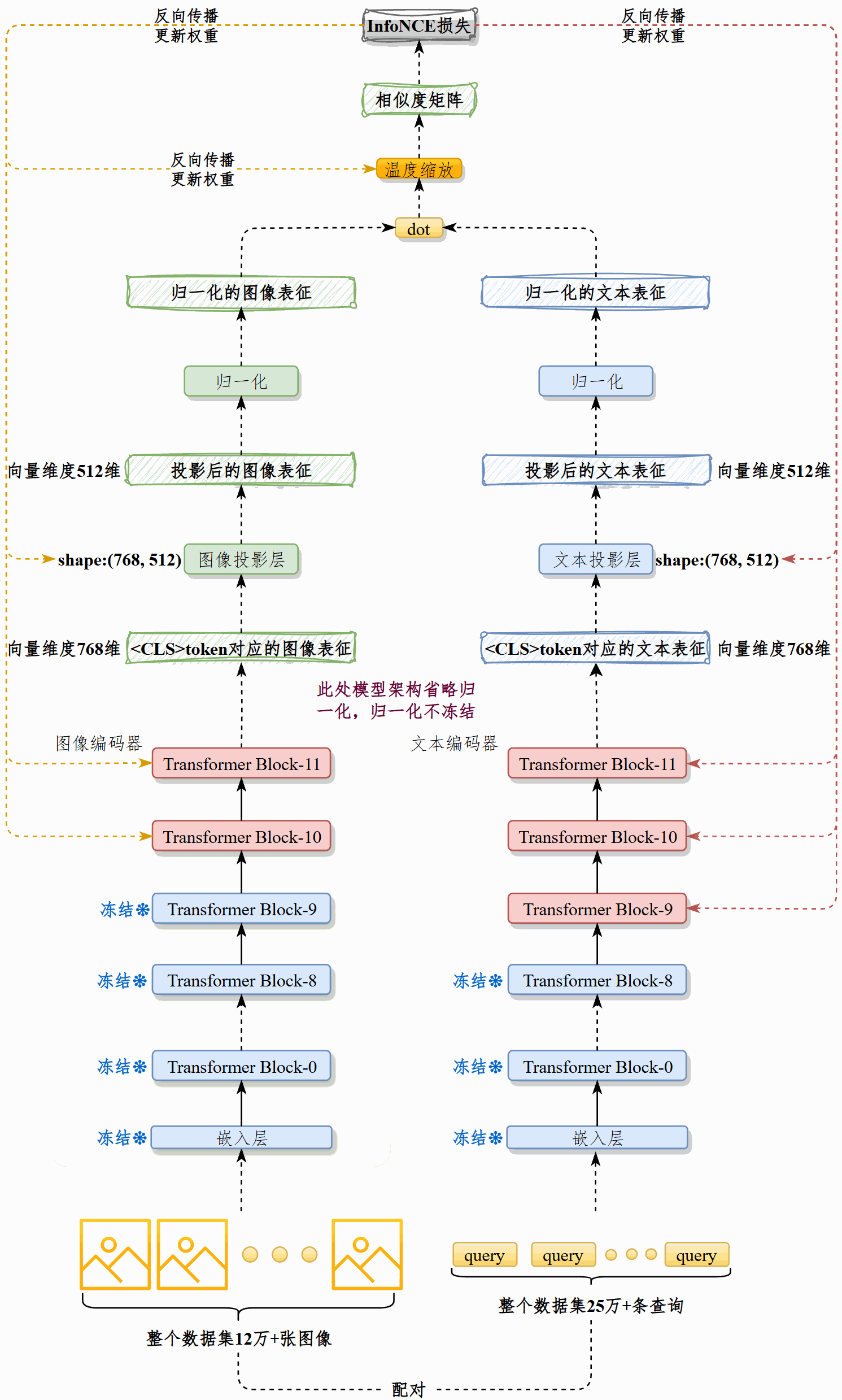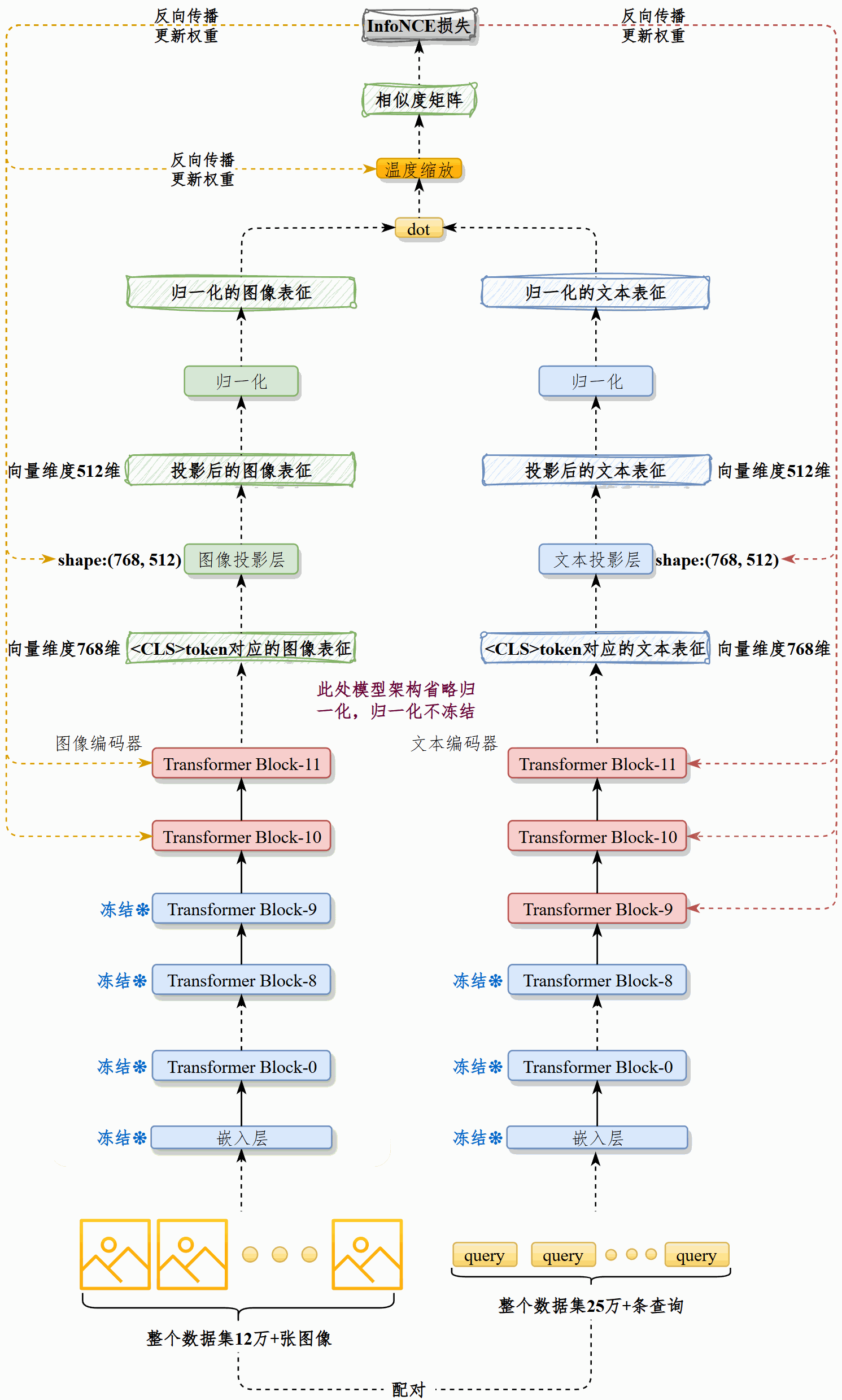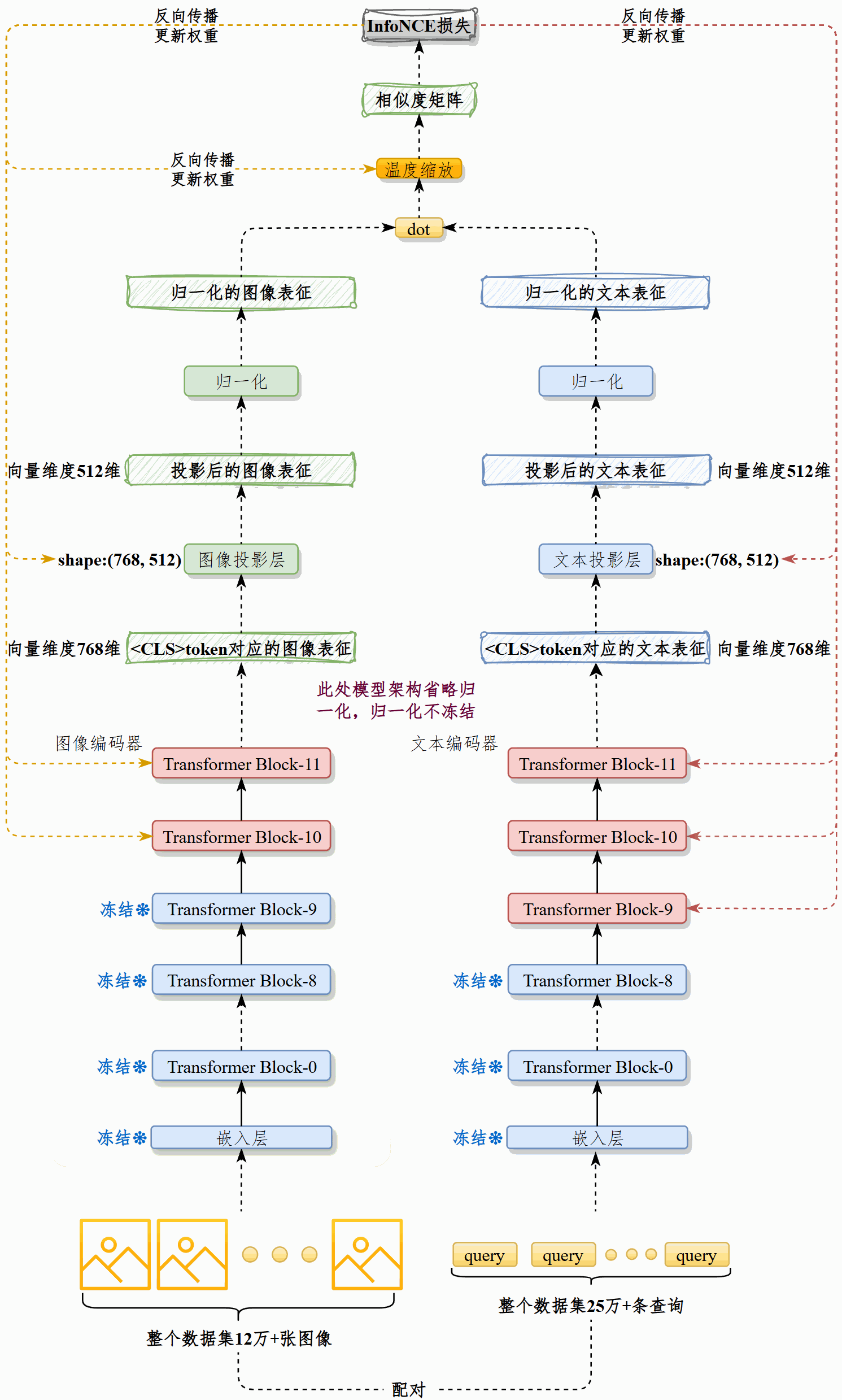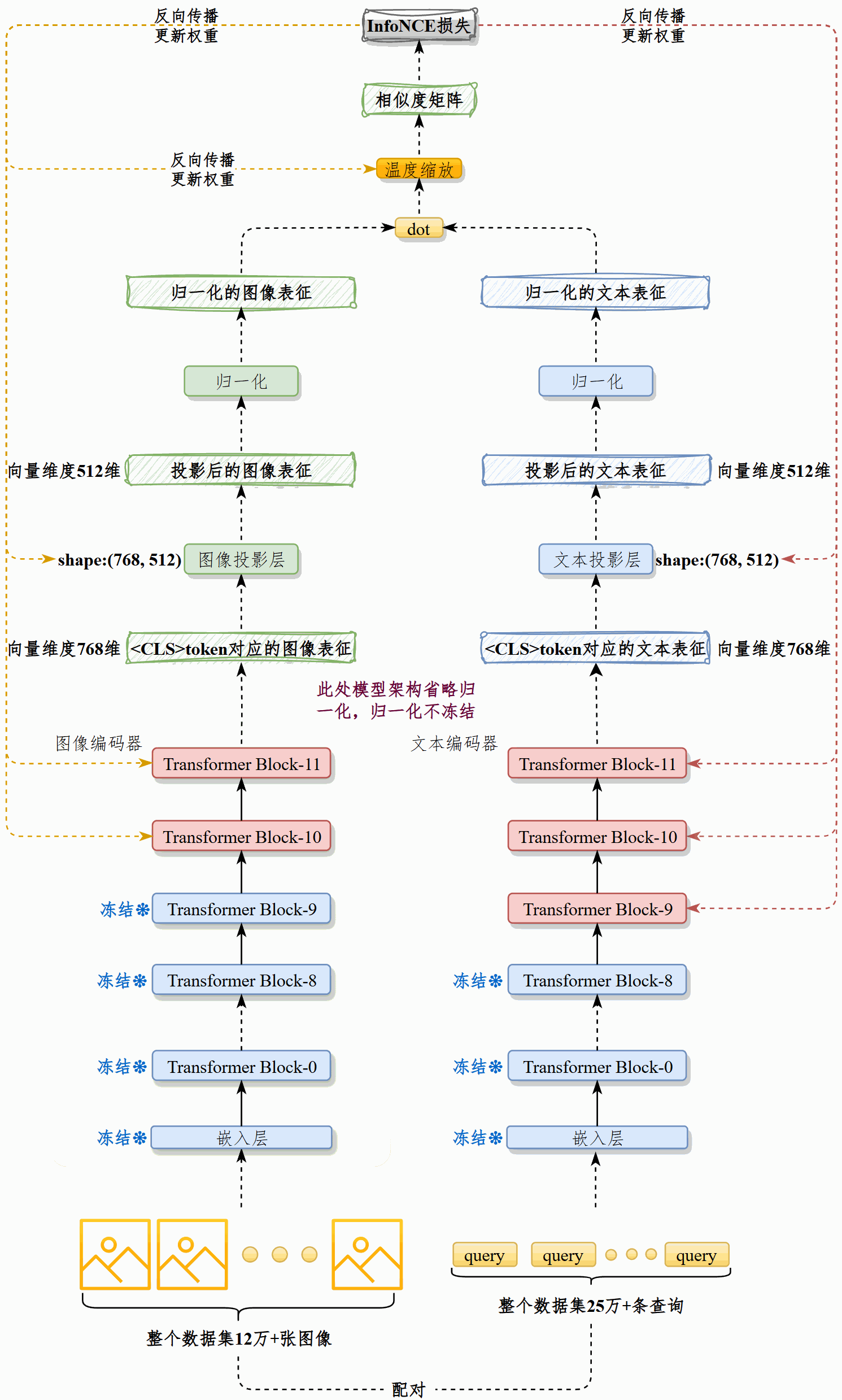
我们在现有预训练CLIP模型的基础上,在25万+图文对上续训,对齐电商场景下的图像和查询文本。然后将图像通过最佳CLIP模型的vision_model处理为图像表征,写入向量数据库Chroma。
用户查询到来时,将其通过最佳CLIP模型的text_model处理为文本表征,从Chroma中检索相似图像。
技术细节#
QCLIP模型选型#
基于Chinese CLIP模型:OFA-Sys/chinese-clip-vit-base-patch16实现。
该模型由vision_model和text_model以及各自的投影构成。vision_model接收3通道、尺寸224*224的图像,text_model接收原始文本,二者均输出维度为768的向量,然后通过各自的投影层处理为512维向量。
Q向量数据库选型#
选择Chroma作为向量数据库。
总结#
文搜图模块的功能是:根据用户输入的文本查询搜索相似商品。
首先,续训CLIP Chinese模型。#
首先对图像进行预处理,统一为RGB 3通道格式,尺寸为224*224。。#
经过CLIP预处理器处理后的图像和查询文本分别进入CLIP的vision_model和text_model,按照CLIP模型的标准过程进行前向传播、反向传播。#
并非所有权重都会更新。训练过程冻结图像和文本模型的嵌入层、冻结文本模型的前9个Transformer Block,解冻后3层,冻结图像模型的前10个Transformer Block,解冻后2层。解冻归一化权重、解冻投影层、解冻温度缩放权重。
在25万个图文对上训练,训练集和验证集按照9:1划分,批次大小96,每个epoch训练2346步,训练共30个epoch,约7万步。在前10%的步数应用线性预热,学习率从0达到最大值,经过剩余90%的步数学习率衰减至最大值的10%。应用范数为1.0的梯度裁剪。早停容忍度为5个epoch。#
采用AdamW优化器,采用分组学习率。
训练在【1张V100 32GB】上进行,显存占用在15GB左右,训练4个epoch,累计9384步之后验证损失达到最小,再经过5个epoch触发早停。训练时长约5小时。#
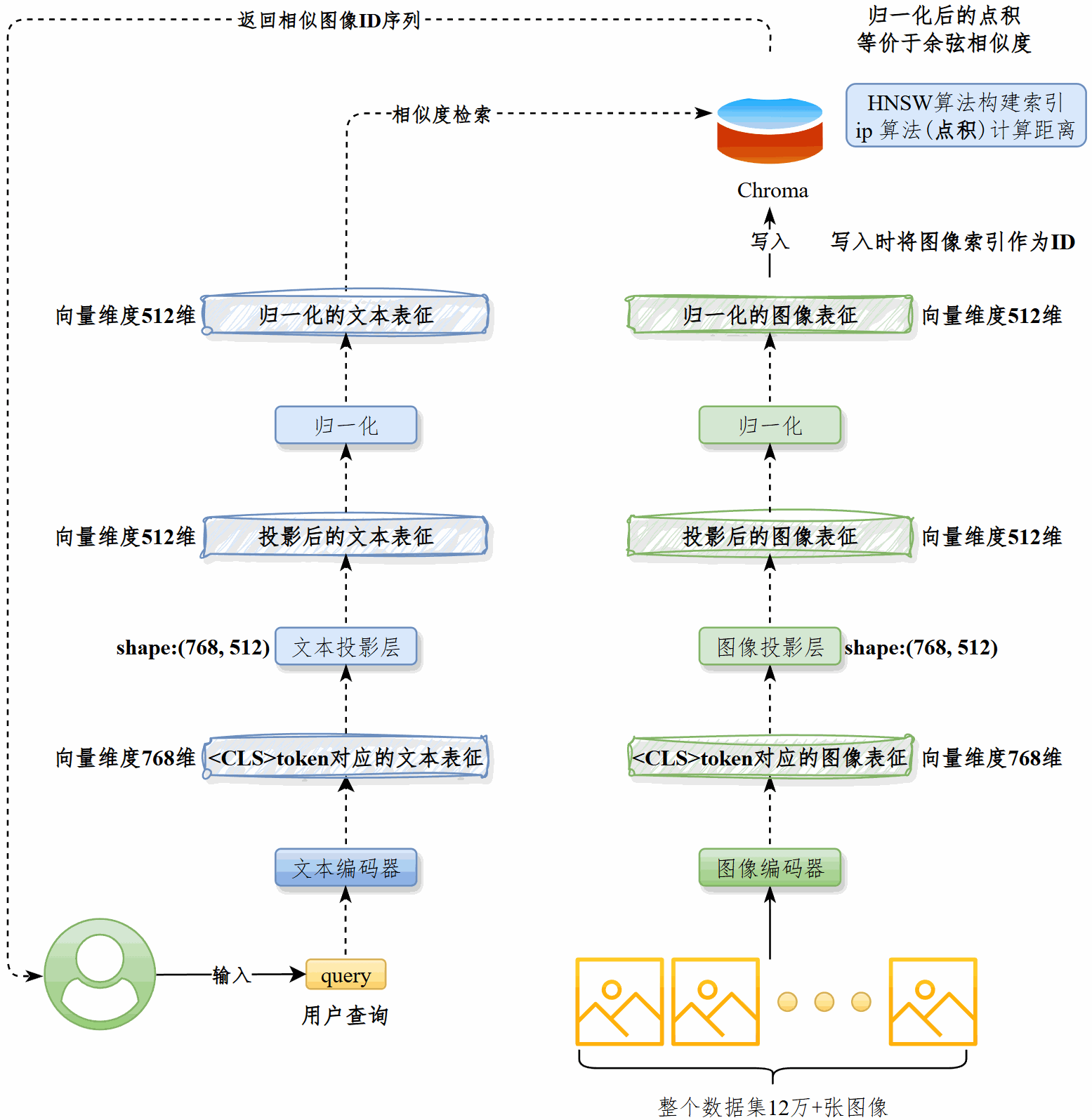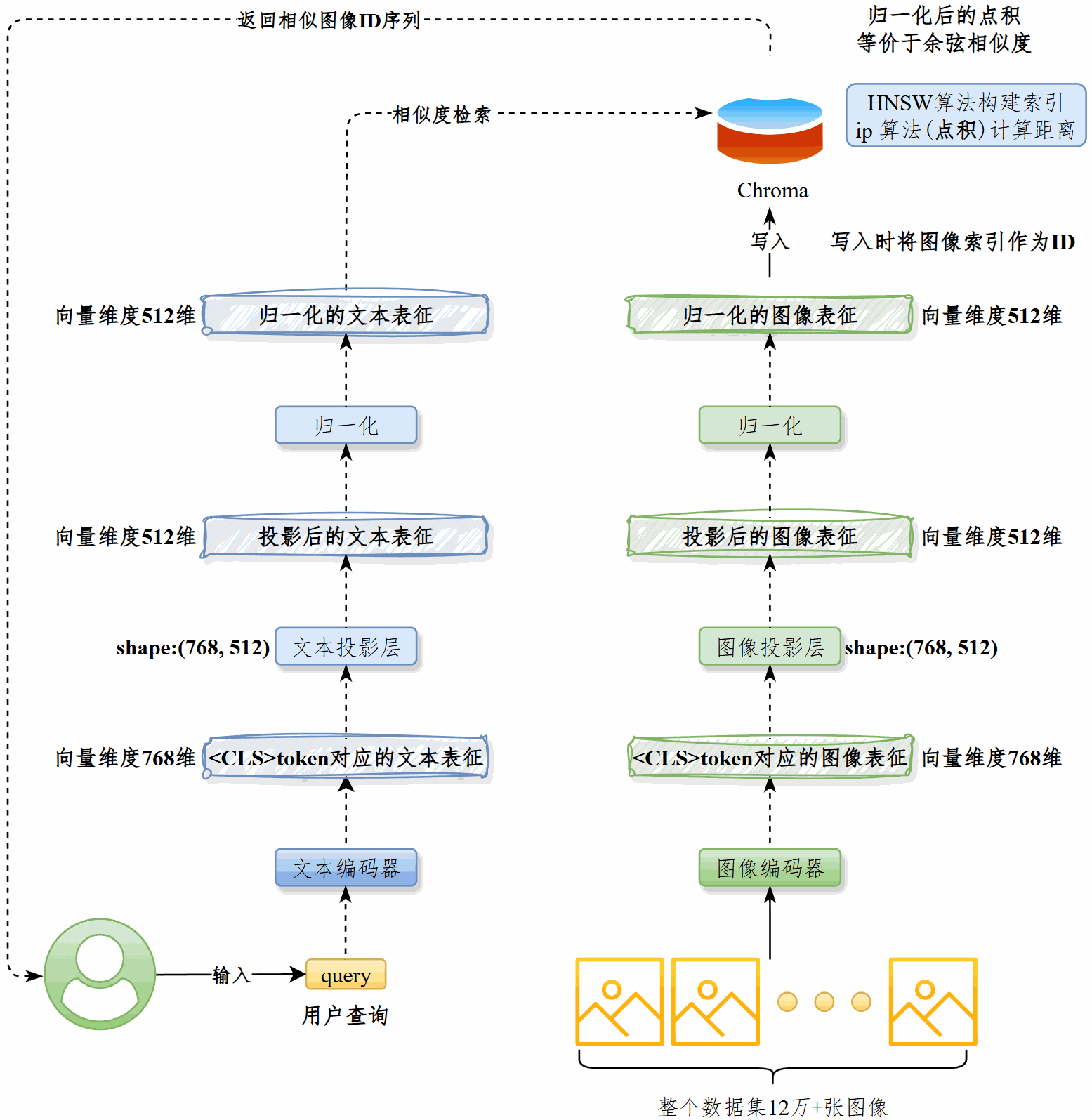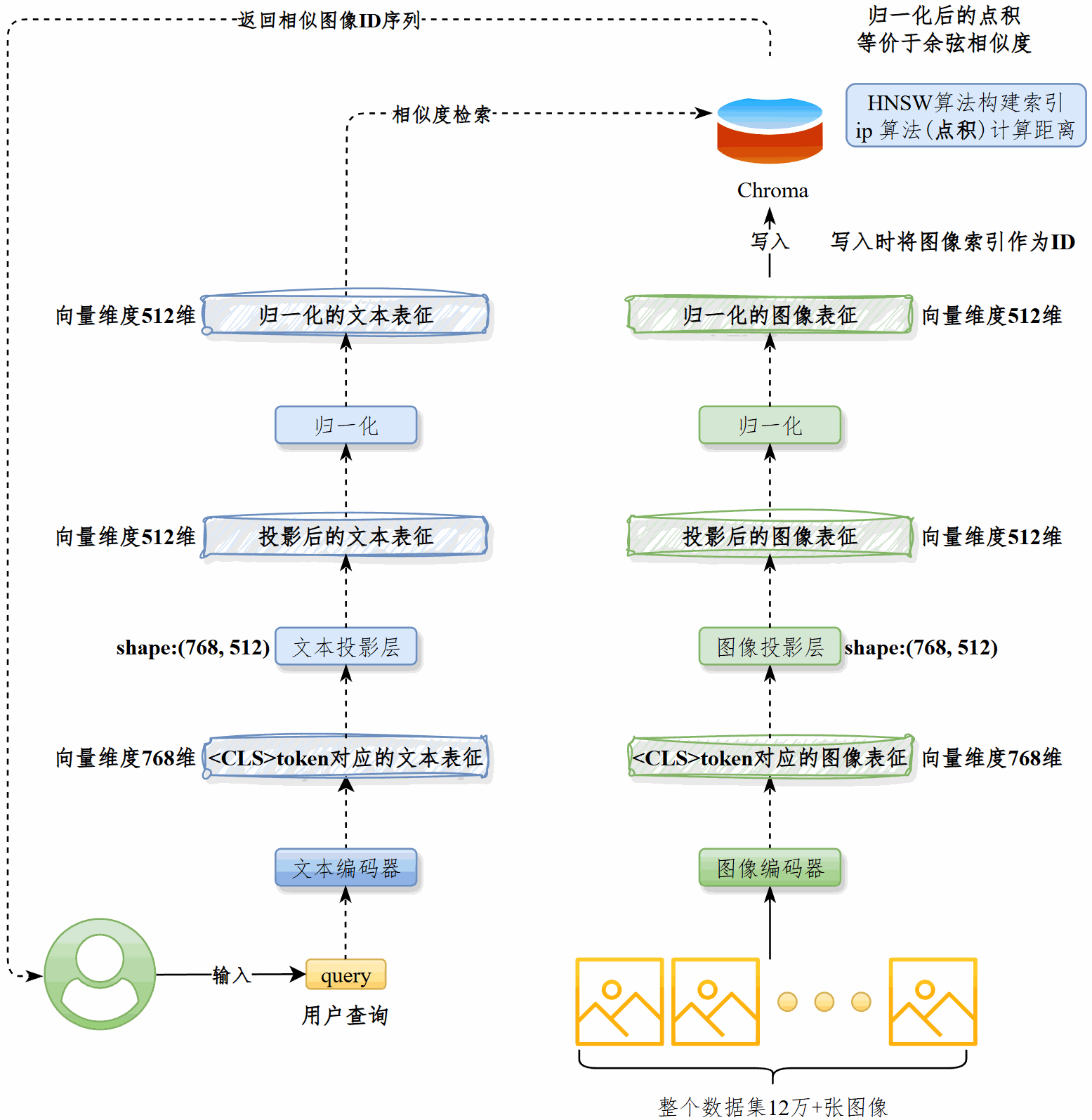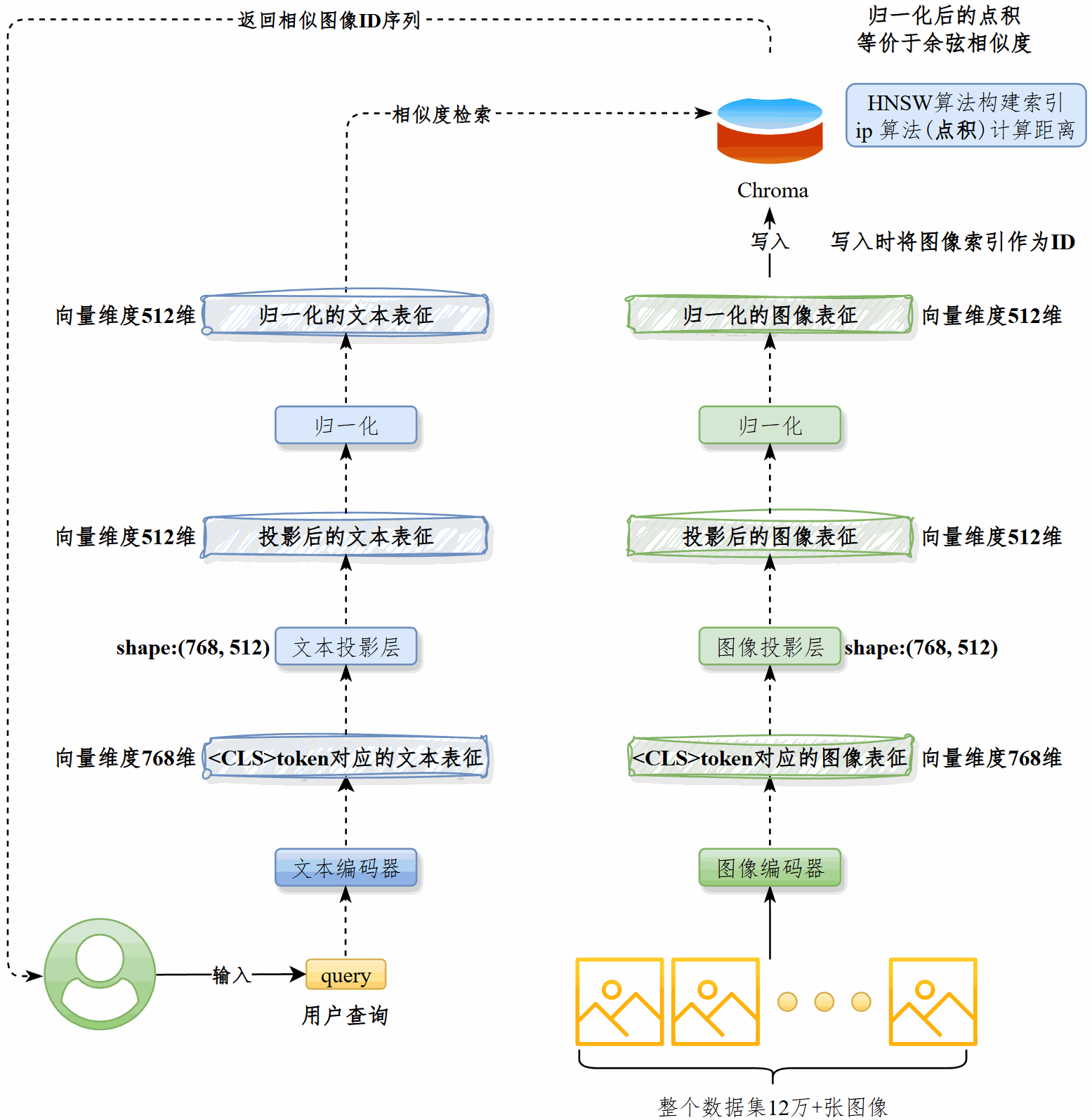
生成图像表征并入库#
用最优的vision_model将图像处理为512维的特征向量,归一化后写入Chroma。#
Chroma采用HNSW算法构建索引,ip算法(点积)计算距离。写入时将图像的唯一索引作为向量ID。#
查询相似图像#
用最佳的text_model将用户查询处理为512维的特征向量,归一化后从Chroma中检索相似图像,获得后者的ID列表,返还给用户。
总结-项目串讲#
Q训练逻辑#
串讲#
文生图模块的目标是根据文本查询相似图像。为实现这一目标,对CLIP Chinese模型进行了续训。
具体做法是:先将图像预处理为RGB三通道、尺寸224×224的图像。用CLIP的预处理器对图像和文本预处理,再分别送入vision_model和text_model做标准的前向、反向传播。在训练时我采取了部分参数冻结策略:冻结嵌入层,文本端只解冻最后3个 Transformer Block,视觉端解冻最后2层,同时解冻归一化、投影层以及温度缩放参数。
训练数据量是25万对图文,9:1划分训练/验证集,批大小96,共30个epoch,约7万步,使用AdamW分组学习率(投影层最高 3e-4,其余1.5e-5~3e-6),并对不同分组选择不同的AdamW衰减系数(Transformer和投影层0.02,其余为0.0),并结合线性预热、余弦衰减、梯度裁剪和早停机制。
在1张V100 32GB上训练,显存控制在15GB左右,实际跑了约4个epoch(9384步验证损失最低,再经过5个epoch触发早停),整体训练时长5小时左右,最终模型在检索效果上有明显提升。
关键超参数#
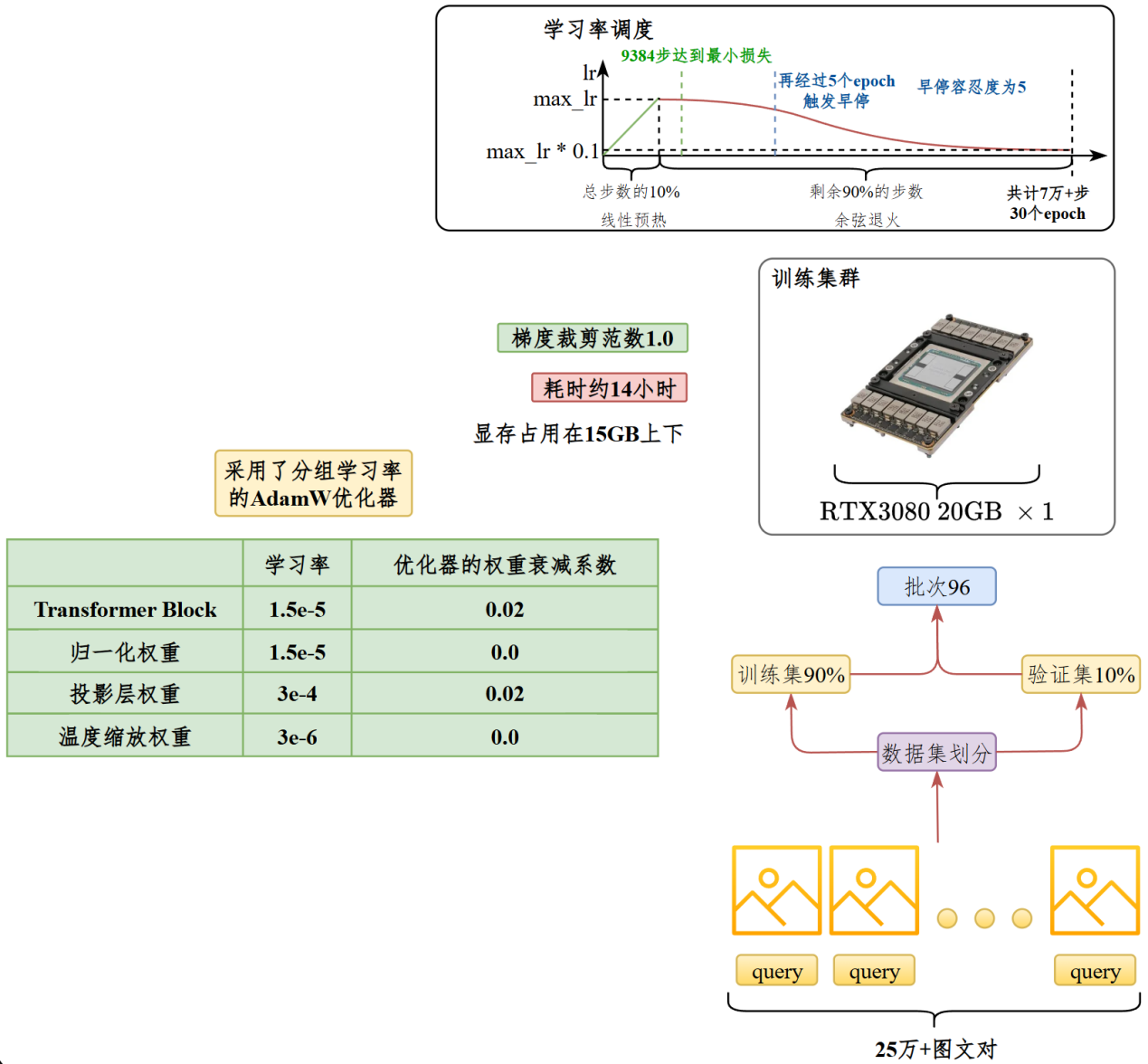
注意:企业生产环境一般不会用RTX3080 20GB这种魔改显卡,上图中的显卡是项目开发时的测试环境,面试时可以替换为正常企业级显卡即可。开销和效率接近。
Q检索流程#
串讲#
在图像检索部分,我做了两方面工作:首先,用优化后的vision_model将图像编码为512维特征向量,归一化后写入Chroma,并以唯一索引作为向量ID。
Chroma基于HNSW建立索引,使用点积(ip)来衡量相似度。
其次,在查询阶段,用户输入的文本会经由text_model转换成 512 维特征向量,归一化后从Chroma中检索最相似的图像,返回对应的ID列表,从而实现高效的文搜图功能。